引言
- Java核心思想的学习笔记
- 包含第一卷除swing章节,并包含第二卷的文件流部分
1 Java程序设计概述
1.2 Java“白皮书”的关键术语
- 11个关键术语:
- 简单性
- 面向对象
- 分布式
- 健壮性:
- Java的设计目标之一在于使得Java编写的程序具有多方面的可靠性
- Java和C++最大的不同在于Java采用的指针模型可以消除重写内存和损坏数据的可能性
- 安全性:
- Java代码不论来自哪里,都不能脱离沙箱
- 编译器生成一个体系结构中立的目标文件格式,这是一种编译过的代码,这些编译后的代码可以在许多处理器上运行
- 解释虚拟机指令肯定会比全速运行机器指令慢很多
- 即时编译:虚拟机的一个选项,可以将执行最频繁的字节码序列翻译成机器码
- 可移植性:
- 数据类型具有固定的大小
- 消除了代码移植时的问题
- 二进制数据以固定的格式进行存储和传输,消除了字节顺序的困扰
- 字符串是用标准的Unicode格式存储的
- 除了与用户界面有关的部分外,所有其他Java库都能很好地支持平台独立性。可以处理文件、正则表达式、XML、日期和时间、数据库、网络连接、线程等,而不用操心底层操作系统。不仅程序是可移植的,Java API往往也比原生API质量更高
- 解释型
- 高性能
- 多线程
- 动态性
3 Java的基本程序设计结构
3.1 一个简单的Java应用程序
- 关键字class:
- 关键字class后面紧跟类名,表明Java程序中的全部内容都包含在类中
- 类作为加载程序逻辑的容器,程序逻辑定义了应用程序的行为。
- 源代码的文件名必须与公共类的名字相同,并用.java作为扩展名
- 运行已编译的程序时,JVM将从指定类中的main方法开始执行,main方法必须声明为public,且必须为静态static的
- Java的类与C++的类很相似,但Java中的所有函数都属于某个类的方法。因此,Java中的main方法必须有一个外壳类
3.3 数据结构
- Java是一种强类型语言,意味着必须为每一个变量声明一种类型
- 8种基本类型:
- 另:Java有一个能够表示任意精度的算术包,通常称为“大数值”(为Java对象) 跳转至大数据类
3.3.1 整型
| 类型 | 存储需求(字节) | 取值范围 |
|---|---|---|
| int | 4 | -2147483~2147483647(正好超过20亿) |
| short | 2 | -32768~32767 |
| long | 8 | -9223372036854775808~9223372036854775807 |
| byte | 1 | -128~127 |
- 在Java中,整型的范围与运行Java代码的机器无关
- Java没有任何无符号(unsigned)形式的int、long、short或byte类型
- 长整型数值有一个后缀L或l
- 十六进制数值有一个前缀0x或0X
- 八进制有一个前缀0
- 加上前缀0b或0B就可以写二进制数
- 可以为数字字面量加下划线(如用1_000_000(或0b1111_0100_0010_0100_0000)表示一百万)
3.3.2 浮点类型
| 类型 | 存储需求(字节) | 取值范围 |
|---|---|---|
| float | 4 | ±3.40282347E+38F(有效位数6~7位) |
| double | 8 | ±1.79769313486231570+308F(有效位数15位) |
-
浮点数值存在舍入误差
- 若不允许任何舍入误差,就应该使用BigDecimal类 跳转至大数据类
-
double(绝大多数程序使用)表示这种类型的数值精度是float类型的两倍。
- float类型的数值有一个后缀F或f
- 没有后缀F的浮点数值,默认为double类型
-
使用十六进制表示浮点数值
- 例如,0.125=1.0*2^(-3)可以表示成0x1.0p-3(尾数十六进制,指数十进制)
- 在十六进制表示法中,使用p表示指数,而不是e
1 | //表示溢出和出错情况的三个特殊的浮点数值: |
3.3.3 char类型
- 转义序列\u可以出现在加引号的字符常量或字符串之外(而其他所有转义序列不可以)
| 转义序列 | 名称 | unicode值 |
|---|---|---|
| \b | 退格 | \u0008 |
| \t | 制表 | \u0009 |
| \n | 换行 | \u000a |
| \r | 回车 | \u000d |
| " | 双引号 | \u0022 |
| ' | 单引号 | \u0027 |
| \ | 反斜杠 | \u005c |
- 一定要当心注释中的\u
3.3.4 Unicode和char类型
-
在Java中,char类型描述了UTF-16编码中的一个代码单元
-
强烈建议不要在程序中使用char类型,除非确实需要处理UTF-16代码单元
-
设计Unicode编码的目的
- 对于任意给定的代码值,在不同的编码方案下有可能对应不同的字母
- 采用大字符集的语言其编码长度有可能不同。
-
码点是指与一个编码表中的某个字符对应的代码值。
- 在Unicode标准中,码点采用十六进制书写,并加上前缀U+
- Unicode的码点可以分成17个代码级别
- 第一个代码级别称为基本的多语言级别(basic multilingual plane),码点从U+0000到U+FFFF,其中包括经典的Unicode代码
- 其余的16个级别码点从U+10000到U+10FFFF,其中包括一些辅助字符(supplementary character)。
-
UTF-16编码采用不同长度的编码表示所有Unicode码点
-
在基本的多语言级别中,每个字符用16位表示,通常被称为代码单元
-
而辅助字符采用一对连续的代码单元进行编码
-
这样构成的编码值落入基本的多语言级别中空闲的2048字节内,通常被称为替代区域
-
可以从中迅速地知道一个代码单元是一个字符的编码,还是一个辅助字符的第一或第二部分。
3.3.5 boolean类型
- boolean类型有两个值:false,true 用来判定逻辑条件
- 整型值和布尔值之间不能进行相互转换
3.4 变量
- 声明变量时,变量的类型位于变量名之前
- 在Java中,不区分变量的声明与定义
- 声明一个变量之后,必须用赋值语句对变量进行显式初始化,不要使用未初始化的变量
3.4.2 常量
- 利用关键字final指示常量,常量名一般都是全大写
- 关键字final表示这个变量只能被赋值一次。一旦被赋值之后,就不能够再更改了
- 类常量:某个常量可以在一个类中的多个方法中使用。
- 使用关键字static final设置一个类常量
- 类常量的定义位于main方法的外部
- 同一个类的其他方法中也可以使用这个常量
- 一个常量被声明为public,其他类的方法也可以使用这个常量
3.5 运算符
除号/:
-
两个操作数都是整数时,表示整数除法
-
否则,表示浮点除法
- 整数被0除将产生一个异常
- 浮点数被0除将会得到无穷大或NaN结果
-
默认情况下,虚拟机设计者允许对中间计算结果采用扩展的精度
-
对于使用strictfp关键字标记的方法必须使用严格的浮点计算来生成可再生的结果
- 如果将一个类标记为strictfp,这个类中的所有方法都要使用严格的浮点计算
- 采用默认的方式不会产生溢出,而采用严格的计算有可能产生溢出
3.5.1 数学函数与常量
1 | double x = 4; |
Math类提供的各种各样的数学函数:
-
平方根 sqrt
-
幂 pow
-
取余 floorMod
-
三角函数
- Math.sin
- Math.cos
- Math.tan
- Math.atan
- Math.atan2
-
自然对数运算
- Math.exp
- Math.log
- Mtah.log10
-
结果比运行速度更重要,应该使用StrictMath类
-
println方法和sqrt方法存在微小的差异
- println方法处理System.out对象
- Math类中的sqrt方法为静态方法,处理的不是对象
3.5.2 数值类型之间的类型转换

6个实心箭头,表示无信息丢失的转换;3个虚箭头,表示可能有精度损失的转换
3.5.3 强制类型转换
1 | double x = 9.997; |
- 将一个数值从一种类型强制转换为另一种类型,而又超出了目标类型的表示范围,结果就会截断成一个完全不同的值
- 不要在boolean类型与任何数值类型之间进行强制类型转换
- 极少数的情况才需要将布尔类型转换为数值类型,使用条件表达式 b?1:0
- 对浮点数进行舍入运算,使用Math.round方法
3.5.5 自增与自减运算符
后缀 i++ : 表示先使用当前值,在完成加一
前缀 ++i : 表示先完成加一,在使用变量值
3.5.6 关系和boolean变量
- == 检测相等性
- \ != 检测不相等
- && || ! 与或非运算符
- 三元操作符 ? :
3.5.7 位运算符
- & | ^ ~
- >> 左移运算符
- << 右移运算符
- >>> 左移 使用0填充最高位
- <<< 右移 使用0填充最低位
- 移位运算符的右操作数要完成模32的运算(除非左操作数是long类型
3.5.9 枚举类型
- 需要定义枚举类,参考枚举类
1 | // 可以自定义枚举类型 |
3.6 字符串
Java没有内置的字符串类型,而是在标准Java类库中提供了一个预定义类String
3.6.1 子串
1 | String greeting = "Hello"; |
3.6.2 拼接
- 允许使用 + 进行拼接两个字符串
- 当将一个字符串与一个非字符串的值进行拼接时,后者被转换成字符串
- 把多个字符串拼接并用定界符分隔,可以使用静态join方法
1 | String all = String.join("/" , "S", "M", "L", "XL"); |
3.6.3 不可变字符串
- String类没有提供修改字符串的方法(Java文档中将String类对象称为不可变字符串)
- 修改步骤:首先提取需要的字符,然后再拼接上替换的字符串
- 不可变字符串的优点:编译器可以让字符串共享
- 各种字符串存放在公共的存储池中
- 字符串变量指向存储池中相应的位置
- 如果复制一个字符串变量,原始字符串与复制的字符串共享相同的字符
- Java字符串大致类似于char*指针
3.6.4 检测字符串是否相等
1 | // 使用equals方法检测字符串是否相等(相等则返回true,否则返回false) |
- 一定不要使用==运算符检测两个字符串是否相等
- 该运算符只能够确定两个字符串是否放置在同一个位置上
- 若虚拟机始终将相同的字符串共享,就可以使用==运算符检测是否相等
- 但实际上只有字符串常量是共享的,而+或substring等操作产生的结果并不是共享的
3.6.5 空串和Null串
1 | // 空串是长度为0的字符串(一个Java对象,有自己的串长度(0)和内容(空)) |
3.6.6 码点与代码单元
- char数据类型是一个采用UTF-16编码表示Unicode码点的代码单元
- length方法将返回采用UTF-16编码表示的给定字符串所需要的代码单元数量
- 调用s.charAt(n)将返回位置n的代码单元,n介于0~s.length()-1之间
- 使用codePoints方法,它会生成一个int值的“流”,每个int值对应一个码点
- 将码点数组转换为字符串,可以使用构造函数
1 | //要想得到实际的长度,即码点数量,可以调用 |
3.6.9 构建字符串
1 | StringBulider builder = new StringBulider(); //构造空的字符串构造器 |
- 使用StringBuilder类适用于由较短的字符串构造较短的字符串
- 避免每次连接字符串,都会构建一个新的String对象,既耗时,又浪费空间
- StringBuilder类将所有的字符串在一个单线程中编辑
- StringBuffer效率较低,但可以使用多线程方式执行添加或删除字符串的操作
3.7 输入与输出
3.7.1 读取输入
- 读取“标准输入流”操作
1 | //使用Scanner类实现(输入是可见的) |
- 返回的密码存放在一维字符数组中
- 在对密码进行处理之后,应该马上用一个填充值覆盖数组元素.
- 采用Console对象处理输入不如采用Scanner方便(每次只能读取一行输入,而没有能够读取一个单词或一个数值的方法)
3.7.2 格式化输出
-
每一个以%字符开始的格式说明符都用相应的参数替换。
- 用于print的转换符:
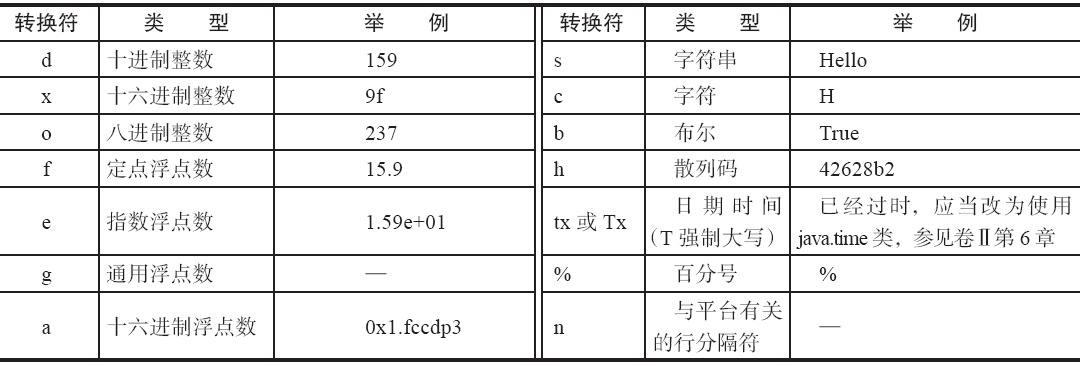
- 用于print的标志:

- 用于print的转换符:
-
可以使用s转换符格式化任意的对象
-
对于任意实现了Formattable接口的对象都将调用formatTo方法
-
否则将调用toString方法,它可以将对象转换为字符串
-
可以使用静态的String.format方法创建一个格式化的字符串,而不打印输出:
1 | String message = String.format("Hello, %s. Next year, you'll be %d", name, age); |
日期和时间:

- 可以采用一个格式化的字符串指出要被格式化的参数索引
- 索引必须紧跟在%后面,并以$终止。
1 | System.out.printf("%1$s %2$tB %2$te, %2$tY", "Due date;",new Date()); |
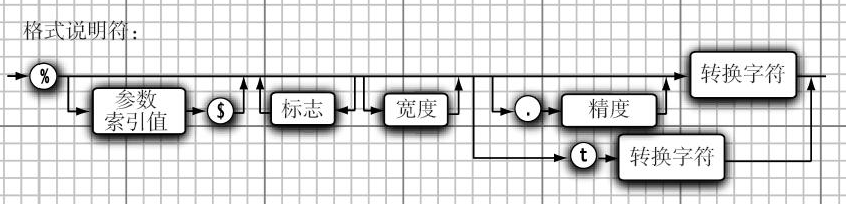
3.7.3 文件输入与输出
1 | Scanner in = new Scanner(Paths.get("myfile.txt"),"UTF-8"); |
- 如果用一个不存在的文件构造一个Scanner,或者用一个不能被创建的文件名构造一个PrintWriter,那么就会发生异常
1 |
|
3.8 控制流程
- Java的控制流程结构没有goto语句,但break语句可以带标签,可以利用它实现从内层循环跳出的目的
- 不能在嵌套的两个块中声明同名的变量
3.8.4 确定循环
- 在循环中,检测两个浮点数是否相等需要格外小心
- 由于舍入的误差,最终可能得不到精确值
- 例如,因为0.1无法精确地用二进制表示,所以,x将从9.99999999999998跳到10.09999999999998
- 如果在for语句内部定义一个变量,这个变量就不能在循环体之外使用
- 如果希望在for循环体之外使用循环计数器的最终值,就要确保这个变量在循环语句的前面且在外部声明
- 可以在各自独立的不同for循环中定义同名的变量。
3.8.5 多重选择:switch语句
- switch语句将从与选项值相匹配的case标签处开始执行直到遇到break语句,或者执行到switch语句的结束处为止
- 有可能触发多个case分支。如果在case分支语句的末尾没有break语句,那么就会接着执行下一个case分支语句
- 编译代码时可以考虑加上==-Xlint:fallthrough选项,如果某个分支最后缺少一个break语句,编译器就会给出一个警告消息==
- 当在switch语句中使用枚举常量时,不必在每个标签中指明枚举名,可以由switch的表达式值确定
1 | Size SZ =...; |
3.8.6 中断控制流程语句
- 标签必须放在希望跳出的最外层循环之前,并且必须紧跟一个冒号
- continue语句越过了当前循环体的剩余部分,立刻跳到循环首部
- continue语句用于for循环中,就可以跳到for循环的“更新”部分
3.9 大数值
- java.math包中的两个很有用的类:BigInteger和BigDecimal
- 可以处理包含任意长度数字序列的数值
- BigInteger类实现了任意精度的整数运算
- BigDecimal实现了任意精度的浮点数运算。
1 | //静态的valueOf方法可以将普通的数值转换为大数值 |
3.10 数组
- 声明数组变量时,需要指出数组类型(数据元素类型紧跟[])和数组变量的名字
1 | //使用new运算符创建数组 |
- 一旦创建了数组,就不能再改变它的大小(尽管可以改变每一个数组元素)
- 需要在运行过程中扩展数组的大小,使用数组列表(array list)
3.10.1 for each循环
- for each循环可以用来依次处理数组中的每个元素而不必指定下标值
1 | //collection集合表达式必须是一个数组或者是一个实现了Iterable接口的类对象 |
- 调用Arrays.toString(a),返回一个包含数组元素的字符串,可以打印数组中的所有值
3.10.2 数组初始化以及匿名数组
1 | //创建数组对象并同时赋予初始值的简化书写(不需要使用new) |
3.10.3 数组拷贝
- 在Java中,允许将一个数组变量拷贝给另一个数组变量,两个变量将引用同一个数组
- 将一个数组的所有值拷贝到一个新的数组中去,就要使用Arrays类的copyOf方法
1 | int[] luckyNumbers = smallPrimes; //数组拷贝 |
3.10.4 命令行参数
- 每一个Java应用程序都有一个带String arg[]参数的main方法
- 这个参数表明main方法将接收一个字符串数组,也就是命令行参数。
3.10.5 数组排序
- 对数值型数组进行排序,使用Arrays类中的sort方法
3.10.6 多维数组
- 与一维数组一样,在调用new对多维数组进行初始化之前不能使用它
- 若知道数组元素,就可以不调用new,而直接使用简化的书写形式对多维数组进行初始化
1 | balances = new double[NYEARS] [NRATES]; |
- 快速地打印一个二维数组的数据元素列表Arrays.deepToString方法
- for each循环语句处理二维数组的每一个元素(需要使用两个嵌套的循环)
- for each循环语句对二维数组按照行(一维数组)处理
3.10.7 不规则数组
1 | double[] temp = balances[i]; //数组两行交换 |
4 对象与类
4.1.1 类
- 封装是与对象有关的一个重要概念
- 从形式上看,封装不过是将数据和行为组合在一个包中,并对对象的使用者隐藏了数据的实现方式
- 对象中的数据称为实例域,操纵数据的过程称为方法
- 对于每个特定的类实例(对象)都有一组特定的实例域值。这些值的集合就是这个对象的当前状态
- 无论何时,只要向对象发送一个消息,它的状态就有可能发生改变。
4.1.2 对象
- 对象状态的改变必须通过调用方法实现
- 如果不经过方法调用就可以改变对象状态,只能说明封装性遭到了破坏
- 需要注意,作为一个类的实例,每个对象的标识永远是不同的,状态常常也存在着差异
4.1.4 类之间的关系
- 依赖:如果一个类的方法操纵另一个类的对象,我们就说一个类依赖于另一个类。
- 聚合:意味着类A的对象包含类B的对象。
- 继承:是一种用于表示特殊与一般关系的。
4.2 使用预定类
- Math类只封装了功能,它不需要也不必隐藏数据
- 由于没有数据,因此也不必担心生成对象以及初始化实例域
4.2.1 对象与对象变量
- 在Java程序中,使用构造器构造新实例
- 构造器是一种特殊的方法,用来构造并初始化对象
- 构造器的名字应该与类名相同
- 在构造器前面加上new操作符,new操作符的返回值是一个引用
- 定义对象变量后必须初始化对象变量,所有的Java对象都存储在堆中
- 一个对象变量并没有实际包含一个对象,而仅仅引用一个对象
- 任何对象变量的值都是对存储在另外一个地方的一个对象的引用
- 如果将一个方法应用于一个值为null的对象上,那么就会产生运行时错误
- 局部变量不会自动地初始化为null,而必须通过调用new或将它们设置为null进行初始化
- 当一个对象包含另一个对象变量时,这个变量依然包含着指向另一个堆对象的指针
- 在Java中,必须使用clone方法获得对象的完整拷贝
1 | Date deadline; //定义对象变量 |
4.2.2 Java类库中的LocalDate类
- Date类:表示时间点
- LocalDate类:日历表示法
- 不要使用构造器来构造LocalDate类的对象
- 使用静态工厂方法代表调用构造器
1 | LocalDate.now(); //构造新对象,表示构造这个对象时的日期 |
4.2.3 更改器方法与访问器方法
- 访问器方法:只访问对象而不修改对象的方法,如LocalDate.getYear()
- 更改器方法:访问对象并修改对象的方法,如GregorianCalendar.add()
- 在C++中,带有const后缀的方法是访问器方法;默认为更改器方法
4.3 用户自定义类
在Java中,最简单的类定义形式:
1 | class ClassName |
4.3.2 多个源文件的使用
- 使用通配符调用Java编译器:java Employee*.java
- 或编译 java EmployeeTest.java
4.3.3 剖析Employee类
- 关键字private确保只有Employee类自身的方法能够访问这些实例域,而其他类的方法不能够读写这些域
- 可以用public标记实例域(一种极为不提倡的做法)
- public数据域允许程序中的任何方法对其进行读取和修改(完全破坏了封装)
4.3.4 从构造器开始
- 构造器与类同名,可以拥有0个、1个或多个参数,没有返回值
- 构造器总是伴随着new操作符的执行被调用,而不能对一个已经存在的对象调用构造器来达到重新设置实例域的目的
- 每个类可以有一个以上的构造器
- 不要在构造器中定义与实例域重名的局部变量
- 必须注意在所有的方法中不要命名与实例域同名的变量
4.3.5 隐式参数与显式参数
- 在每一个方法中,关键字this表示隐式参数
- 在Java中,所有的方法都必须在类的内部定义,但并不表示它们是内联方法
4.3.6 封装的优点
- 需要获得或设置实例域的值,应该提供下面三项内容:
- 一个私有的数据域
- 一个公有的域访问器方法
- 一个公有的域更改器方法
- 更改器方法可以执行错误检查,然而直接对域进行赋值将不会进行这些处理
- 注意不要编写返回引用可变对象的访问器方法
- 如果需要返回一个可变对象的引用,应该首先对它进行克隆(clone)
- 对象clone是指存放在另一个位置上的对象副本。
- Date类存在更改器方法setTime,因此Date对象是可变的,破坏了封装性
- 如需要使用Date类,返回时返回Date类的clone对象(使用clone方法)
- 如果需要返回一个可变对象的引用,应该首先对它进行克隆(clone)
4.3.7 基于类的访问权限
- 一个方法可以访问所属类的所有对象的私有数据
4.3.8 私有方法
- 在Java中,为了实现一个私有的方法,只需将关键字public改为private即可
- 对于私有方法,如果改用其他方法实现相应的操作,则不必保留原有的方法
4.3.9 final实例域
- 将实例域定义为final,构建对象时必须初始化这样的域
- 即必须确保在每一个构造器执行之后,这个域的值被设置,并且值不能改变
- final修饰符大都应用于基本类型域或不可变类的域
- 对于可变的类,使用final修饰符表示对象引用不会指向其他对象,但对象是可以改变的
1 | class Employee { |
4.4 静态域与静态方法
4.4.1 静态域
- 如果将域定义为static,每个类中只有一个这样的域
- 每一个对象对于所有的实例域却都有自己的一份拷贝
- 静态域属于类而不属于任何独立的对象,所有该类的对象共享一个静态域
4.4.2 静态常量
- 在常量的声明中,添加关键词static表示静态常量
- 如Math类,若关键字static被省略,PI就变成了Math类的一个实例域
- 需要通过Math类的对象访问PI,并且每一个Math对象都有它自己的一份PI拷贝
- 由于每个类对象都可以对公有域进行修改,所以,最好不要将域设计为public.然而,公有常量(即final域)却没问题
- 静态常量System.out,out被声明为final,故不允许再将其他打印流赋给它
- System类有一个setOut方法可以将System.out设置为不同的流
- ==为什么这个方法可以修改final变量的值?
- 原因在于,setOut方法是一个本地方法,而不是用Java语言实现的==,可以绕过Java语言的存取控制机制
4.4.3 静态方法
- 静态方法是一种不能向对象实施操作的方法
- 静态方法是没有this参数的方法(在一个非静态的方法中,this参数表示这个方法的隐式参数
- 建议使用类名,而不是对象来调用静态方法,可以使用对象名进行调用静态方法
在下面两种情况下使用静态方法:
- 一个方法不需要访问对象状态,其所需参数都是通过显式参数提供(例如:Math.pow)。
- 一个方法只需要访问类的静态域(例如:Employee.getNextId)
4.4.4 工厂方法
- 工厂方法用于生成不同风格的格式化对象(静态方法的另一种用途[静态工厂方法])
- 为什么NumberFormat类不利用构造器完成构建对象操作
- 原因:
- 无法命名构造器。构造器的名字必须与类名相同。但是,这里希望将得到的货币实例和百分比实例采用不用的名字
- 当使用构造器时,无法改变所构造的对象类型。而工厂方法将返回一个DecimalFormat类对象,这是NumberFormat的子类
4.4.5 main方法
- main方法不对任何对象进行操作
- 事实上,在启动程序时还没有任何一个对象。静态的main方法将执行并创建程序所需要的对象。
- 每一个类可以有一个main方法(常用于对类进行单元测试)
4.5 方法参数
- Java程序设计语言总是采用按值调用
- 方法得到的是所有参数值的一个拷贝,方法不能修改传递给它的任何参数变量的内容
- 方法可以通过对象引用的拷贝修改所引用的对象状态
总结一下Java中方法参数的使用情况:
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)
- 一个方法可以改变一个对象参数的状态
- 一个方法不能让对象参数引用一个新的对象
4.6 对象构造
4.6.1 重载
- 如果多个方法有相同的名字、不同的参数,便产生了重载
- 重载解析:编译器必须挑选出具体执行哪个方法,它通过用各个方法给出的参数类型与特定方法调用所使用的值类型进行匹配来挑选出相应的方法;如果编译器找不到匹配的参数,就会产生编译时错误
- Java允许重载任何方法(包括构造器方法)
- 方法的签名:方法名以及参数类型
4.6.2 默认域初始化
- 如果在构造器中没有显式地给域赋予初值,那么就会被自动地赋为默认值
- 数值为0
- 布尔值为false
- 对象引用为null
4.6.3 无参数的构造器
- 对象由无参数构造函数创建时,其状态会设置为适当的默认值
- 如果类提供了至少一个构造器,但是没有提供无参数构造器,在构造对象时必须提供参数
- 仅当类没有提供任何构造器的时候,系统才会提供一个默认的构造器
4.6.4 显式域初始化
- 可以在类定义中,直接将一个值赋给任何域
- 初始值不一定是常量值
4.6.5 参数名
- 参数变量用同样的名字将实例域屏蔽起来
- 例如,如果将参数命名为salary,salary将引用这个参数,而不是实例域
- 但是,可以采用this.salary的形式访问实例域
- this指示隐式参数,也就是所构造的对象
4.6.6 调用另一个构造器
- 如果构造器的第一个语句形如this(…),这个构造器将调用同一个类的另一个构造器。
1 | public Employee (double s) |
4.6.7 初始化块
初始化数据块的方法:
- 在构造器中设置值
- 在声明中赋值
- 初始化代码块:只要构造类的对象,这些块就会执行
1 | class Employee |
- 通常会直接将初始化代码放在构造器中
- 调用构造器的具体处理步骤:
- 所有数据域被初始化为默认值(0、false或null)
- 按照在类声明中出现的次序,依次执行所有域初始化语句和初始化块
- 如果构造器第一行调用了第二个构造器,则执行第二个构造器主体
- 执行这个构造器的主体
4.6.8 对象析构与finalize方法
- 由于Java有自动的垃圾回收器,不需要人工回收内存,所以Java不支持析构器
- 可以为任何一个类添加finalize方法。finalize方法将在垃圾回收器清除对象之前调用。在实际应用中,不要依赖于使用finalize方法回收任何短缺的资源
- 有个名为System.runFinalizersOnExit(true)的方法能够确保finalizer方法在Java关闭前被调用。不过,这个方法并不安全,也不鼓励使用
- 有一种代替的方法是使用方法Runtime.addShutdownHook添加“关闭钩”(shutdown hook)
- 对象用完时,可以应用一个close方法来完成相应的清理操作
4.7 包
- 使用包的主要原因是确保类名的唯一性
- 一个类可以使用所属包中的所有类,以及其他包中的公有类
- 访问方法
- 在每个类名之前添加完整的包名
- 使用import语句:import语句应该位于源文件的顶部(但位于package语句的后面)
- import语句不仅可以导入类,还可以导入静态方法和静态域
1 | //要想将一个类放入包中,就必须将包的名字放在源文件的开头,包中定义类的代码之前 |
- 编译器对文件(带有文件分隔符和扩展名.java的文件)进行操作
- 而Java解释器加载类(带有.分隔符)
4.8 类路径
- 类存储在文件系统的子目录中
- 类的路径必须与包名匹配
- 类文件也可以存储在JAR(Java归档)文件中
- 在一个JAR文件中,可以包含多个压缩形式的类文件和子目录,这样既可以节省又可以改善性能
- 在程序中用到第三方(third-party)的库文件时,通常会给出一个或多个需要包含的JAR文件。
- 为了使类能够被多个程序共享,需要做到下面几点
- 把类放到一个目录中,需要注意,这个目录是包树状结构的基目录
- 如果希望将com.horstmann.corejava.Employee类添加到其中,这个Employee.class类文件就必须位于子目录/home/user/classdir/com/horstmann/corejava中
- 将JAR文件放在一个目录中
- 设置类路径(类路径是所有包含类文件的路径的集合)
- 把类放到一个目录中,需要注意,这个目录是包树状结构的基目录
- 最好采用-classpath(或-cp)选项指定类路径
4.9 文档注释
- javadoc实用程序从下面几个特性中抽取信息,并编写注释
- 包
- 公有类与接口
- 公有的和受保护的构造器及方法
- 公有的和受保护的域
- 注释应该放置在所描述特性的前面,以/**开始,并以*/结束
- 标记由@开始
- 用于强调的<em>…</em>
- 用于着重强调的<strong>…</strong>以及包含图像的<img…>
- 不过,一定不要使用<h1>或<hr>,因为它们会与文档的格式产生冲突;若要键入等宽代码,需使用{@code…}
- 如果文档中有到其他文件的链接,就应该将这些文件放到子目录doc-files中
- javadoc实用程序将从源目录拷贝这些目录及其中的文件到文档目录中。在链接中需要使用doc-files目录,例如:<img src=“doc-files/uml.png”alt=“UML diagram”>
4.9.3 方法注释
- 每一个方法注释必须放在所描述的方法之前
- 除了通用标记之外,还可以使用下面的标记:
- @param变量描述:这个标记将对当前方法的“param”(参数)部分添加一个条目。这个描述可以占据多行,并可以使用HTML标记。一个方法的所有@param标记必须放在一起。
- @return描述:这个标记将对当前方法添加“return”(返回)部分。这个描述可以跨越多行,并可以使用HTML标记。
- @throws类描述:这个标记将添加一个注释,用于表示这个方法有可能抛出异常。
- @version文本:这个标记将产生一个“version”(版本)条目(通用注释)
4.9.6 包与概述注释
- 可以直接将类、方法和变量的注释放置在Java源文件中,只要用/**…*/文档注释界定就可以了
- 要想产生包注释,就需要在每一个包目录中添加一个单独的文件
- 提供一个以package.html命名的HTML文件: 在标记<body>…</body>之间的所有文本都会被抽取出来
- 提供一个以package-info.java命名的Java文件: 文件必须包含一个初始的以/**和*/界定的Javadoc注释,跟随在一个包语句之后。它不应该包含更多的代码或注释
4.9.7 注释的抽取
- 注释的抽取步骤:
- 切换到包含想要生成文档的源文件目录
- 如果有嵌套的包要生成文档,例如com.horstmann.corejava,就必须切换到包含子目录com的目录(如果存在overview.html文件的话,这也是它的所在目录)
- 如果是一个包,应该运行命令:javadoc -d docDirectory nameOfPackage;对于多个包生成文档,运行:javadoc -d docDirectory nameOfPackage1 nameOfPackage2 …;如果文件在默认包中,就应该运行:javadoc -d docDirectory *.java
- 切换到包含想要生成文档的源文件目录
4.10 类设计技巧
- 一定要保证数据私有
- 一定要对数据初始化
- 不要在类中使用过多的基本类型
- 不是所有的域都需要独立的域访问器和域更改器
- 将职责过多的类进行分解
- 类名和方法名要能够体现它们的职责
- 优先使用不可变的类
5 继承
- 继承已存在的类就是复用(继承)这些类的方法和域,在此基础上,还可以添加一些新的方法和域,以满足新的需求
- 反射是指在程序运行期间发现更多的类及其属性的能力
5.1 类、超类和子类
5.1.1 定义子类
- 关键字extends表示继承
- 关键字extends表明正在构造的新类派生于一个已存在的类
- 已存在的类称为超类、基类或父类;新类称为子类、派生类
1 | //Manager继承Employee类 |
5.1.3 子类构造器
- 覆盖方法:提供一个与超类方法同名的方法进行覆盖
- 在子类中可以增加域、增加方法或覆盖超类的方法,绝对不能删除继承的任何域和方法
- 可以使用super关键字调用超类
- super与this的区别
- super只是指示编译器调用超类方法的特殊关键字,不是一个对象的引用,不能将super赋给另一个对象变量
- this关键字有两个用途:(1)引用隐式参数 (2)调用该类其他的构造器
- super关键字两个用途:(1)调用超类的方法 (2)调用超类的构造器
- super与this的区别
- 调用构造器的语句只能作为另一个构造器的第一条语句出现,使用super调用超类构造器的语句必须是子类构造器的第一条语句
- 如果子类的构造器没有显式地调用超类的构造器,则将自动地调用超类默认(没有参数)的构造器
- 构造参数既可以传递给本类(this)的其他构造器,也可以传递给超类(super)的构造器
- 在Java中,虚拟机知道对象实际引用的对象类型,能够正确地调用相应的方法
- 多态:一个对象变量可以指示多种实际类型的现象
- 动态绑定:在运行时能够自动地选择调用哪个方法的现象
- 在Java中,不需要将方法声明为虚拟方法,动态绑定是默认的处理方式.如果不希望让一个方法具有虚拟特征,可以将它标记为final
1 | //Manager子类的构造器方法 |
5.1.4 继承层次
- 继承层次:由一个公共超类派生出来的所有类的集合
- 继承并不仅限于一个层次,可以由子类再次派生出其他类
- 在继承层次中,从某个特定的类到其祖先的路径被称为该类的继承链
- Java不支持多继承(但可以利用接口实现)
5.1.5 多态
- 不能将一个超类的引用赋给子类变量
- 在Java中,子类数组的引用可以转换成超类数组的引用,而不需要采用强制类型转换
- 需要注意子类数组的引用与超类数组的引用,引用同一个对象时,调用子类的方法可能调用一个不存在的实例域
- 为了确保不发生这类错误,所有数组都要牢记创建它们的元素类型,并负责监督仅将类型兼容的引用存储到数组中
- 判断是否可以设计为继承关系的简单规则
- “is-a”规则:表明子类的每个对象也是超类的对象
- 置换法则:程序中出现超类对象的任何地方都可以用子类对象置换
- 在Java程序设计语言中,对象变量是多态的
- 一个Employee变量既可以引用一个Employee类对象,也可以引用一个Employee类的任何一个子类的对象
5.1.6 理解方法调用
- 方法调用流程:
- 编译器查看对象的声明类型和方法名。编译器获得所有可能被调用的候选方法
- 编译器将查看调用方法时提供的参数类型。编译器已获得需要调用的方法名字和参数类型
- 如果是private方法、static方法、final方法或者构造器,那么编译器将可以准确地知道应该调用哪个方法(静态绑定)。与此对应的是,调用的方法依赖于隐式参数的实际类型,并且在运行时实现动态绑定
- 当程序运行,并且采用动态绑定调用方法时,虚拟机一定调用与所引用对象的实际类型最合适的那个类的方法
- 在运行时,调用e.getSalary()的解析过程为:
- 虚拟机提取e的实际类型的方法表。既可能是Employee、Manager的方法表,也可能是Employee类的其他子类的方法表
- 虚拟机搜索定义getSalary签名的类,虚拟机已经知道应该调用哪个方法
- 虚拟机调用方法
- 动态绑定有一个非常重要的特性:无需对现存的代码进行修改,就可以对程序进行扩展
- 假设增加一个新类Executive,并且变量e有可能引用这个类的对象,我们不需要对包含调用e.getSalary()的代码进行重新编译
- 如果e恰好引用一个Executive类的对象,就会自动地调用Executive.getSalary()方法
- 在覆盖一个方法的时候,子类方法不能低于超类方法的可见性
- 特别是,如果超类方法是public,子类方法一定要声明为public
5.1.7 组织继承:final类和方法
- 不允许扩展的类被称为final类,用于阻止利用该类定义子类
- 在定义类的时候使用final修饰符就表明这个类是final类,该类不可以被继承
- 类中的方法也可以被声明为final
- 子类不能覆盖该方法
- final类,只有其中的方法自动转换为final,域不进行转换
- 声明final域 (final域在构造对象之后不允许被改变)
5.1.8 强制类型转换
- 将某个类的对象引用转换成另外一个类的对象引用
- 仅需要用一对圆括号将目标类名括起来,并放置在需要转换的对象引用之前(与数值类型转换类似)
- 进行类型转换的唯一原因是:在暂时忽视对象的实际类型之后,使用对象的全部功能
- 在Java中,每个对象变量都属于一个类型(类型描述了这个变量所引用的以及能够引用的对象类型)
- 将一个值存入变量时,编译器将检查是否允许该操作
- 子类的引用赋给超类变量,编译器允许
- 超类的引用赋给子类变量,必须进行类型转换(为通过运行时的检查)
- 只能在继承层次内进行类型转换
- 在超类转换成子类之前,使用instanceof操作符查看一下是否能够成功地转换
- 实际上,通过类型转换调整对象类型并不是好的做法(因为多态性的动态绑定机制能够自动地找到相应的方法)
- 只有在使用Manager中特有的方法时才需要进行类型转换
1 | if(staff[1] instanceof manager) |
5.1.9 抽象类
- 建议将通用的域和方法放在超类中
- 抽象方法充当着占位的角色,具体的实现在子类中
- 扩展抽象类可以有两种选择:
- 一种是在抽象类中定义部分抽象类方法或不定义抽象类方法
- 另一种是定义全部的抽象方法
- 抽象类不能被实例化
- 不能创建abstract类的对象
- 可以定义一个抽象类的对象变量,但是只能引用非抽象子类的对象
- 在接口中大量使用抽象方法
- 在抽象类定义的抽象方法
- 若在超类中不定义该方法,则不可以通过抽象类对象变量调用类的方法
- 若超类定义了该方法,则可以通过抽象类的对象变量调用超类的方法
1 | //使用abstract关键字不需要实现方法 |
5.1.10 受保护访问
- 4个访问修饰符
- 仅对本类可见——private
- 对所有类可见——public
- 对本包和所有子类可见——protected
- 对本包可见——默认,不需要修饰符
5.2 Object:所有类的超类
- Object类是Java中所有类的始祖(每个类都是由它扩展而来的)
- 在Java中,只有基本类型不是对象
5.2.1-2 equals方法_相等测试与继承
- Object类中的equals方法用于检测一个对象是否等于另外一个对象
- 在Object类中,equals方法将判断两个对象是否具有相同的引用(如果两个对象具有相同的引用,它们一定是相等的),但该方法没有实际意义,需要在自己的类中重写该方法
- getClass()方法将返回一个对象所属的类,其进行相等检测的思考
- 如果子类能够拥有自己的相等概念,则对称性需求将强制采用getClass进行检测
- 如果由超类决定相等的概念,那么就可以使用instanceof进行检测,这样可以在不同子类的对象之间进行相等的比较
- 隐式参数和显示参数不属于同一个类,如何进行比较?
- 使用equals方法,类不匹配则不相同
若使用instanceof进行检测(if(!(otherObject instanceof Employee)) return false;)不能解决otherObject是子类的问题,且还会带来新的麻烦
1 | //超类Employee的equals方法 |
- 语言规范要求equals方法应具有的特性
- 自反性:对于任何非空引用x,x.equals(x)应该返回true
- 对称性:对于任何引用x和y,当且仅当y.equals(x)返回true,x.equals(y)也应该返回true
- 传递性:对于任何引用x、y和z,如果x.equals(y)返回true,y.equals(z)返回true,x.equals(z)也应该返回true
- 一致性:如果x和y引用的对象没有发生变化,反复调用x.equals(y)应该返回同样的结果
- 对于任意非空引用x,x.equals(null)应该返回false
- 完美equals方法的建议
- 显式参数命名为otherObject(稍后需要类型转换)
- 检测this与otherObject是否引用同一个对象:(if(this == otherObject) return true;)实际上,这是一种经常采用的形式。因为计算这个等式要比一个一个地比较类中的域所付出的代价小得多
- 检测otherObject是否为null,如果为null,返回false(必要)
- 比较this与otherObject是否属于同一个类
- 如果equals的语义在每个子类中有所改变,就使用getClass检测
- 如果所有的子类都拥有统一的语义,就使用instanceof检测
- 将otherObject转换为相应的类类型变量
- 现在开始对所有需要比较的域进行比较了。使用==比较基本类型域,使用equals比较对象域。如果所有的域都匹配,就返回true;否则返回false
5.2.3 hashCode方法
- 散列码是由对象导出的一个整型值:
- 散列码没有规律(如果x和y是两个不同的对象,x.hashCode()与y.hashCode()基本上不会相同)
- 在String类中,可以使用hashCode()方法获取散列码
- hashCode方法定义在Object类中,每个对象都有一个默认的散列码,其值为对象的存储地址
- 若重新定义equals方法,必须重新定义hashCode方法,以便将对象插入到散列表中
- Equals与hashCode的定义必须一致(如果x.equals(y)返回true,那么x.hashCode()就必须与y.hashCode()具有相同的值)
- hashCode方法应该返回一个整型数值(也可以是负数),并合理地组合实例域的散列码,以便能够让各个不同的对象产生的散列码更加均匀。
- 定义hashCode方法的注意事项:
- 最好使用null安全的方法Objects.hashCode
- 如果其参数为null,其结果为0
- 使用静态的Double.hashCode方法类避免创建Double对象
- 组合多个散列值,可以使用Objects.hash并提供多个参数
- 该方法会对各个参数调用Objects.hashCode,并组合这些散列值
- 最好使用null安全的方法Objects.hashCode
1 | //Employee类的hashCode方法 |
5.2.4 toString方法
- 在Object中toString方法,用于返回表示对象值的字符串
- 绝大多数的toString方法都采用的格式:类的名字,随后是一对方括号括起来的域值
- Object类定义了toString方法,用来打印输出对象所属的类名和散列码
- 子类需要定义自己的toString方法,并将子类域的描述添加进去
- 如果超类使用了getClass().getName(),那么子类只要调用super.toString()
- 随处可见toString方法的主要原因(只要对象与一个字符串通过操作符“+”连接起来,Java编译就会自动地调用toString方法,以便获得这个对象的字符串描述)
- 数组继承了object类的toString方法,数组按照旧的格式打印
- 使用静态方法Arrays.toString可以获得数组字符串
- 多维数组使用Arrays.deepToString方法
- 使用静态方法Arrays.toString可以获得数组字符串
- 可以使用该toString方法进行调试信息输出
1 | //Employee类的toString方法 |
5.3 泛型数组列表
- Java支持数组在运行时确定数组的大小,即将一个变量赋值给数组大小
- Java具有ArrayList的类
- 类似数组,但在添加或删除元素时,具有自动调节数组容量的功能
- ArrayList是一个采用类型参数的泛型类
- 为了指定数组列表保存的元素对象类型,需要用一对尖括号将类名括起来加在后面(ArrayList<Employee>)
- 数组列表的容量与数组的大小有一个非常重要的区别
- 如果为数组分配100个元素的存储空间,数组就有100个空位置可以使用
- 容量为100个元素的数组列表只是拥有保存100个元素的潜力(实际上,重新分配空间的话,将会超过100)
- 但是在最初,甚至完成初始化构造之后,数组列表根本就不含有任何元素
- 一旦能够确认数组列表的大小不再发生变化,就可以调用trimToSize方法(将存储区域的大小调整为当前元素数量所需要的存储空间数目)
- 一旦整理了数组列表的大小,添加新元素就需要花时间再次移动存储块(应该在确认不会添加任何元素时,再调用trimToSize)
1 | //声明和构造保存Employee对象的数组列表 |
5.3.1 访问数组列表元素
- 使用get和set方法实现访问或改变数组元素的操作
- 不使用[]语法格式进行索引元素
- 使用add方法为数组添加新元素,而不要使用set方法
- set方法只能替换数组中已经存在的元素内容
- get方法可获得数组列表的元素
没有泛型类时,原始的ArrayList类的get方法只能返回Object,因此还需要对返回值进行类型转换- add方法和set方法允许接受任何类型对象
- 对数组实施插入和删除元素的操作其效率比较低
- 对于小型数组来说,这一点不必担心
- 但如果数组存储的元素数比较多,又经常需要在中间位置插入、删除元素,就应该考虑使用链表了
5.3.2 类型化与原始数组列表的兼容性
- 只要在与遗留的代码进行交叉操作时,研究一下编译器的警告性提示,并确保这些警告不会造成太严重的后果就行了。
- 一旦能确保不会造成严重的后果,可以用@SuppressWarnings(“unchecked”)标注来标记这个变量能够接受类型转换。
1 | ArrayList<Employee> result = |
5.4 对象包装器与自动装箱
- 所有的基本类型都有一个与之对应的类,这些类称为包装器
- Integer,Long,Float,Double,Short,Byte,Character,Void和Boolean(前6个类派生于公共的超类Number)
- 对象包装器类是不可变的,即一旦构造了包装器,就不允许更改包装在其中的值
- 对象包装器类还是final,不能定义它们的子类
- 由于每个值分别包装在对象中,ArrayList<Integer>的效率远远低于int[]数组
- 自动装箱:
- 便于添加int类型的元素到ArrayList<Integer>中
- 要求boolean、byte、char≤127,介于-128~127之间的short和int被包装到固定的对象中
- 在算术表达式中也能够自动地装箱和拆箱
- 在自增自减操作中,编译器将自动地插入一条对象拆箱的指令,然后进行自增(自减)计算,最后再将结果装箱
- 基本类型与它们的对象包装器是一样的,只是它们的相等性不同
- ==运算符也可以应用于对象包装器对象,只不过检测的是对象是否指向同一个存储区域
- 在两个包装器对象比较时调用equals方法
- 自动装箱的问题说明:
- 由于包装器类引用可以为null,所以自动装箱有可能会抛出一个NullPointerException异常
- 如果在一个条件表达式中混合使用Integer和Double类型,Integer值就会拆箱,提升为double,再装箱为Double
- 使用数值对象包装器还有另外一个好处。Java设计者发现,可以将某些基本方法放置在包装器中,例如,将一个数字字符串转换成数值
1 | //自动转换(自动装箱) |
- Integer对象是不可变的:包含在包装器中的内容不会改变
- 不能使用这些包装器类创建修改数值参数的方法
- 如果想编写一个修改数值参数值的方法,就需要使用在org.omg.CORBA包中定义的持有者(holder)类型,包括IntHolder、BooleanHolder等。每个持有者类型都包含一个公有(!)域值,通过它可以访问存储在其中的值
1 | //按值传递,故x不会发生改变 |
5.5 参数数量可变的方法
- 提供了可以用可变的参数数量调用的方法(变参方法),利用…符号表示参数数量可变
- 省略号…是Java代码的一部分,它表明这个方法可以接收任意数量的对象
- printf方法接收两个参数,一个是格式字符串,另一个是Object[]数组,其中保存着所有的参数
- 对于printf的实现者来说,Object…参数类型与Object[]完全一样
- 编译器需要对printf的每次调用进行转换,以便将参数绑定到数组上,并在必要的时候进行自动装箱
- 可以定义可变参数的方法,并将参数指定为任意类型,甚至是基本类型
- 允许将一个数组传递给可变参数方法的最后一个参数
- 可以将已经存在且最后一个参数是数组的方法重新定义为可变参数的方法,而不会破坏任何已经存在的代码
1 | public class PrintStream |
5.6 枚举类
- 比较两个枚举类型的值,不需要调用equals,而直接使用“==”就可以了
- 可以在枚举类型中添加一些构造器、方法和域(构造器只是在构造枚举常量的时候被调用)
1 | public enum Size |
- 所有的枚举类型都是Enum类的子类
- 继承了Enum类的许多方法
- 其中最有用的一个是toString,这个方法能够返回枚举常量名
- toString的逆方法是静态方法valueOf
- 每个枚举类型都有一个静态的values方法,它将返回一个包含全部枚举值的数组
- ordinal方法返回enum声明中枚举常量的位置,位置从0开始计数
- 继承了Enum类的许多方法
- 同Class类一样,鉴于简化的考虑,Enum类省略了一个类型参数(实际上,应该将枚举类型Size扩展为Enum<Size>
- 类型参数在compareTo方法中使用(compareTo方法 类型参数)
5.7 反射
- 反射库提供了一个非常丰富且精心设计的工具集,以便编写能够动态操纵Java代码的程序
- 能够分析类能力的程序称为反射,反射机制可以用来:
- 在运行时分析类的能力
- 在运行时查看对象,例如,编写一个toString方法供所有类使用
- 实现通用的数组操作代码
- 利用Method对象,这个对象很像C++中的函数指针
5.7.1 Class类
- 在程序运行期间,系统始终为所有的对象维护一个运行时的类型标识,该标识的信息跟踪着每个对象所属的类。虚拟机利用运行时类型信息选择相应的方法执行
- 可以通过专门的Java类访问这些信息(保存这些信息的类被称为Class)
- 一个Class对象实际上表示的是一个类型,而这个类型未必一定是一种类,且Class类实际上是一种泛型类
- 相关方法:
- 利用Object类中的getClass()方法获得Class类型的实例(获得class对象)
- T.class可获得匹配的类对象(T为任意的java类型)(获得class对象)
- Class类的forName()方法可以获得类名对应的Class对象(全路径名)
- Class类的getName()方法获得返回类的名字
- newInstance()方法可以创建一个类的实例
- 配合forName()和newInstance()方法可以根据储存在字符串中的类名动态创建一个对象
1 | //一个Class对象将表示一个特定类的属性 |
5.7.2 捕获异常
- 异常有两种类型:
- 未检查异常
- 已检查异常
- 对于已检查异常,编译器将会检查是否提供了处理器
- 使用try_catch语句
1 | //将可能抛出已检查异常的一个或多个办法调用代码放在try块中 |
5.7.3 利用反射分析类的能力
- Class类中的getFields,getMethods和getConstructors方法分别返回类提供的public域,方法和构造器数组(包括超类的公有成员)
- Class类的getDeclareFields,getDeclareMethods和getDeclaredConstructors方法分别返回类中声明的全部域、方法和构造器(包括私有和受保护成员,但不包括超类的成员)
- 在java.lang.reflect包中有三个类Field,Method和Constructor分别用于描述类的域、方法和构造器
- Method和Constructor类有能够报告参数类型的方法,Method类还有一个可以报告返回类型的方法
- 三个类都有getName方法(返回项目的名称)
- 三个类都有getModifiers方法(返回整型数值,用不同的位开关描述public和static这样的修饰符使用状况)
- 可利用java.lang.reflect包中的Modifier类的静态方法分析getModifiers返回的整型数值
- Field类有getType方法(返回描述域所属类型的Class对象)
5.7.4 在运行时使用反射分析对象
- 查看对象域的关键方法是Field类中的get方法
- 只有利用get方法才能得到可访问域的值。除非拥有访问权限,否则Java安全机制只允许查看任意对象有哪些域,而不允许读取它们的值
- setAccessible方法是AccessibleObject类中的一个方法,是Field、Method和Constructor类的公共超类
- 该特性是为调试、持久存储和相似机制提供的
1 | Employee harry = new Employee("Harry Hacker", 35000, 10,1, 1989); |
5.7.5 使用反射编写泛型数组代码
- java.lang.reflect包中的Array类允许动态地创建数组
- getLength()是Array类的方法,而getCOmponentType()是Class类的方法
1 | //将Employee[]数组转换为Object[]数组 |
5.7.6 调用任意方法
- 反射机制允许调用任意方法
- 在Method类中有一个invoke方法(允许调用包装在当前Method对象中的方法)
- invoke的参数和返回值必须是Object类型(必须进行多次的类型转换)
1 | //invoke方法签名 |
5.8 继承的设计技巧
- 将公共操作和域放在超类
- 不要使用受保护的域
- protected机制并不能够带来更好的保护
- 1.子类集合是无限制的,任何一个人都能够由某个类派生一个子类,并编写代码以直接访问protected的实例域,从而破坏了封装性。
- 2.在Java程序设计语言中,在同一个包中的所有类都可以访问proteced域,而不管它是否为这个类的子类
- protected方法对于指示那些不提供一般用途而应在子类中重新定义的方法很有用
- 使用继承实现“is-a”关系
- 除非所有继承的方法都有意义,否则不要使用继承
- 如果扩展LocalDate就不会出现这个问题。由于这个类是不可变的,所以没有任何方法会把假日变成非假日
- 在覆盖方法时,不要改变预期的行为
- 使用多态,而非类型信息
- action1与action2表示的是相同的概念吗?如果是相同的概念,就应该为这个概念定义一个方法,并将其放置在两个类的超类或接口中
- 可以调用以便使用多态性提供的动态分派机制执行相应的动作
- 不要过多地使用反射
6 接口,Lambda表达式与内部类
- 接口技术,主要用来描述类具有什么功能,而并不给出每个功能的具体实现
- 一个类可以实现一个或多个接口,并在需要接口的地方,随时使用实现了相应接口的对象
- 使用lambda表达式,可以用一种精巧而简洁的方式表示使用回调或变量行为的代码
- 内部类机制
- 内部类定义在另外一个类的内部,其中的方法可以访问包含它们的外部类的域
- 内部类技术主要用于设计具有相互协作关系的类集合
- 代理(实现任意接口的对象),代理是一种非常专业的构造工具,可以用来构建系统级的工具
6.1 接口
6.1.1 接口概念
-
在Java程序设计语言中,接口不是类,而是对类的一组需求描述,这些类要遵从接口描述的统一格式进行定义
-
一个具体的示例
- Arrays类的sort方法可以对对象数组进行排序
- 但对象所属的类必须实现了Comparable接口
- 任何实现Comparable接口的类都需要包含compareTo方法
- 在调用x.compareTo(y)的时候,compareTo方法必须比较两个对象的内容,并返回比较的结果
- 当x小于y时,返回一个负数
- 当x等于y时,返回0;否则返回一个正数
- Arrays类的sort方法可以对对象数组进行排序
-
接口可能包含多个方法
- 接口中的所有方法默认为public(在声明方法时,不必提供关键字public)
- 接口还可以定义常量
-
提供实例域和方法实现的任务应该由实现接口的那个类来完成
- 接口看成是没有实例域的抽象类
-
让类实现接口,需要两个步骤:
- 将类声明为实现给定的接口
- 对接口中的所有方法进行定义
-
使用implements关键字将类声明为实现某个接口
-
让一个类使用排序服务必须让它实现compareTo方法
-
两个整数利用减法操作进行大小比较
- 整数的范围不能过大,以避免造成减法运算的溢出
- 如果能够确信ID为非负整数,或者它们的绝对值不会超过(Integer.MAX_VALUE-1)/2,就不会出现问题
- 否则,调用静态Integer.compare方法
- 相减技巧不适用于浮点值
-
为什么不能在类中直接提供一个compareTo方法,而必须使用接口
- Java程序设计语言是一种强类型语言。在调用方法的时候,编译器将会检查这个方法是否存在
- 如果a是一个Comparable对象的数组,就可以确保拥有compareTo方法,因为每个实现Comparable接口的类都必须提供这个方法的定义
将Arrays类中的sort方法定义为接收一个Comparable[]数组就可以在使用元素类型没有实现Comparable接口的数组作为参数调用sort方法时,由编译器给出错误报告,但事实并非如此。在这种情况下,sort方法可以接收一个Object[]数组,并对其进行笨拙的类型转换
-
语言标准规定
- 对于任意的x和y,实现必须能够保证sgn(x.compareTo(y))=-sgn(y.compareTo(x))
- 即y.compareTo(x)抛出一个异常,x.compareTo(y)也应该抛出一个异常
- 这里的“sgn”是一个数值的符号:如果n是负值,sgn(n)等于-1;如果n是0,sgn(n)等于0;如果n是正值,sgn(n)等于1。简单地讲,如果调换compareTo的参数,结果的符号也应该调换(而不是实际值)
-
如果子类之间的比较含义不一样,那就属于不同类对象的非法比较参考第五章equals方法
- 通用算法(能够对两个不同的子类对象进行比较),应该在超类中提供一个final常量的compareTo方法
1 | //Comparable接口的代码 |
6.1.2 接口的特性
- 接口不是类,尤其不能使用new运算符实例化一个接口
- 尽管不能构造接口的对象,却能声明接口的变量,接口变量必须引用实现了接口的类对象
- 可以使用instance检查一个对象是否实现了某个特定的接口
- 接口中可以包含常量,但不可以包含实例域和静态方法
- 与接口中的方法都自动地被设置为public一样,接口中的域将被自动设为public static final
1 | //定义接口变量 |
6.1.3 接口与抽象类
- 使用抽象类表示通用属性存在这样一个问题
- 每个类只能扩展于一个类。假设Employee类已经扩展于一个类,例如Person,它就不能扩展第二个类了
- 但每个类可以实现多个接口
- Java的不支持多继承,其主要原因是多继承会让语言本身变得非常复杂(如同C++),效率也会降低
- 接口可以提供多重继承的大多数好处,同时还能避免多重继承的复杂性和低效性
6.1.4 静态方法
- 通常静态方法放在伴随类中,例如Collection/Collections或Path/Paths
- 在Java SE 8中,允许在接口中增加静态方法
- 实现自己的接口不再需要为实用工具方法另外提供一个伴随类
6.1.5 默认方法
- 可以用default修饰符为接口方法提供一个默认方法
- 默认方法可以调用任何其他方法
- 默认方法的一个重要用法是“接口演化”
- 假设stream方法不是一个默认方法。那么Bag类将不能编译,因为它没有实现这个新方法。为接口增加一个非默认方法不能保证“源代码兼容”
- 不过,假设不重新编译这个类,而只是使用原先的一个包含这个类的JAR文件。这个类仍能正常加载,尽管没有这个新方法。程序仍然可以正常构造Bag实例,不会有意外发生。
- 如果程序在一个Bag实例上调用stream方法,就会出现一个AbstractMethodError
- 将方法实现为一个默认方法就可以解决这两个问题。Bag类又能正常编译了。另外如果没有重新编译而直接加载这个类,并在一个Bag实例上调用stream方法,将调用Collection.stream方法
1 | public interface Comparable<T> |
6.1.6 解决默认方法冲突
- 如果先在一个接口中将一个方法定义为默认方法,然后又在超类或另一个接口中定义了同样的方法,会发生什么情况?
- 超类优先。如果超类提供了一个具体方法,同名而且有相同参数类型的默认方法会被忽略
- 一个类扩展了一个超类,同时实现了一个接口,并从超类和接口继承了相同的方法
- 在这种情况下,只会考虑超类方法,接口的所有默认方法都会被忽略
- “类优先”规则可以确保与Java SE 7的兼容性
- 如果为一个接口增加默认方法,这对于有这个默认方法之前能正常工作的代码不会有任何影响
- 千万不要让一个默认方法重新定义Object类中的某个方法
- 例如,不能为toString或equals定义默认方法,尽管对于List之类的接口这可能很有吸引力.由于“类优先”规则,这样的方法绝对无法超越Object.toString或Objects.equals
- 在这种情况下,只会考虑超类方法,接口的所有默认方法都会被忽略
- 接口冲突。如果一个超接口提供了一个默认方法,另一个接口提供了一个同名而且参数类型(不论是否是默认参数)相同的方法,必须覆盖这个方法来解决冲突(解决二义性问题)
1 | interface Named |
6.2 接口示例
6.2.1 接口与回调
- 回调(是一种常见的程序设计模式)
- 在这种模式中,可以指出某个特定事件发生时应该采取的动作
6.2.2 Comparator接口
- 假设我们希望按长度递增的顺序对字符串进行排序,而不是按字典顺序进行排序
- Arrays.sort方法还有第二个版本,有一个数组和一个比较器(comparator)作为参数,比较器是实现了Comparator接口的类的实例
1 | //Comparator接口 |
6.2.3 对象克隆
- Cloneable接口(指示一个类提供了一个安全的clone方法)
- Cloneable接口是Java提供的一组标记接口(标记接口不包含任何方法,唯一的作用是允许在类型查询中使用instanceof)之一
- Comparable等接口的通常用途是确保一个类实现一个或一组特定的方法
- clone方法是Object的一个protected方法(不能直接调用anObject.clone())
- 只有Employee类可以克隆Employee对象
- 限制的原因:
- 如果对象中的所有数据域都是数值或其他基本类型,拷贝没有问题
- 如果对象包含子对象的引用,拷贝域就会得到相同子对象的另一个引用,原对象和克隆的对象仍然会共享一些信息
- 默认的克隆操作是“浅拷贝”,并没有克隆对象中引用的其他对象
- 浅拷贝的影响
- 如果原对象和浅克隆对象共享的子对象是不可变的,共享是安全的
- 如果子对象属于一个不可变的类,如String。或者在对象的生命期中,子对象一直包含不变的常量,没有更改器方法会改变它,也没有方法会生成它的引用,安全
- 通常子对象是可变的,必须重新定义clone方法来建立深拷贝,同时克隆所有子对象
- 浅拷贝的影响
- 对于每一个类,需要确定
- 默认的clone方法是否满足要求
- 是否可以在可变的子对象上调用clone来修补默认的clone方法
- 是否不该使用clone
- 第3个选项是默认选项;如果选择第1项或第2项,类必须:
- 实现Cloneable接口
- 重新定义clone方法,并指定public访问修饰符
- clone方法实现的注意事项:
- 必须重新定义clone为public才能允许所有方法克隆对象(子类只能调用受保护的clone方法来克隆它自己的对象)
- Cloneable接口的出现与接口的正常使用并没有关系
- 具体来说,它没有指定clone方法,这个方法是从Object类继承的
- Cloneable接口只是作为一个标记,指示类设计者了解克隆过程。对象对于克隆很“偏执”,如果一个对象请求克隆,但没有实现这个接口,就会生成一个受查异常
1 | //即使clone的默认(浅拷贝)实现能够满足要求,还是需要实现Cloneable接口 |
6.3 Lambda表达式
6.3.1_2 引入Lambda表达式及语法
- lambda表达式是一个可传递的代码块,可以在以后执行一次或多次
- 语法:参数,箭头(->)以及一个表达式
- 如果代码要完成的计算无法放在一个表达式中,就可以像写方法一样,把这些代码放在{}中,并包含显式的return语句
- 即使lambda表达式没有参数,仍然要提供空括号,就像无参数方法一样
- 如果可以推导出一个lambda表达式的参数类型,则可以忽略其类型
- 无需指定lambda表达式的返回类型(返回类型会由上下文推导得出)
- 如果一个lambda表达式只在某些分支返回一个值,在另外一些分支不返回值(不合法)
1 | (String first, String second) -> |
6.3.3 函数式接口
- 函数式接口:对于只有一个抽象方法的接口,需要这种接口的对象时,就可以提供一个lambda表达式
- 为什么函数式接口必须有一个抽象方法:
- 接口中的方法并不是完全抽象的
- 接口完全有可能重新声明Object类的方法,如toString或clone,这些声明有可能会让方法不再是抽象的
- 在JavaSE8中,接口可以声明非抽象方法
- 在Java中,对lambda表达式所能做的也只是能转换为函数式接口
- 不能把lambda表达式赋给类型为Object的变量,Object不是一个函数式接口
1 | //展示如何转化为函数式接口 |
6.3.4 方法引用
- 表达式System.out::println是一个方法引用,等价于lambda表达式x->System.out.println(x)
- 要用::操作符分隔方法名与对象或类名。主要有3种情况:
- object::instanceMethod
- Class::staticMethod
- Class::instanceMethod
- 前2种情况中,方法引用等价于提供方法参数的lambda表达式
- 对于第3种情况,第1个参数会成为方法的目标。例如,String::compareToIgnoreCase等同于(x,y)->x.compareToIgnoreCase(y)
- 要用::操作符分隔方法名与对象或类名。主要有3种情况:
- 如果有多个同名的重载方法,编译器就会尝试从上下文中找出你指的那一个方法
- 类似于lambda表达式,方法引用不能独立存在,总是会转换为函数式接口的实例
- 可以在方法引用中使用this参数。例如,this::equals等同于x->this.equals(x)
- ==使用super也是合法的,super::instanceMethod
- 使用this作为目标,会调用给定方法的超类版本
6.3.5 构造器引用
- 构造器引用与方法引用很类似,只不过方法名为new
- Person::new是Person构造器的一个引用
- 可以用数组类型建立构造器引用
- 例如,int[]::new是一个构造器引用,它有一个参数:即数组的长度。这等价于lambda表达式x->new int[x]
1 | //Java有一个限制,无法构造泛型类型T的数组。数组构造器引用对于克服这个限制很有用 |
6.3.6变量作用域
- lambda表达式有3个部分:
- 一个代码块
- 参数
- 自由变量的值(指非参数而且不在代码中定义的变量)
- 关于代码块以及自由变量值有一个术语:闭包
- lambda表达式可以捕获外围作用域中变量的值
- 在Java中,要确保所捕获的值是明确定义的,在lambda表达式中,只能引用值不会改变的变量,如果在lambda表达式中引用变量,而这个变量可能在外部改变,这也是不合法的
- lambda表达式中捕获的变量必须实际上是最终变量
- 最终变量是指,这个变量初始化之后就不会再为它赋新值
- 在lambda表达式中声明与一个局部变量同名的参数或局部变量是不合法的
- 在方法中,不能有两个同名的局部变量,因此,lambda表达式中同样也不能有同名的局部变量
- 在一个lambda表达式中使用this关键字时,是指创建这个lambda表达式的方法的this参数
1 | //表达式this.toString()会调用Application对象的toString方法,而不是ActionListener实例的方法 |
6.3.7 处理lambda表达式
- 使用lambda表达式的重点是延迟执行
- 大多数标准函数式接口都提供了非抽象方法来生成或合并函数
- 已经提供了默认方法and、or和negate来合并谓词
- 如果设计你自己的接口,其中只有一个抽象方法,可以用@FunctionalInterface注解来标记这个接口
- 优点:
- 如果你无意中增加了另一个非抽象方法,编译器会产生一个错误消息
- 另外javadoc页里会指出你的接口是一个函数式接口
- 优点:
- 任何有一个抽象方法的接口都是函数式接口
1 | //假设重复一个动作n次 |
6.4 内部类
- 内部类是定义在另一个类中的类
- 内部类方法可以访问该类定义所在的作用域中的数据,包括私有的数据
- 内部类可以对同一个包中的其他类隐藏起来
- 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷
- 相较于C++嵌套类的好处
- 内部类的对象有一个隐式引用,它引用了实例化该内部对象的外围类对象。通过这个指针,可以访问外围类对象的全部状态
6.4.1 使用内部类访问对象状态
1 | public class TalkingClock |
- TimePrinter类没有实例域或者名为beep的变量
- 取而代之的是beep引用了创建TimePrinter的TalkingClock对象的域
- 一个方法可以引用调用这个方法的对象数据域
- 内部类既可以访问自身的数据域,也可以访问创建它的外围类对象的数据域
- 内部类的对象总有一个隐式引用,它指向了创建它的外部类对象
6.4.2 内部类的特殊语法规则
- 内部类中声明的所有静态域都必须是final
- 原因:静态域只有一个实例,不过对于每个外部对象,会分别有一个单独的内部类实例(若不是final,它可能就不是唯一的)
- 内部类不能有static方法,可以允许有静态方法,但只能访问外围类的静态域和方法
1 | //外围类引用的表达式 |
6.4.3 内部类是否有用_必要和安全
- 内部类是一种编译器现象,与虚拟机无关
- 编译器将会把内部类翻译成用$(美元符号)分隔外部类名与内部类名的常规类文件,而虚拟机则对此一无所知
- 如果内部类访问了私有数据域,就有可能通过附加在外围类所在包中的其他类访问它们,但做这些事情需要高超的技巧和极大的决心
- 程序员不可能无意之中就获得对类的访问权限,而必须刻意地构建或修改类文件才有可能达到这个目的
6.4.4 局部内部类
- 可以在方法中定义局部类
- 局部类不能用public或private访问说明符进行声明
- 它的作用域被限定在声明这个局部类的块中
- 局部类有一个优势,即对外部世界可以完全地隐藏起来
6.4.5 由外部方法访问变量
- 局部类还有一个优点。
- 它们不仅能够访问包含它们的外部类,还可以访问final局部变量
- 局部变量必须事实上为final(一旦赋值就绝不会改变)
- 它们不仅能够访问包含它们的外部类,还可以访问final局部变量
6.4.6 匿名内部类
- 匿名内部类:假如只创建这个类的一个对象,就不必命名了
- 匿名类不能有构造器(构造器的名字必须与类名相同,匿名类没有类名)
- 将构造器参数传递给超类构造器。尤其是在内部类实现接口的时候,不能有任何构造参数
- Java程序员习惯的做法是用匿名内部类实现事件监听器和其他回调。如今最好还是使用lambda表达式。
1 | public void start(int interval, boolean beep) |
6.4.7 静态内部类
- 静态内部类:为了把一个类隐藏在另外一个类的内部,并不需要内部类引用外围类对象
- 将内部类声明为static,以便取消产生的引用
- 内部类在静态方法中构造,必须将内部类声明为静态内部类
6.5 代理
- 利用代理可以在运行时创建一个实现了一组给定接口的新类
- 这种功能只有在编译时无法确定需要实现哪个接口时才有必要使用
6.5.1 何时使用代理
- 假设有一个表示接口的Class对象(有可能只包含一个接口),它的确切类型在编译时无法知道
- 要想构造一个实现这些接口的类,就需要使用newInstance方法或反射找出这个类的构造器
- 但是,不能实例化一个接口,需要在程序处于运行状态时定义一个新类
- 代理类可以在运行时创建全新的类,能够实现指定的接口
- 尤其是,它具有下列方法:
- 指定接口所需要的全部方法
- Object类中的全部方法,例如,toString、equals等。
- 不能在运行时定义这些方法的新代码,而是要提供一个调用处理器
- 调用处理器是实现了InvocationHandler接口的类对象
- 调用处理器必须给出处理调用的方式
- 无论何时调用代理对象的方法,调用处理器的invoke方法都会被调用,并向其传递Method对象和原始的调用参数
1 | //InvocationHandler接口的唯一方法 |
6.5.2 创建代理对象
- 使用Proxy类的newProxyInstance方法创建代理对象
- 参数
- 一个类加载器
- 一个Class对象数组,每个元素都是需要实现的接口
- 一个调用处理器
6.5.3 代理类的特性
- 代理类是在程序运行过程中创建的
- 代理类一旦被创建,就变成了常规类,与虚拟机中的任何其他类没有什么区别
- 所有的代理类都扩展于Proxy类,一个代理类只有一个实例域—(调用处理器,它定义在Proxy的超类中)
- 所有的代理类都覆盖了Object类中的方法toString、equals和hashCode
- Object类中的其他方法(如clone和getClass)没有被重新定义=
- 没有定义代理类的名字,Sun虚拟机中的Proxy类将生成一个以字符串$Proxy开头的类名
- 对于特定的类加载器和预设的一组接口来说,只能有一个代理类(如果使用同一个类加载器和接口数组调用两次newProxyInstance方法的话,那么只能够得到同一个类的两个对象,也可以利用getProxyClass方法获得这个类)
- 代理类一定是public和final
- 如果代理类实现的所有接口都是public,代理类就不属于某个特定的包
- 否则,所有非公有的接口都必须属于同一个包,同时,代理类也属于这个包
- 通过调用Proxy类isProxyClass方法检测一个特定的Class对象是否代表一个代理类
7 异常_断言和日志
7.1 处理错误
7.1.1 异常分类
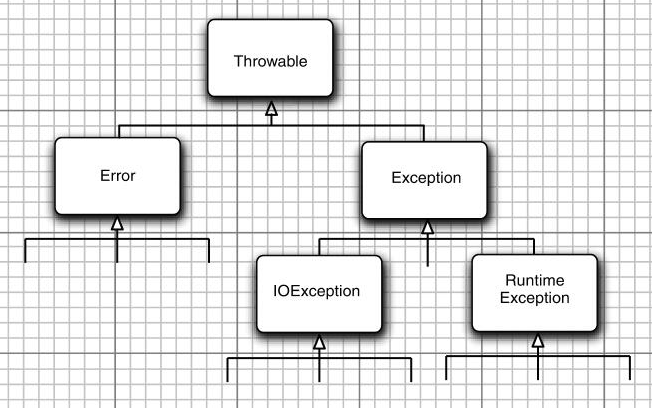
- 异常对象都是派生于Throwable类的一个实例
- 所有的异常都是Throwable继承下而来的,但分解为Error和Exception
- Error类层次结构描述了Java运行时系统的内部错误和资源耗尽错误(应用程序不应该抛出这种类型的对象)
- 需要关注Exception层次该层次结构又分解为两个分支:一个分支派生于RuntimeException;另一个分支包含其他异常
- 划分两个分支的规则是:
- 程序错误导致的异常属于RuntimeException
- 程序本身没有问题,但由于像I/O错误这类问题导致的异常属于其他异常
- 所有的异常都是Throwable继承下而来的,但分解为Error和Exception
- Java语言规范将派生于Error类或RuntimeException类的所有异常称为非受查异常,所有其他的异常称为受查异常
- 编译器将核查是否为所有的受查异常提供了异常处理器
7.1.2 声明受查异常
- 方法应该在其首部声明所有可能抛出的异常
1 | //例 |
-
在自己写的方法中.需要抛出异常的4种情况:
- 调用一个抛出受查异常的方法,例如,FileInputStream构造器
- 程序运行过程中发现错误,并且利用throw语句抛出一个受查异常
- 程序出现错误,例如,a[–1]=0会抛出一个ArrayIndexOutOfBoundsException这样的非受查异常
- Java虚拟机和运行时库出现的内部错误
-
不需要声明Java的内部错误,即从Error继承的错误
-
一个方法必须声明所有可能抛出的受查异常,而非受查异常要么不可控制(Error),要么就应该避免发生(RuntimeException)
-
如果在子类中覆盖了超类的一个方法,子类方法中声明的受查异常不能比超类方法中声明的异常更通用
- 也就是说,子类方法中可以抛出更特定的异常,或者根本不抛出任何异常
-
如果超类方法没有抛出任何受查异常,子类也不能抛出任何受查异常
-
如果类中的一个方法声明将会抛出一个异常,而这个异常是某个特定类的实例时,则这个方法就可能抛出一个这个类的异常,或者这个类的任意一个子类的异常
7.1.3 如何抛出异常
- 对于一个已经存在的异常类,抛出方法:
- 找到一个合适的异常类
- 创建这个类的一个对象
- 将对象抛出
1 | //EOFException异常描述的是“在输入过程中遇到了一个未预期的EOF后的信号” |
7.1.4 创建异常类
- 需要做的只是定义一个派生于Exception的类,或者派生于Exception子类的类
- 例如,定义一个派生于IOException的类
- 习惯上,定义的类应该包含两个构造器
- 一个是默认的构造器
- 另一个是带有详细描述信息的构造器(超类Throwable的toString方法将会打印出这些详细信息,这在调试中非常有用)
1 | //定义自己的异常类 |
7.2 捕获异常
7.2.1 捕获异常
- 要想捕获一个异常,必须设置try/catch语句块
- 如果在try语句块中的任何代码抛出了一个在catch子句中说明的异常类
- 程序将跳过try语句块的其余代码
- 程序将执行catch子句中的处理器代码
- 如果在try语句块中的代码没有抛出任何异常,那么程序将跳过catch子句
- 如果方法中的任何代码抛出了一个在catch子句中没有声明的异常类型,那么这个方法就会立刻退出
- 如果在try语句块中的任何代码抛出了一个在catch子句中说明的异常类
- 如果编写一个覆盖超类的方法,而这个方法又没有抛出异常,那么这个方法就必须捕获方法代码中出现的每一个受查异常
- 不允许在子类的throws说明符中出现超过超类方法所列出的异常类范围
1 | //try/catch语句 |
7.2.2 捕获多个异常
- 捕获多个异常时,异常变量隐含为final变量
1 | //捕获多个异常类型,并对不同类型的异常做出不同的处理 |
7.2.3 再次抛出异常与异常链
- 在catch子句中可以抛出一个异常,这样做的目的是改变异常的类型
1 | //捕获异常并将它再次抛出的基本方法 |
7.2.4 finally子句
- 如果方法获得了一些本地资源,并且只有这个方法自己知道,又如果这些资源在退出方法之前必须被回收,那么就会产生资源回收问题
- 一种解决方案是捕获并重新抛出所有的异常(需要在正常的代码中和异常代码中清除所分配的资源)
- 一种更好的解决方案,finally子句
- 不管是否有异常被捕获,finally子句中的代码都被执行
- finally中的代码总会执行
- 当finally子句包含return语句时,将会出现错误的结果
- 假设利用return语句从try语句块中退出
- 在方法返回前,finally子句的内容将被执行
- 如果finally子句中也有一个return语句,这个返回值将会覆盖原始的返回值
- 清理资源的方法也有可能抛出异常
- close方法本身也有可能抛出IOException异常。当出现这种情况时,原始的异常将会丢失,转而抛出close方法的异常
- 可以使用带资源的try语句解决
1 | //try语句可以只有finally子句,而没有catch子句 |
7.2.5 带资源的try语句
1 | //带资源的try语句的简单形式 |
- 带资源的try语句可以很好地处理:try块抛出一个异常,而且close方法也抛出一个异常
- 原来的异常会重新抛出,而close方法抛出的异常会“被抑制”
- 这些异常将自动捕获,并由addSuppressed方法增加到原来的异常
- 如果对这些异常感兴趣,可以调用getSuppressed方法,它会得到从close方法抛出并被抑制的异常列表
- 只要需要关闭资源,就要尽可能使用带资源的try语句
- 带资源的try语句的catch子句和一个finally子句在关闭资源之后执行
7.2.6 分析堆栈轨迹元素
- 堆栈轨迹是一个方法调用过程的列表,它包含了程序执行过程中方法调用的特定位置
- 可以调用Throwable类的printStackTrace方法访问堆栈轨迹的文本描述信息
- 使用getStackTrace方法得到StackTraceElement对象的一个数组,可以在程序中分析这个对象数组
- StackTraceElement类含有能够获得文件名和当前执行的代码行号的方法;同时,还含有能够获得类名和方法名的方法
- 使用toString方法将产生一个格式化的字符串,其中包含所获得的信息
- 静态的Thread.getAllStackTrace方法可以产生所有线程的堆栈轨迹
- 使用getStackTrace方法得到StackTraceElement对象的一个数组,可以在程序中分析这个对象数组
1 | Throwable t = new Throwable(); |
7.3 使用异常的技巧
- 异常处理不能代替简单的测试:只在异常情况下使用异常机制
- 不要过分地细化异常
- 利用异常层次结构
- 不要只抛出RuntimeException异常。应该寻找更加适当的子类或创建自己的异常类
- 不要只捕获Thowable异常,否则,会使程序代码更难读、更难维护
- 不要压制异常
- 在检测错误时,“苛刻”要比放任更好
- 不要羞于传递异常
7.4 使用断言
7.4.1 断言的概念
- 断言机制允许在测试期间向代码中插入一些检查语句
- 当代码发布时,这些插入的检测语句将会被自动地移走
1 | //两种形式: |
7.4.2 启用和禁用断言
- 默认情况下,断言被禁用
- 可以在运行程序时用-enableassertions或-ea选项启用
- 在启用或禁用断言时不必重新编译程序
- 启用或禁用断言是类加载器的功能。当断言被禁用时,类加载器将跳过断言代码,因此,不会降低程序运行的速度
- 可以用选项-disableassertions或-da禁用某个特定类和包的断言
- 启用和禁用所有断言的-ea和-da开关不能应用到那些没有类加载器的“系统类”上
- 对于这些系统类来说,需要使用-enablesystemassertions/-esa开关启用断言
1 | //启用断言 |
7.4.3 使用断言完成参数检查
使用断言的情况:
- 断言失败是致命的、不可恢复的错误
- 断言检查只用于开发和测阶段
7.5 记录日志
- 记录日志API的优点:
- 可以很容易地取消全部日志记录,或者仅仅取消某个级别的日志,而且打开和关闭这个操作也很容易
- 可以很简单地禁止日志记录的输出
- 日志记录可以被定向到不同的处理器.用于在控制台中显示,用于存储在文件中等
- 日志记录器和处理器都可以对记录进行过滤.过滤器可以根据过滤实现器制定的标准丢弃那些无用的记录项
- 日志记录可以采用不同的方式格式化
- 应用程序可以使用多个日志记录器,它们使用类似包名的这种具有层次结构的名字
- 在默认情况下,日志系统的配置由配置文件控制
7.5.1 基本日志
1 | //使用全局日志记录器并调用其info方法,可以生成简单的日志记录 |
7.5.2 高级日志
- 使用getLOgger方法创建或获取记录器
- 未被任何变量引用的日志记录可能会被垃圾回收,需要用静态变量存储日志记录器的一个引用
- 日志的七个等级:
- SEVERE
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST
1 | //创建或获取记录器 |
7.5.3 修改日志管理器配置
- 可以通过编辑配置文件来修改日志系统的各种属性
- 要想使用另一个配置文件,就要将java.util.logging.config.file特性设置为配置文件的存储位置
- 日志管理器在VM启动过程中初始化,在main执行之前完成
- 如果在main中调用System.setProperty(“java.util.logging.config.file”,file)
- 也会调用LogManager.readConfiguration()来重新初始化日志管理器
- 修改默认的日志记录级别
- 编辑配置文件,并修改**.LEVEL=INFO**
- 日志记录并不将消息发送到控制台上,这是处理器的任务,且处理器也有级别
- java.util.logging.ConsoleHandler.level=FINE (在控制台上看到FINE级别的消息)
- 在日志管理器配置的属性设置不是系统属性,因此,用-Dcom.mycompany.myapp.level=FINE启动应用程序不会对日志记录器产生任何影响
- 日志属性文件由java.util.logging.LogManager类处理
- 可以通过将java.util.logging.manager系统属性设置为某个子类的名字来指定一个不同的日志管理器
- 另外,在保存标准日志管理器的同时,还可以从日志属性文件跳过初始化
- 还有一种方式是将java.util.logging.config.class系统属性设置为某个类名,该类再通过其他方式设定日志管理器属性
- 可以通过将java.util.logging.manager系统属性设置为某个子类的名字来指定一个不同的日志管理器
- 在运行的程序中,使用jconsole程序也可以改变日志记录的级别
1 | //默认情况下配置文件路径 |
7.5.4 本地化
- 本地化的应用程序包含资源包中的本地特定信息
- 一个程序可以包含多个资源包,一个用于菜单;其他用于日志消息
- 要想将映射添加到一个资源包中,需要为每个地区创建一个文件
- 英文消息映射位于com/mycompany/logmessages_en.properties文件中
- 德文消息映射位于com/mycompany/logmessages_de.properties文件中
- 通常需要在本地化的消息中增加一些参数,因此,消息应该包括占位符{0}、{1}等
1 | //请求日志记录器,指定资源包 |
7.5.5 处理器
- 在默认情况下,日志记录器将记录发送到ConsoleHandler中,并由它输出到System.err流中
- 特别是,日志记录器还会将记录发送到父处理器中,而最终的处理器有一个ConsoleHandler
- 处理器也有日志记录级别
- 对于一个要被记录的日志记录,它的日志记录级别必须高于日志记录器和处理器的阈值
- 修改文件处理器的默认行为
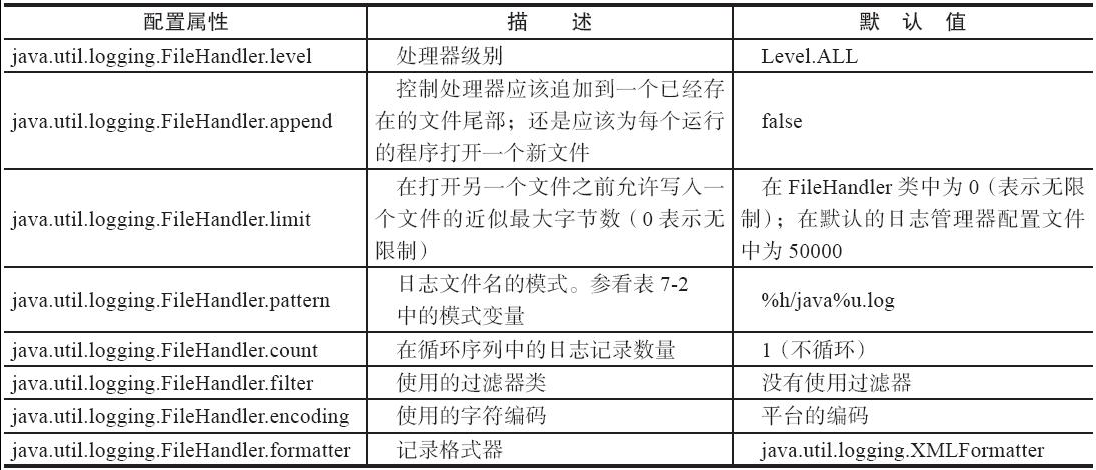
- 日志记录文件名:例如%h/myapp.log

- 如果多个应用程序(或者同一个应用程序的多个副本)使用同一个日志文件,就应该开启append标志
- 另外,应该在文件名模式中使用%u,以便每个应用程序创建日志的唯一副本
- 可以使用文件循环功能
1 | //日志管理器默认配置文件设置的默认控制台处理器的日志记录级别 |
7.5.6 过滤器
- 在默认情况下,过滤器根据日志记录的级别进行过滤
- 每个日志记录器和处理器都可以有一个可选的过滤器来完成附加的过滤
- 另外,可以通过实现Filter接口并定义下列方法来自定义过滤器
- 要想将一个过滤器安装到一个日志记录器或处理器中,只需要调用setFilter方法就可以了
- 同一时刻,最多只能有一个过滤器
1 | //实现Filter接口并定义自定义过滤器 |
7.5.7 格式化器
- ConsoleHandler类和FileHandler类可以生成文本和XML格式的日志记录
- 扩展Formatter类可以实现自定义格式
1 | //扩展Formatter类并覆盖方法 |
7.5.8 日志记录说明
- 为一个简单的应用程序,选择一个日志记录器,并把日志记录器命名为与主应用程序包一样的名字
- 为了方便起见,可能希望利用一些日志操作将静态域添加到类中
- 默认的日志配置将级别等于或高于INFO级别的所有消息记录到控制台
- 用户可以覆盖默认的配置文件(最好在应用程序中安装一个更加适宜的默认配置)
- 可以记录自己想要的内容
- 所有级别为INFO、WARNING和SEVERE的消息都将显示到控制台上
- 最好只将对程序用户有意义的消息设置为这几个级别(设定为FINE是一个很好的选择)
1 | //下列代码确保将所有的消息记录到应用程序特定的文件中 |
7.6 调试技巧
- 可以用方法打印或记录任意变量的值
- 一个不太为人所知但却非常有效的技巧是在每一个类中放置一个单独的main方法
- 日志代理(logging proxy)是一个子类的对象,它可以截获方法调用,并进行日志记录,然后调用超类中的方法
- 利用Throwable类提供的printStackTrace方法,可以从任何一个异常对象中获得堆栈情况
- 一般来说,堆栈轨迹显示在System.err上。也可以利用printStackTrace(PrintWriter s)方法将它发送到一个文件中。如果想记录或显示堆栈轨迹,可以将它捕获到一个字符串中
- 通常,将一个程序中的错误信息保存在一个文件中是非常有用的。然而,错误信息被发送到System.err中,而不是System.out中。
- 让非捕获异常的堆栈轨迹出现在System.err中并不是一个很理想的方法。如果在客户端偶然看到这些消息,则会感到迷惑,并且在需要的时候也无法实现诊断目的。比较好的方式是将这些内容记录到一个文件中。可以调用静态的Thread.setDefaultUncaughtExceptionHandler方法改变非捕获异常的处理器
- 要想观察类的加载过程,可以用-verbose标志启动Java虚拟机
- -Xlint选项告诉编译器对一些普遍容易出现的代码问题进行检查
- Java虚拟机增加了对Java应用程序进行监控(monitoring)和管理(management)的支持;它允许利用虚拟机中的代理装置跟踪内存消耗、线程使用、类加载等情况
- 可以使用jmap实用工具获得一个堆的转储,其中显示了堆中的每个对象
- 如果使用-Xprof标志运行Java虚拟机,就会运行一个基本的剖析器来跟踪那些代码中经常被调用的方法;剖析信息将发送给System.out。输出结果中还会显示哪些方法是由即时编译器编译的
8 泛型程序设计
8.1 为什么要使用泛型程序设计
8.1.1 类型参数的好处
在Java中增加范型类之前,泛型程序设计是用继承实现的ArrayList类只维护一个Object引用的数组- 具有两个问题:
- 获取一个值时必须进行强制类型转换
- 没有错误检查(可以向数组列表中添加任何类的对象)
- 使用类型参数可以很好的解决问题
- 再使用get方法时,不需要进行强制类型转换
- 只能允许前一个调用,而不能允许后一个调用
- ArrayList类有一个方法addAll用来添加另一个集合的全部元素。程序员可能想要将ArrayList<Manager>中的所有元素添加到ArrayList<Employee>中去。然而,反过来就不行了
- 可以使用通配符类型解决该问题
1 | //ArrayList类只维护一个Object引用的数组 |
8.2 定义简单泛型类
- 一个泛型类就是具有一个或多个类型变量的类
- 泛型类可以有多个类型变量,在尖括号内使用逗号隔开
- 类定义中的类型变量指定方法的返回类型以及域和局部变量的类型
- 类型变量使用大写形式,且比较短
- 使用变量E表示集合的元素类型
- K和V分别表示表的关键字与值的类型
- T (需要时还可以用临近的字母U和S)表示“任意类型”
1 | //定义Pair类 |
8.3 泛型方法
- 可以定义带有类型参数的简单方法,泛型方法
- 类型变量放在修饰符的后面,返回类型的前面
- 泛型方法可以定义在普通类中,也可以定义在泛型类中
1 | //定义泛型方法 |
8.4 类型变量的限定
- 类和方法需要对类型变量加以约束
- 解决办法:将T限制为实现了Comparable接口的类.可以通过对类型变量T设置限定实现
- 一个类型变量或通配符可以有多个限定
- 限定类型使用 & 分隔,而逗号用来分隔类型变量
- 在Java的继承中,可以根据需要拥有多个接口超类型,但限定中至多有一个类
- 如果用一个类作为限定,它必须是限定列表中的第一个
1 | //对类型变量限制 |
8.5 泛型代码和虚拟机
- 虚拟机没有泛型类型对象,所有对象都属于普通类
8.5.1 类型擦除
- 无论何时定义一个泛型类型,都自动提供了一个相应的原始类型
- 原始类型的名字就是删去类型参数后的泛型类型名
- 擦除类型变量并替换为限定类型
- 为了提高效率,应该将标签接口(即没有方法的接口)放在边界列表的末尾
1 | //Pair原始类 |
8.5.2 翻译泛型表达式
- 当程序调用泛型方法时,如果擦除返回类型,编译器插入强制类型转换
- 擦除返回类型后,返回一个Object类型
- 编译器自动插入Employee的强制类型转换
- 编译器将这个方法翻译为两条虚拟机指令
- 对原始方法Pair.getFirst的调用
- 将返回的Object类型强制转换为Employee类型
1 | Pair<Employee> buddies = ...; |
8.5.3 翻译泛型方法
- 在泛型方法中也存在着类型擦除
- 完整的方法族,擦除类型后只剩下一个方法
1 | //泛型方法(完整的方法簇) |
- 桥方法的工作过程:
- 变量pair已经声明为类型Pair<LocalDate>,并且这个类型只有一个简单的方法叫setSecond,即setSecond(Object)
- 虚拟机用pair引用的对象调用这个方法.这个对象是DateInterval类型的,因而将会调用DateInterval.setSecond(Object)方法(合成的桥方法).
- 该方法调用DateInterval.setSecond(Date),正是所期望的操作效果
- 桥方法不仅用于泛型类型
- 一个方法覆盖另一个方法时可以指定一个更严格的返回类型
- 泛型转换的事实:
- 虚拟机中没有泛型,只有普通的类和方法
- 所有的类型参数都用于他们的限定类型替换
- 桥方法被合成用来保持多态
- 为保持类型安全性,必要时插入强制类型转换
8.5.4 调用遗留代码
- 设计泛型的目的:允许泛型代码和遗留代码间能够相互操作
1 | //例子1 |
8.6 约束与局限性
- 泛型编程时,需要注意一些限制
- 大多数限制都是由于类型擦除引起的
8.6.1 不能用基本类型实例化类型参数
- 不能用类型参数代替基本类型
- 没有Pair<double>,只有Pair<Double>
- 原因:类型擦除后,Pair含有Object类型的域,而Object不能存储double值
- 当包装器类型不能接受替换时,可以使用独立的类和方法处理
8.6.2 运行时类型查询只适用于原始类型
- 虚拟机中的对象总有一个特定的非泛型类型,因此所有的类型检查只产生原始类型
- 倘若使用instanceof会得到一个编译器错误,如果使用强制类型转换会得到一个警告
- getClass方法总是返回原始类型
8.6.3 不能创建参数化类型的数组
- 不允许创建参数类型化数组
- 而声明类型为Pair<String>[]的变量仍是合法的
- 不过不能用new Pair<String>[10]初始化这个变量
- 可以声明通配类型的数组,然后进行类型转换
- 如果需要收集参数化类型对象,只有一种安全而有效的方法
- 使用ArrayList:ArrayList<Pair<String>>
8.6.4 Varargs警告
- 向参数个数可变的方法传递一个泛型类型的实例
- 会得到一个警告(与泛型类型数组,不支持泛型类型数组冲突)
- 使用两种方法进行解决
- 一种方法是为包含addAll调用的方法增加注解@SuppressWarnings(“unchecked”)
- 或者在Java SE 7中,还可以用@SafeVarargs直接标注addAll方法
- 可以使用@SafeVarargs标注来消除创建泛型数组的有关限制
8.6.5 不能实例化类型变量
- 不能使用像new T(…), new T[…]或T.class这样的表达式中的类型变量
- 原因:类型擦除将T改为Object,违背本意
- 最好的解决方法:调用者提供一个构造器表达式
- 传统解决方法:通过反射调用Class.newInstance方法构造泛型类型,较为复杂,Class类本身是泛型
1 | Pair<String> p = Pair.makePair(String::new); |
8.6.6 不能构造泛型数组
- 原因:数组本身也有类型,用来监控存储在虚拟机中的数组.(该类型会被擦除)
- 老式方法使用反射进行,调用Array.newInstance
1 | //类型擦除会让这个方法永远构造Comparable[2]数组 |
8.6.7 泛型类的静态上下文中类型变量无效
- 不能在静态域或方法中引用类型变量
8.6.8 不能抛出或捕捉泛型类的实例
- 既不能抛出也不能捕获泛型类对象.实际上,甚至泛型类扩展Throwable都是不合法的
- catch子句中不能使用类型变量(在异常规范中使用类型变量是允许的)
1 | public static <T extends Throwable> void doWork(Class<T> t) |
8.6.9 可以消除对受查异常的检查
- Java异常处理的一个基本原则,必须为所有受查异常提供一个处理器
- 不过可以利用泛型消除这个限制
- 通过使用泛型类,擦除和@SuppressWarnings注解,就能消除Java类型系统的部分基本限制
8.6.10 注意擦除后的冲突
- 当泛型类型被擦除时,无法创建引发冲突的条件
- 要想支持擦除的转换,就需要强行限制一个类或类型变量不能同时成为两个接口类型的子类,而这两个接口是同一接口的不同参数化
8.7 泛型类型的继承规则
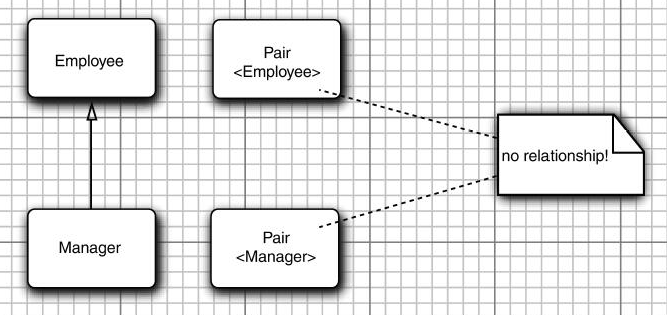
- Employee是Manager的超类
- Pair<Employee>与Pair<Manager>没有任何关系
- 注意泛型与Java数组之间的区别
- 可以将一个Manager[]数组赋给一个类型为Employee[]的变量,数组带有特别的保护
- 如果试图将一个低级别的雇员存储到employeeBuddies[0],虚拟机将会抛出ArrayStoreException异常
- 永远可以将参数化类型转换为一个原始类型
- 例如,Pair<Employee>是原始类型Pair的一个子类型.
- 在与遗留代码衔接时,这个转换非常必要
- 转换成原始类型之后不会产生类型错误
- 当使用getFirst获得外来对象并赋给Manager变量时,与通常一样,会抛出ClassCastException异常
- 失去的只是泛型程序设计提供的附加安全性
- 泛型类可以扩展或实现其他的泛型类
8.8 通配符类型
8.8.1 通配符概念
- 通配符类型中,允许类型参数变化
- 引入有限定的通配符的关键之处,可以用来区分安全的访问器方法和不安全的更改器方法
1 | Pair<? extends Employee> |
8.8.2 通配符的超类型限定
- 通配符限定与类型变量限定十分类似
- 但是,还有一个附加的能力,即可以指定一个超类型限定
- 带有超类型限定的通配符可以为方法提供参数,但不能使用返回值
- 带有超类型限定的通配符可以向泛型对象写入,带有子类型限定的通配符可以从泛型对象读取
1 | //Pair<? super Manager>有方法 |
8.8.3 无限定通配符
- 使用无限定的通配符,例如,Pair<?>
- Pair<?>和Pair本质的不同在于
- 可以用任意Object对象调用原始Pair类的setObject方法
- 可以调用setFirst(null)
- 该类型对简单的测试操作有用
1 | //例如 |
8.8.4 通配符捕获
1 | //编写一个交换成对元素的方法 |
- 通配符捕获只有在有许多限制的情况下才是合法的
- 编译器必须能够确信通配符表达的是单个,确定的类型
8.9 反射和泛型
8.9.1 泛型Class类
- Class类是泛型的
- String.class实际上是Class<String>类的唯一对象
- 类型参数十分有用,它允许Class<T>方法的返回类型更加具有针对性
8.9.2 使用Class<T>参数进行类型匹配
1 | //有时,匹配泛型方法中的Class<T>参数的类型变量很有实用价值 |
8.9.3 虚拟机中的泛型类型信息
- Java泛型的卓越特性之一是在虚拟机中泛型类型的擦除
- 但擦除的类仍然保留一些泛型祖先的微弱记忆
9 集合
9.1 Java集合框架
- 使用标准库中的集合类
- Java最初版本只为最常用的数据结构提供了一组类:Vector,Stack,Hashtable,BitSet与Enumeration接口
- 其中的Enumeration接口提供了一种用于访问任意容器中各个元素的抽象机制
9.1.1 将集合的接口与实现分离
- Java集合类库将接口与实现分开
- 以队列为例
- 队列接口指出可以在队列的尾部添加元素,在队列的头部删除元素,并且可以查找队列中元素的个数
- 当需要收集对象,并按照“先进先出”的规则检索对象时就应该使用队列
- 队列的实现形式一般由两种:循环数组,或者链表
- 每一个实现都可以通过一个实现了Queue接口的类表示
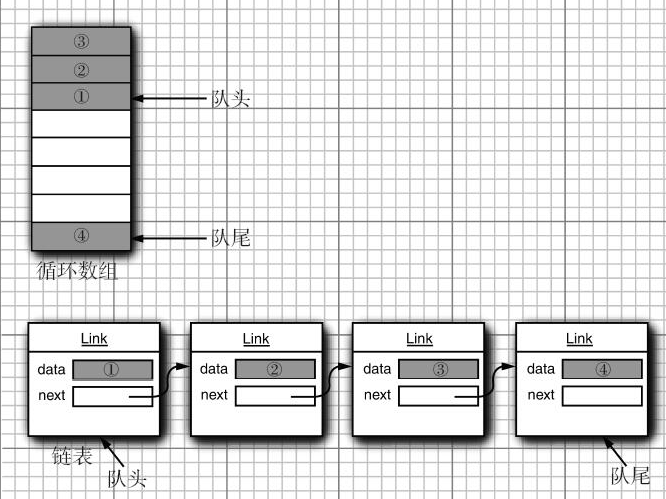
- 每一个实现都可以通过一个实现了Queue接口的类表示
1 | //队列接口的最简单形式 |
- 需要循环数组队列,使用ArrayDeque类
- 需要链表队列,使用LinkedList类,这个类实现了Queue接口
- 循环数组要比链表更高效
- 循环数组是一个有界集合,即容量有限
- 如果程序中要收集的对象数量没有上限,就最好使用链表来实现
- 以Abstract开头的类,例如,AbstractQueue,是为类库实现者而设计的
- 如果要实现自己的队列类扩展AbstractQueue类要比实现Queue接口中的所有方法轻松得多
9.1.2 Collection接口
- 在Java类库中,集合类的基本接口是Collection接口
1 | public interface Collection<E> { |
9.1.3 迭代器
1 | //Iterator接口的四个方法: |
-
编译器简单的将“for each”循环翻译为带有迭代器的循环
-
“for each”循环可以与任何实现了Iterable接口的对象一起工作
-
Collection接口扩展了Iterable接口,对于标准类库中的任何集合都可以使用“for each”循环
-
元素被访问的顺序取决于集合类型
- 如果对ArrayList进行迭代,迭代器将从索引0开始,每迭代一次,索引值加1
- 如果访问HashSet中的元素,每个元素将会按照某种随机的次序出现。
- 虽然可以确定在迭代过程中能够遍历到集合中的所有元素,但却无法预知元素被访问的次序
- 这对于计算总和或统计符合某个条件的元素个数这类与顺序无关的操作来说,并不是什么问题
-
Iterator接口的next和hasNext方法与Enumeration接口的nextElement和hasMoreElements方法的作用一样
-
可以将Iterator.next与InputStream.read看作为等效的
-
从数据流中读取一个字节,就会自动地“消耗掉”这个字节。下一次调用read将会消耗并返回输入的下一个字节。用同样的方式,反复地调用next就可以读取集合中所有元素
1 | //Iterator接口的remove方法将会删除上次调用next方法时返回的元素 |
9.1.4 泛型实用方法
- 由于Collection与Iterator都是泛型接口,可以编写操作任何集合类型的实用方法
1 | //检测任意集合是否包含指定元素的泛型方法 |
9.1.5 集合框架中的接口
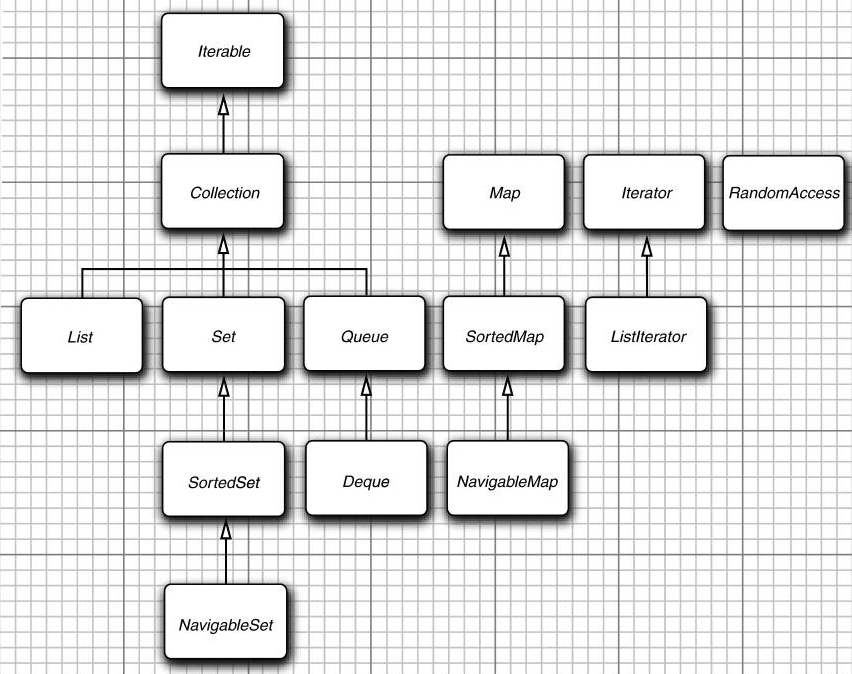
-
集合有两个基本接口
- Collection
- Map
-
List是一个有序集合,元素会增加到容器中的特定位置
-
可以采用两种方式访问元素:
- 使用迭代器访问
- 或使用一个整数索引来访问(随机访问)
1 | //可以使用add方法在集合中插入元素 |
-
由数组支持的有序集合可以快速地随机访问,因此适合使用List方法并提供一个整数索引来访问
-
与之不同,链表尽管也是有序的,但是随机访问很慢,所以最好使用迭代器来遍历
- 为了避免对链表完成随机访问操作,Java SE 1.4引入了一个标记接口RandomAccess
- 这个接口不包含任何方法,不过可以用它来测试一个特定的集合是否支持高效的随机访问
-
Set接口等同于Collection接口
- 集(set)的add方法不允许增加重复的元素。要适当地定义集的equals方法:只要两个集包含同样的元素就认为是相等的,而不要求这些元素有同样的顺序。
- hashCode方法的定义要保证包含相同元素的两个集会得到相同的散列码
-
既然方法签名是一样的,为什么还要建立一个单独的接口呢?
- 从概念上讲,并不是所有集合都是集。建立一个Set接口可以让程序员编写只接受集的方法
-
SortedSet和SortedMap接口会提供用于排序的比较器对象,这两个接口定义了可以得到集合子集视图的方法
-
Java SE 6引入了接口NavigableSet和NavigableMap,其中包含一些用于搜索和遍历有序集和映射的方法
-
TreeSet和TreeMap类实现了这些接口
- 理想情况下,这些方法本应当直接包含在SortedSet和SortedMap接口中
9.2 具体的集合
- 除了以Map结尾的类之外,其他类都实现了Collection接口
- 以Map结尾的类,实现了Map接口

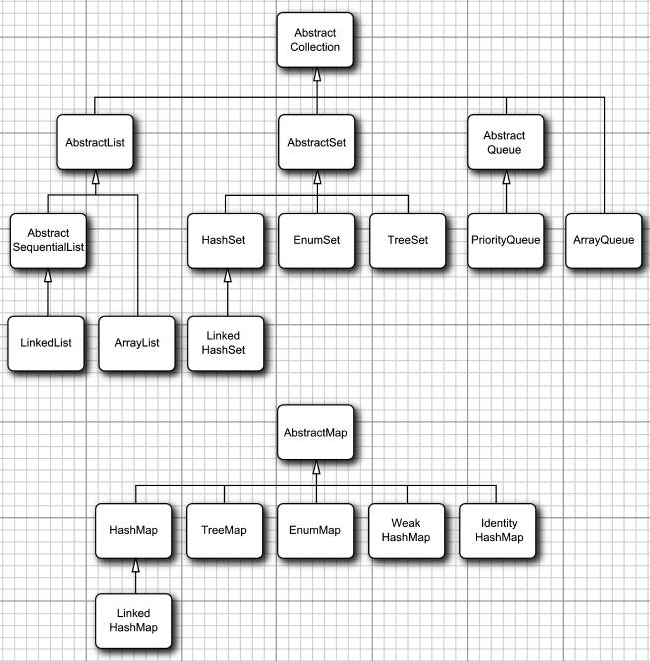
9.2.1 链表
-
数组及动态ArrayList类,存在重大缺陷,在中间位置删除元素(或添加元素)困难
- 原因:数组中处于被删除元素之后的所有元素都要向数组的前端移动
-
链表可以解决这个问题
- 链表的每个对象存放在独立的结点上,每个结点上还存放着序列中下一个结点的引用
- Java中的链表为双向链表,每个结点还存放着指向前驱结点的引用
- 删除一个元素即更新被删除元素附近的链接
-
集合库中LinkedList类用于实现链表的操作
1 | //先添加3个元素,然后将第2个元素删除 |
-
链表与泛型集合之间有一个重要的区别
- 链表是一个有序集合,每个对象的位置十分重要。LinkedList.add方法将对象添加到链表的尾部。但是,常常需要将元素添加到链表的中间。由于迭代器是描述集合中位置的,所以这种依赖于位置的add方法将由迭代器负责。只有对自然有序的集合使用迭代器添加元素才有实际意义
- 集(set)类型,其中的元素完全无序
- 在Iterator接口中就没有add方法。相反地,集合类库提供了子接口ListIterator,其中包含add方法
-
add方法只依赖于迭代器的位置,而remove方法依赖于迭代器的状态
-
set方法用一个新元素取代调用next或previous方法返回的上一个元素
-
如果在某个迭代器修改集合时,另一个迭代器对其进行遍历,一定会出现混乱的状况
-
例如,一个迭代器指向另一个迭代器刚刚删除的元素前面,现在这个迭代器就是无效的,并且不应该再使用。链表迭代器的设计使它能够检测到这种修改。如果迭代器发现它的集合被另一个迭代器修改了,或是被该集合自身的方法修改了,就会抛出一个ConcurrentModificationException异常
-
可以根据需要给容器附加许多的迭代器,但是这些迭代器只能读取列表。另外,再单独附加一个既能读又能写的迭代器
-
有一种简单的方法可以检测到并发修改的问题。集合可以跟踪改写操作(诸如添加或删除元素)的次数。每个迭代器都维护一个独立的计数值。在每个迭代器方法的开始处检查自己改写操作的计数值是否与集合的改写操作计数值一致。如果不一致,抛出一个Concurrent ModificationException异常
-
链表只负责跟踪对列表的结构性修改,例如,添加元素、删除元素。set方法不被视为结构性修改
-
链表不支持快速地随机访问
-
LinkedList对象根本不做任何缓存位置信息的操作
-
列表迭代器接口还有一个方法,可以告之当前位置的索引
-
实际上,从概念上讲,由于Java迭代器指向两个元素之间的位置,所以可以同时产生两个索引:
- nextIndex方法返回下一次调用next方法时返回元素的整数索引
- previousIndex方法返回下一次调用previous方法时返回元素的整数索引。当然,这个索引只比nextIndex返回的索引值小1
-
list.listIterator(n)将返回一个迭代器,这个迭代器指向索引为n的元素前面的位置。也就是说,调用next与调用list.get(n)会产生同一个元素,只是获得这个迭代器的效率比较低
-
使用链表的唯一理由是尽可能地减少在列表中间插入或删除元素所付出的代价。如果列表只有少数几个元素,就完全可以使用ArrayList
-
免使用以整数索引表示链表中位置的所有方法。如果需要对集合进行随机访问,就使用数组或ArrayList,而不要使用链表
9.2.2 数组列表
- List接口用于描述一个有序集合,并且集合中每个元素的位置十分重要。有两种访问元素的协议:一种是用迭代器,另一种是用get和set方法随机地访问每个元素。后者不适用于链表,但对数组却很有用
- ArrayList封装了一个动态再分配的对象数组
- Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象。但是,如果由一个线程访问Vector,代码要在同步操作上耗费大量的时间。这种情况还是很常见的。而ArrayList方法不是同步的,因此,建议在不需要同步时使用ArrayList,而不要使用Vector
9.2.3 散列集
- 可以快速地查找所需要的对象,这就是散列表
- 散列表为每个对象计算一个整数,称为散列码。散列码是由对象的实例域产生的一个整数。更准确地说,具有不同数据域的对象将产生不同的散列码
- 最重要的问题是散列码要能够快速地计算出来,并且这个计算只与要散列的对象状态有关,与散列表中的其他对象无关
- 在Java中,散列表用链表数组实现。每个列表被称为桶。要想查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引
- 有时候会遇到桶被占满的情况,这也是不可避免的。这种现象被称为散列冲突
- 这时,需要用新对象与桶中的所有对象进行比较,查看这个对象是否已经存在。如果散列码是合理且随机分布的,桶的数目也足够大,需要比较的次数就会很少
- 如果想更多地控制散列表的运行性能,就要指定一个初始的桶数。桶数是指用于收集具有相同散列值的桶的数目。如果要插入到散列表中的元素太多,就会增加冲突的可能性,降低运行性能
- 通常,将桶数设置为预计元素个数的75%~150%
- 有些研究人员认为:尽管还没有确凿的证据,但最好将桶数设置为一个素数,以防键的集聚。标准类库使用的桶数是2的幂,默认值为16
- 如果散列表太满,就需要再散列。如果要对散列表再散列,就需要创建一个桶数更多的表,并将所有元素插入到这个新表中,然后丢弃原来的表。装填因子决定何时对散列表进行再散列
- 对于大多数应用程序来说,装填因子为0.75是比较合理的
- 散列表可以用于实现几个重要的数据结构。其中最简单的是set类型。set是没有重复元素的元素集合。set的add方法首先在集中查找要添加的对象,如果不存在,就将这个对象添加进去
- Java集合类库提供了一个HashSet类,它实现了基于散列表的集。可以用add方法添加元素。contains方法已经被重新定义,用来快速地查看是否某个元素已经出现在集中。它只在某个桶中查找元素,而不必查看集合中的所有元素
- 只有不关心集合中元素的顺序时才应该使用HashSet
9.2.4 树集
- 树集是一个有序集合;可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值将自动地按照排序后的顺序呈现
- 正如TreeSet类名所示,排序是用树结构完成的(当前实现使用的是红黑树(red-black tree)
- 要使用树集,必须能够比较元素。这些元素必须实现Comparable接口,或者构造集时必须提供一个Comparator
- 将一个元素添加到树中要比添加到散列表中慢。但是,与检查数组或链表中的重复元素相比还是快很多。如果树中包含n个元素,查找新元素的正确位置平均需要log2n次比较
- 从Java SE 6起,TreeSet类实现了NavigableSet接口。这个接口增加了几个便于定位元素以及反向遍历的方法
- 树集和散列集的区别?
- 如果不需要对数据进行排序,就没有必要付出排序的开销。更重要的是,对于某些数据来说,对其排序要比散列函数更加困难。散列函数只是将对象适当地打乱存放,而比较却要精确地判别每个对象
9.2.5 队列与双端队列
Java SE 6中引入了Deque接口,并由ArrayDeque和LinkedList类实现。这两个类都提供了双端队列,而且在必要时可以增加队列的长度
9.2.6 优先级队列
- 优先级队列中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。也就是说,无论何时调用remove方法,总会获得当前优先级队列中最小的元素。然而,优先级队列并没有对所有的元素进行排序。如果用迭代的方式处理这些元素,并不需要对它们进行排序
- 优先级队列使用了一个优雅且高效的数据结构,称为堆
- 堆是一个可以自我调整的二叉树,对树执行添加(add)和删除(remore)操作,可以让最小的元素移动到根,而不必花费时间对元素进行排序
- 与TreeSet一样,一个优先级队列既可以保存实现了Comparable接口的类对象,也可以保存在构造器中提供的Comparator对象
- 使用优先级队列的典型示例是任务调度。每一个任务有一个优先级,任务以随机顺序添加到队列中。每当启动一个新的任务时,都将优先级最高的任务从队列中删除(由于习惯上将1设为“最高”优先级,所以会将最小的元素删除)
9.3 映射
- 集是一个集合,它可以快速地查找现有的元素。但是,要查看一个元素,需要有要查找元素的精确副本。这不是一种非常通用的查找方式
- 映射用来存放键/值对。如果提供了键,就能够查找到值
9.3.1 基本映射操作
-
Java类库为映射提供了两个通用的实现:
- HashMap和TreeMap
- 这两个类都实现了Map接口
-
散列映射对键进行散列,树映射用键的整体顺序对元素进行排序,并将其组织成搜索树
-
散列或比较函数只能作用于键。与键关联的值不能进行散列或比较
-
应该选择散列映射还是树映射呢?
-
与集一样,散列稍微快一些,如果不需要按照排列顺序访问键,就最好选择散列
1 | //为存储的员工信息建立一个散列映射 |
9.3.2 更新映射项
- 处理映射时的一个难点就是更新映射项
- 正常情况下,可以得到与一个键关联的原值,完成更新,再放回更新后的值
- 考虑一个特殊情况,即键第一次出现
1 | //使用一个映射统计一个单词在文件中出现的频度。看到一个单词(word)时,计数器增1 |
9.3.3 映射视图
- 集合框架不认为映射本身是一个集合。(其他数据结构框架认为映射是一个键/值对集合,或者是由键索引的值集合。)
- 不过,可以得到映射的视图,这是实现了Collection接口或某个子接口的对象
- 有3种视图:键集、值集合(不是一个集)以及键/值对集
- 键和键/值对可以构成一个集,因为映射中一个键只能有一个副本
1 | //分别返回键集、值集合(不是一个集)以及键/值对集 |
9.3.4 弱散列映射
- 设计WeakHashMap类是为了解决一个有趣的问题
- 如果有一个值,对应的键已经不再使用了,将会出现什么情况呢?假定对某个键的最后一次引用已经消亡,不再有任何途径引用这个值的对象了。但是,由于在程序中的任何部分没有再出现这个键,所以,这个键/值对无法从映射中删除
- 垃圾回收器跟踪活动的对象。只要映射对象是活动的,其中的所有桶也是活动的,它们不能被回收
- 当对键的唯一引用来自散列条目时,这一数据结构将与垃圾回收器协同工作一起删除键/值对
- WeakHashMap使用弱引用(weak references)保存键。WeakReference对象将引用保存到另外一个对象中,在这里,就是散列键。对于这种类型的对象,垃圾回收器用一种特有的方式进行处理。通常,如果垃圾回收器发现某个特定的对象已经没有他人引用了,就将其回收。然而,如果某个对象只能由WeakReference引用,垃圾回收器仍然回收它,但要将引用这个对象的弱引用放入队列中。WeakHashMap将周期性地检查队列,以便找出新添加的弱引用。一个弱引用进入队列意味着这个键不再被他人使用,并且已经被收集起来。于是,WeakHashMap将删除对应的条目
9.3.5 链接散列集与映射
- LinkedHashSet和LinkedHashMap类用来记住插入元素项的顺序。这样就可以避免在散列表中的项从表面上看是随机排列的。当条目插入到表中时,就会并入到双向链表中
- 访问顺序对于实现高速缓存的“最近最少使用”原则十分重要
9.3.6 枚举集与映射
- EnumSet是一个枚举类型元素集的高效实现。由于枚举类型只有有限个实例,所以EnumSet内部用位序列实现。如果对应的值在集中,则相应的位被置为1
- EnumMap是一个键类型为枚举类型的映射。它可以直接且高效地用一个值数组实现。
1 | //EnumSet类没有公共的构造器。可以使用静态工厂方法构造这个集 |
9.3.7 标识散列映射
- 类IdentityHashMap有特殊的作用
- 在这个类中,键的散列值不是用hashCode函数计算的,而是用System.identityHashCode方法计算的
- 这是Object.hashCode方法根据对象的内存地址来计算散列码时所使用的方式。而且,在对两个对象进行比较时,IdentityHashMap类使用==,而不使用equals
- 也就是说,不同的键对象,即使内容相同,也被视为是不同的对象。在实现对象遍历算法(如对象串行化)时,这个类非常有用,可以用来跟踪每个对象的遍历状况
9.4 视图与包装器
- 通过使用视图可以获得其他的实现了Collection接口和Map接口的对象
- keySet方法返回一个实现Set接口的类对象,这个类的方法对原映射进行操作。这种集合称为视图。
9.4.1 轻量级集合包装器
1 | //Arrays类的静态方法asList将返回一个包装了普通Java数组的List包装器 |
9.4.2 子范围
- 可以为很多集合建立子范围视图
1 | //假设有一个列表staff,想从中取出第10个~第19个元素。可以使用subList方法来获得一个列表的子范围视图 |
9.4.3 不可修改的视图
-
Collections还有几个方法,用于产生集合的不可修改视图
-
这些视图对现有集合增加了一个运行时的检查。如果发现试图对集合进行修改,就抛出一个异常,同时这个集合将保持未修改的状态
-
不可修改视图并不是集合本身不可修改
- 仍然可以通过集合的原始引用对集合进行修改。并且仍然可以让集合的元素调用更改器方法
-
由于视图只是包装了接口而不是实际的集合对象,所以只能访问接口中定义的方法
- 例如,LinkedList类有一些非常方便的方法,addFirst和addLast,它们都不是List接口的方法,不能通过不可修改视图进行访问
-
警告:unmodifiableCollection方法(与本节稍后讨论的synchronizedCollection和checked Collection方法一样)将返回一个集合,它的equals方法不调用底层集合的equals方法
-
相反,它继承了Object类的equals方法,这个方法只是检测两个对象是否是同一个对象。如果将集或列表转换成集合,就再也无法检测其内容是否相同了。视图就是以这种方式运行的,因为内容是否相等的检测在分层结构的这一层上没有定义妥当。视图将以同样的方式处理hashCode方法。
-
然而,unmodifiableSet类和unmodifiableList类却使用底层集合的equals方法和hashCode方法
1 | //获得不可修改的视图 |
9.4.4 同步视图
- 如果由多个线程访问集合,就必须确保集不会被意外地破坏
- 例如,如果一个线程试图将元素添加到散列表中,同时另一个线程正在对散列表进行再散列,其结果将是灾难性的
- 类库的设计者使用视图机制来确保常规集合的线程安全,而不是实现线程安全的集合类
1 | //例如,Collections类的静态synchronizedMap方法可以将任何一个映射表转换成具有同步访问方法的Map |
9.4.5 受查视图
- “受查”视图用来对泛型类型发生问题时提供调试支持
1 | //将错误类型的元素混入泛型集合中的问题极有可能发生 |
9.4.6 关于可选操作的说明
- 通常,视图有一些局限性,即可能只可以读、无法改变大小、只支持删除而不支持插入,这些与映射的键视图情况相同
- 如果试图进行不恰当的操作,受限制的视图就会抛出一个UnsupportedOperationException
- 是否应该将“可选”方法这一技术扩展到用户的设计中呢?
- 我们认为不应该。尽管集合被频繁地使用,其实现代码的风格也未必适用于其他问题领域。集合类库的设计者必须解决一组特别严格且又相互冲突的需求。用户希望类库应该易于学习、使用方便,彻底泛型化,面向通用性,同时又与手写算法一样高效。要同时达到所有目标的要求,或者尽量兼顾所有目标完全是不可能的。但是,在自己的编程问题中,很少遇到这样极端的局限性。应该能够找到一种不必依靠极端衡量“可选的”接口操作来解决这类问题的方案
9.5 算法
- 泛型集合接口具有一个很大的优点:算法只需要实现一次
9.5.1 排序与混排
- Collections类中的sort方法可以对实现了List接口的集合进行排序
- 排序算法接收的列表,必须是可以修改的,但不必是可以改变大小的
- 如果列表支持set方法,则是可修改的
- 如果列表支持add和remove方法,则是可改变大小的
1 | //Collections类中的sort方法排序,该假定列表元素实现了Comparable接口 |
9.5.2 二分查找
- 要想在数组中查找一个对象,通常要依次访问数组中的每个元素,直到找到匹配的元素为止
- 如果数组是有序的,就可以直接查看位于数组中间的元素,看一看是否大于要查找的元素
- 如果是,用同样的方法在数组的前半部分继续查找;
- 否则,用同样的方法在数组的后半部分继续查找。这样就可以将查找范围缩减一半
- Collections类的binarySearch方法实现了这个算法
- 注意,集合必须是排好序的,否则算法将返回错误的答案
- 要想查找某个元素,必须提供集合
- (这个集合要实现List接口,如果集合没有采用Comparable接口的compareTo方法进行排序,就还要提供一个比较器对象)
- 只有采用随机访问,二分查找才有意义
- 如果必须利用迭代方式一次次地遍历链表的一半元素来找到中间位置的元素,二分查找就完全失去了优势
- 因此,如果为binarySearch算法提供一个链表,它将自动地变为线性查找
1 | i = Collections.binarySearch(c, element); |
- 从有序列表中搜索一个键,如果元素扩展了AbstractSequentialList类,则采用线性查找,否则将采用二分查找。
- 二分查找的时间复杂度为O(a(n)log n),n是列表的长度,a(n)是访问一个元素的平均时间。这个方法将返回这个键在列表中的索引,如果在列表中不存在这个键将返回负值i。在这种情况下,应该将这个键插入到列表索引—i—1的位置上,以保持列表的有序性
9.5.3 简单算法
- 其他的简单算法:
- 将一个列表中的元素复制到另外一个列表中
- 用一个常量值填充容器
- 逆置一个列表的元素顺序
- Java SE 8增加了默认方法Collection.removeIf和List.replaceAll,这两个方法需要提供一个lambda表达式来测试或转换元素
9.5.4 批操作
1 | //很多操作会成批复制或删除元素 |
9.5.5 集合与数组的转换
-
如果需要把一个数组转换为集合,Arrays.asList包装器可以达到这个目的
-
从集合得到数组会更困难一些。当然,可以使用toArray方法
- 不过,这样做的结果是一个对象数组。
- 尽管你知道集合中包含一个特定类型的对象,但不能使用强制类型转换
- toArray方法返回的数组是一个Object[]数组,不能改变它的类型。实际上,必须使用toArray方法的一个变体形式,提供一个所需类型而且长度为0的数组。这样一来,返回的数组就会创建为相同的数组类型
-
为什么不能直接将一个Class对象(如String.class)传递到toArray方法
- 原因是这个方法有“双重职责”,不仅要填充一个已有的数组,还要创建一个新数组
1 | //数组转换为集合 |
9.5.6 编写自己的算法
- 编写自己的算法(实际上,是以集合作为参数的任何方法),应该尽可能地使用接口,而不要使用具体的实现
9.6 遗留的集合
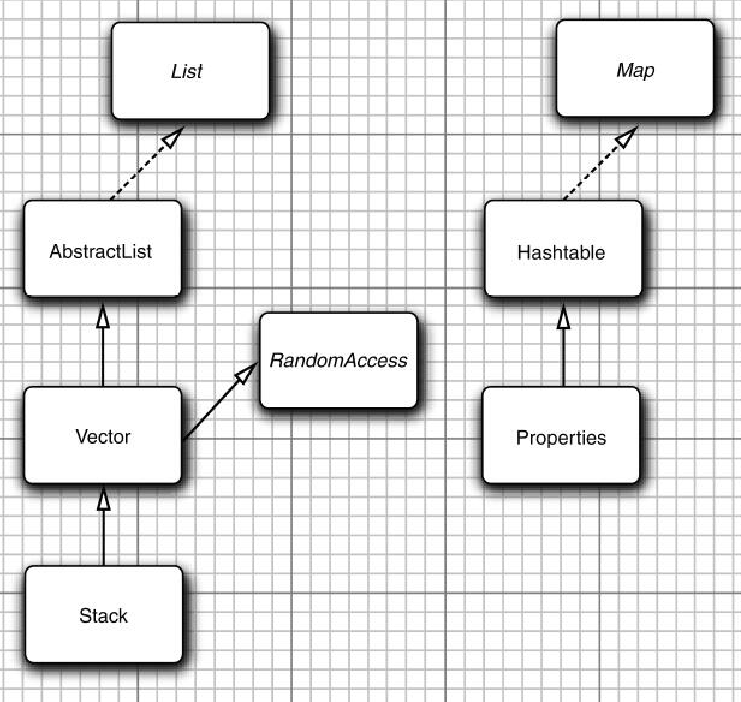
9.6.1 Hashtable类
- Hashtable类与HashMap类的作用一样,实际上,它们拥有相同的接口。
- 与Vector类的方法一样。Hashtable的方法也是同步的。
- 如果对同步性或与遗留代码的兼容性没有任何要求,就应该使用HashMap。
- 如果需要并发访问,则要使用ConcurrentHashMap
9.6.2 枚举
- 遗留集合使用Enumeration接口对元素序列进行遍历
- Enumeration接口有两个方法,即hasMoreElements和nextElement
- 这两个方法与Iterator接口的hasNext方法和next方法十分类似
1 | //Hashtable类的elements方法将产生一个用于描述表中各个枚举值的对象 |
9.6.3 属性映射
- 属性映射(property map)是一个类型非常特殊的映射结构
- 它有下面3个特性:
- 键与值都是字符串
- 表可以保存到一个文件中,也可以从文件中加载
- 使用一个默认的辅助表。
- 实现属性映射的Java平台类称为Properties。
- 属性映射通常用于程序的特殊配置选项
9.6.4 栈
- 标准类库中就包含了Stack类,其中有大家熟悉的push方法和pop方法
- 但是,Stack类扩展为Vector类,从理论角度看,Vector类并不太令人满意,它可以让栈使用不属于栈操作的insert和remove方法,即可以在任何地方进行插入或删除操作,而不仅仅是在栈顶
9.6.5 位集
- Java平台的BitSet类用于存放一个位序列(它不是数学上的集,称为位向量或位数组更为合适)
- 如果需要高效地存储位序列(例如,标志)就可以使用位集
- 由于位集将位包装在字节里,所以,使用位集要比使用Boolean对象的ArrayList更加高效
- BitSet类提供了一个便于读取、设置或清除各个位的接口
- 使用这个接口可以避免屏蔽和其他麻烦的位操作
1 | //名为buckerOfBits的BitSet |
13 部署Java应用程序
- 首先介绍打包应用的指令
- 然后展示应用如何存储配置信息和用户首选项
- 另外还会学习如何使用ServiceLoader类在应用中加载插件
- 讨论applet,介绍创建或维护applet时需要了解的有关知识(已过时,忽略)
- 讨论Java Web Start机制——这是一种基于Internet的应用发布方法,很多方面都与applet很类似,不过更适合不在Web页面中的程序
13.1 JAR文件
- 一个JAR文件既可以包含类文件,也可以包含诸如图像和声音这些其他类型的文件
- 此外,JAR文件是压缩的,它使用了大家熟悉的ZIP压缩格式
- pack200是一种较通常的ZIP压缩算法更加有效的压缩类文件的方式
13.1.1 创建JAR文件
- 可以使用jar工具制作JAR文件(在默认的JDK安装中,位于jdk/bin目录下)
- 可以将应用程序、程序组件以及代码库打包在JAR文件中
1 | //创建一个新的JAR文件应该使用的常见命令格式为 |
13.1.2 清单文件
- 除了类文件、图像和其他资源外,每个JAR文件还包含一个用于描述归档特征的清单文件
- 清单文件被命名为MANIFEST.MF,它位于JAR文件的一个特殊METANF子目录中
1 | //创建一个包含清单文件的Jar文件 |
13.1.3 可执行JAR文件
- 可以使用jar命令中的e选项指定程序的入口点,即通常需要在调用java程序加载器时指定的类
- 或者,可以在清单中指定应用程序的主类
- 不要将扩展名.class添加到主类名中
- 清单文件的最后一行必须以换行符结束.否则,清单文件将无法被正确地读取
- 常见的错误是创建了一个只包含Main-Class而没有行结束符的文本文件
13.1.4 资源
- 利用资源机制,对于非类文件也可以同样方便地进行操作.下面是必要的步骤
- 获得具有资源的Class对象,例如,AboutPanel.class
- 如果资源是一个图像或声音文件,那么就需要调用getresource(filename)获得作为URL的资源位置,然后利用getImage或getAudioClip方法进行读取
- 与图像或声音文件不同,其他资源可以使用getResourceAsStream方法读取文件中的数据.
- 重点在于类加载器可以记住如何定位类,然后在同一位置查找关联的资源
13.1.5 密封
- 可以将Java包密封(seal)以保证不会有其他的类加入到其中
- 如果在代码中使用了包可见的类、方法和域,就可能希望密封包
- 如果不密封,其他类就有可能放在这个包中,进而访问包可见的特性
13.2 应用首选项的存储
- 应用用户通常希望能保存他们的首选项和定制信息,以后再次启动应用时再恢复这些配置
13.2.1 属性映射
- 属性映射是一种存储键/值对的数据结构
- 属性映射通常用来存储配置信息,它有3个特性:
- 键和值是字符串
- 映射可以很容易地存入文件以及从文件加载
- 有一个二级表保存默认值
- 属性映射通常用来存储配置信息,它有3个特性:
- 实现属性映射的Java类名为Properties
- 属性映射对于指定程序的配置选项很有用
- 可以使用store方法将属性映射列表保存到一个文件中
- 习惯上,会把程序属性存储在用户主目录的一个子目录中
- 目录名通常以一个点号开头(在UNIX系统中),这个约定说明这是一个对用户隐藏的系统目录
- 要找出用户的主目录,可以调用System.getProperties方法,它恰好也使用一个Properties对象描述系统信息
- 主目录包含键“user.home”
13.2.2 首选项API
- 使用属性文件有以下缺点:
- 有些操作系统没有主目录的概念,所以很难找到一个统一的配置文件位置
- 关于配置文件的命名没有标准约定,用户安装多个Java应用时,就更容易发生命名冲突
13.3 服务加载器
- 通常,提供一个插件时,程序希望插件设计者能有一些自由来确定如何实现插件的特性
- 另外还可以有多个实现以供选择.利用ServiceLoader类可以很容易地加载符合一个公共接口的插件
13.5 Java Web Start
- Java Web Start应用程序包含下列主要特性:
- 应用程序一般通过浏览器发布.只要Java Web Start应用程序下载到本地就可以启动它,而不需要浏览器
- 应用程序并不在浏览器窗口内.它将显示在浏览器外的一个属于自己的框架中
- 应用程序不使用浏览器的Java实现.浏览器只是在加载Java Web Start应用程序描述符时启动一个外部应用程序
- 数字签名应用程序可以被赋予访问本地机器的任意权限.未签名的应用程序只能运行在“沙箱”中,它可以阻止具有潜在危险的操作
13.5.1 发布Java Web Start应用
- 要想准备一个通过Java Web Start发布的应用程序,应该将其打包到一个或多个JAR文件中
- 然后创建一个Java Network Launch Protocol(JNLP)格式的描述符文件.将这些文件放置在Web服务器上
- 还需要确保Web服务器对扩展名为.jnlp的文件报告一个application/x-java-jnlp-file的MIME类型(浏览器利用MIME类型确定启动哪一种辅助应用程序)
- 步骤:
- 编译程序
- 创建JAR文件:
- 准备启动文件Calculator.jnlp
- 如果使用Tomcat则在Tomcat安装的根目录上创建一个目录tomcat/webapps/calculator.创建子目录tomcat/webapps/calculator/WEBNF,并且将最小的web.xml文件放置在WEBNF子目录下
- 将JAR文件和启动文件放入tomcat/webapps/calculator目录
- 在Java控制面板中将URL增加到可信站点列表.或者,可以为JAR文件签名.
- 在tomcat/bin目录执行启动脚本来启动Tomcat.
- 将浏览器指向JNLP文件.如果你的浏览器不知道如何处理JNLP文件,可能会提供一个选项将它们与一个应用关联.如果是这样,请选择jdk/bin/javaws.否则,明确如何将MIME类型application/x-java-jnlp-file与javaws应用关联.还可以试着重新安装可以做到这一点的JDK.
- 稍后,计算器就会出现,所带的边框表明这是一个Java应用程序
- 当再次访问JNLP文件时,应用程序将从缓存中取出.可以利用Java插件控制面板查看缓存内容.在Windows系统的Windows控制面板中可以看到Java插件控制面板.在Linux下,可以运行jdk/jre/bin/ControlPanel
13.5.2 JNLP API
- JNLP API允许未签名的应用程序在沙箱中运行,同时通过一种安全的途径访问本地资源
- API提供了下面的服务:
- 加载和保存文件
- 访问剪贴板
- 打印
- 下载文件
- 在默认的浏览器中显示一个文档
- 保存和获取持久性配置信息
- 确信只运行一个应用程序的实例
14 并发
- 进程与多线程有哪些区别呢
- 本质的区别在于每个进程拥有自己的一整套变量,而线程则共享数据
14.1 什么是线程
- 调用Thread.sleep不会创建一个新线程
- sleep是Thread类的静态方法,用于暂停当前线程的活动
- sleep方法可以抛出一个InterruptedException异常
14.1.1 使用进程给其他任务提供机会
- 一个单独的线程中执行一个任务的简单过程
- 将任务代码移到实现了Runnable接口的类的run方法中
- 由Runnable创建一个Thread对象
- 启动线程
1 | //Runnable接口,只有一个方法 |
- 不要调用Thread类或Runnable对象的run方法
- 直接调用run方法,只会执行同一个线程中的任务,而不会启动新线程
- 应该调用Thread.start方法。这个方法将创建一个执行run方法的新线程
14.2 中断线程
- 当线程的run方法执行方法体中最后一条语句后,并经由执行return语句返回时,或者出现了在方法中没有捕获的异常时,线程将终止
- 在Java的早期版本中,还有一个stop方法,其他线程可以调用它终止线程,这个方法现在已经被弃用了
- interrupt方法可以用来请求终止线程
- 当对一个线程调用interrupt方法时,线程的中断状态将被置位
- 这是每一个线程都具有的boolean标志。每个线程都应该不时地检查这个标志,以判断线程是否被中断
- 要想弄清中断状态是否被置位,首先调用静态的Thread.currentThread方法获得当前线程,然后调用isInterrupted方法
1 | //isInterrupted方法 |
- 有两个非常类似的方法,interrupted和isInterrupted
- Interrupted方法是一个静态方法,它检测当前的线程是否被中断
- 而且,调用interrupted方法会清除该线程的中断状态
- isInterrupted方法是一个实例方法,可用来检验是否有线程被中断
- 调用这个方法不会改变中断状态
14.3 线程状态
- 线程有6种状态
- New(新创建)
- Runnable(可运行)
- Blocked(被阻塞)
- Waiting(等待)
- Timed waiting(计时等待)
- Terminated(被终止)
14.3.1 新创建线程
- 当用new操作符创建一个新线程时,如new Thread®,该线程还没有开始运行
- 这意味着它的状态是new
- 当一个线程处于新创建状态时,程序还没有开始运行线程中的代码。在线程运行之前还有一些基础工作要做
14.3.2 可运行线程
- 一旦调用start方法,线程处于runnable状态
- 一个可运行的线程可能正在运行也可能没有运行
- 一个正在运行中的线程仍然处于可运行状态
- 一旦一个线程开始运行,它不必始终保持运行。事实上,运行中的线程被中断,目的是为了让其他线程获得运行机会
- 抢占式调度:每一个可运行线程一个时间片来执行任务。当时间片用完,操作系统剥夺该线程的运行权,并给另一个线程运行机会,当选择下一个线程时,操作系统考虑线程的优先级
- 协作式调度:一个线程只有在调用yield方法、或者被阻塞或等待时,线程才失去控制权
14.3.3 被阻塞线程或等待线程
- 当线程处于被阻塞或等待状态时,它暂时不活动,它不运行任何代码且消耗最少的资源。直到线程调度器重新激活它
- 当一个线程试图获取一个内部的对象锁(而不是java.util.concurrent库中的锁),而该锁被其他线程持有,则该线程进入阻塞状态
- 当所有其他线程释放该锁,并且线程调度器允许本线程持有它的时候,该线程将变成非阻塞状态
- 当线程等待另一个线程通知调度器一个条件时,它自己进入等待状态。在调用Object.wait方法或Thread.join方法,或者是等待java.util.concurrent库中的Lock或Condition时,就会出现这种情况。实际上,被阻塞状态与等待状态是有很大不同的
- 有几个方法有一个超时参数。调用它们导致线程进入计时等待(timed waiting)状态。这一状态将一直保持到超时期满或者接收到适当的通知。带有超时参数的方法有Thread.sleep和Object.wait、Thread.join、Lock.tryLock以及Condition.await的计时版
14.3.4 被终止的线程
线程因如下两个原因之一而被终止:
- 因为run方法正常退出而自然死亡
- 因为一个没有捕获的异常终止了run方法而意外死亡
14.4 线程属性
14.4.1 线程优先级
- 在Java程序设计语言中,每一个线程有一个优先级
- 默认情况下,一个线程继承它的父线程的优先级
- 可以用setPriority方法提高或降低任何一个线程的优先级
- 可以将优先级设置为在MIN_PRIORITY(在Thread类中定义为1)与MAX_PRIORITY(定义为10)之间的任何值。NORM_PRIORITY被定义为5
- 每当线程调度器有机会选择新线程时,它首先选择具有较高优先级的线程
- 不要将程序构建为功能的正确性依赖于优先级
- 如果确实要使用优先级,应该避免初学者常犯的一个错误
- 如果有几个高优先级的线程没有进入非活动状态,低优先级的线程可能永远也不能执行
- 每当调度器决定运行一个新线程时,首先会在具有高优先级的线程中进行选择,尽管这样会使低优先级的线程完全饿死
14.4.2 守护线程
- 守护线程的唯一用途是为其他线程提供服务
- 当只剩下守护线程时,虚拟机就退出了,由于如果只剩下守护线程,就没必要继续运行程序了
- 守护线程有时会被初学者错误地使用,他们不打算考虑关机(shutdown)动作。但是,这是很危险的。守护线程应该永远不去访问固有资源,如文件、数据库,因为它会在任何时候甚至在一个操作的中间发生中断
1 | t.setDaemon(true); |
14.4.3 未捕获异常处理器
- 线程的run方法不能抛出任何受查异常,但是,非受查异常会导致线程终止(线程死亡)
- 但是,不需要任何catch子句来处理可以被传播的异常
- 相反,就在线程死亡之前,异常被传递到一个用于未捕获异常的处理器
1 | //该处理器必须属于一个实现Thread.UncaughtExceptionHandler接口的类 |
-
线程组是一个可以统一管理的线程集合
-
默认情况下,创建的所有线程属于相同的线程组,但是,也可能会建立其他的组
-
现在引入了更好的特性用于线程集合的操作,所以建议不要在自己的程序中使用线程组
-
ThreadGroup类实现Thread.UncaughtExceptionHandler接口
它的uncaughtException方法做如下操作:
- 如果该线程组有父线程组,那么父线程组的uncaughtException方法被调用。
- 否则,如果Thread.getDefaultExceptionHandler方法返回一个非空的处理器,则调用该处理器。
- 否则,如果Throwable是ThreadDeath的一个实例,什么都不做。
- 否则,线程的名字以及Throwable的栈轨迹被输出到System.err上
14.5 同步
14.5.2 竞争条件详解
1 | //假定两个线程同时执行指令 |
14.5.3 锁对象
- 有两种机制防止代码块受并发访问的干扰
- Java语言提供一个synchronized关键字达到这一目的,并且Java SE 5.0引入了ReentrantLock类。synchronized关键字自动提供一个锁以及相关的“条件”
- java.util.concurrent框架为这些基础机制提供独立的类
1 | //用ReentrantLock保护代码块的基本结构如下 |
-
把解锁操作括在finally子句之内是至关重要的
-
如果在临界区的代码抛出异常,锁必须被释放。否则,其他线程将永远阻塞
-
如果使用锁,就不能使用带资源的try语句
-
首先,解锁方法名不是close。不过,即使将它重命名,带资源的try语句也无法正常工作
-
它的首部希望声明一个新变量。但是如果使用一个锁,你可能想使用多个线程共享的那个变量(而不是新变量)
-
注意每一个Bank对象有自己的ReentrantLock对象
- 如果两个线程试图访问同一个Bank对象,那么锁以串行方式提供服务。但是,如果两个线程访问不同的Bank对象,每一个线程得到不同的锁对象,两个线程都不会发生阻塞
- 本该如此,因为线程在操纵不同的Bank实例的时候,线程之间不会相互影响。
-
锁是可重入的,因为线程可以重复地获得已经持有的锁
- 锁保持一个持有计数(hold count)来跟踪对lock方法的嵌套调用
- 线程在每一次调用lock都要调用unlock来释放锁。由于这一特性,被一个锁保护的代码可以调用另一个使用相同的锁的方法
-
通常,可能想要保护需若干个操作来更新或检查共享对象的代码块。要确保这些操作完成后,另一个线程才能使用相同对象
-
要留心临界区中的代码,不要因为异常的抛出而跳出临界区
-
如果在临界区代码结束之前抛出了异常,finally子句将释放锁,但会使对象可能处于一种受损状态
- 听起来公平锁更合理一些,但是使用公平锁比使用常规锁要慢很多
- 只有当你确实了解自己要做什么并且对于你要解决的问题有一个特定的理由必须使用公平锁的时候,才可以使用公平锁
- 即使使用公平锁,也无法确保线程调度器是公平的。如果线程调度器选择忽略一个线程,而该线程为了这个锁已经等待了很长时间,那么就没有机会公平地处理这个锁了
14.5.4 条件对象
- 线程进入临界区,却发现在某一条件满足之后它才能执行
- 要使用一个条件对象来管理那些已经获得了一个锁但是却不能做有用工作的线程
1 | //细化银行的模拟程序 |
-
至关重要的是最终需要某个其他线程调用signalAll方法
- 当一个线程调用await时,它没有办法重新激活自身。它寄希望于其他线程
- 如果没有其他线程来重新激活等待的线程,它就永远不再运行了。这将导致令人不快的死锁(deadlock)现象
- 如果所有其他线程被阻塞,最后一个活动线程在解除其他线程的阻塞状态之前就调用await方法,那么它也被阻塞。没有任何线程可以解除其他线程的阻塞,那么该程序就挂起了。
-
应该何时调用signalAll呢
- 经验上讲,在对象的状态有利于等待线程的方向改变时调用signalAll
-
注意调用signalAll不会立即激活一个等待线程。它仅仅解除等待线程的阻塞,以便这些线程可以在当前线程退出同步方法之后,通过竞争实现对对象的访问
-
另一个方法signal,则是随机解除等待集中某个线程的阻塞状态
-
这比解除所有线程的阻塞更加有效,但也存在危险。如果随机选择的线程发现自己仍然不能运行,那么它再次被阻塞。如果没有其他线程再次调用signal,那么系统就死锁了
-
当一个线程拥有某个条件的锁时,它仅仅可以在该条件上调用await、signalAll或signal方法
14.5.5 synchronized关键字
锁和条件的关键之处:
- 锁用来保护代码片段,任何时刻只能有一个线程执行被保护的代码
- 锁可以管理试图进入被保护代码段的线程
- 锁可以拥有一个或多个相关的条件对象
- 每个条件对象管理那些已经进入被保护的代码段但还不能运行的线程
- Java中的每一个对象都有一个内部锁
- 如果一个方法用synchronized关键字声明,那么对象的锁将保护整个方法(要调用该方法,线程必须获得内部的对象锁)
- 由锁来管理那些试图进入synchronized方法的线程,由条件来管理那些调用wait的线程
- 内部对象锁只有一个相关条件。wait方法添加一个线程到等待集中,notifyAll/notify方法解除等待线程的阻塞状态
- wait、notifyAll以及notify方法是Object类的final方法。Condition方法必须被命名为await、signalAll和signal以便它们不会与那些方法发生冲突
1 | public synchronized void method() { |
内部锁和条件存在一些局限。包括:
- 不能中断一个正在试图获得锁的线程
- 试图获得锁时不能设定超时
- 每个锁仅有单一的条件,可能是不够的
Lock和Condition对象还是同步方法
- 最好既不使用Lock/Condition也不使用synchronized关键字。在许多情况下你可以使用java.util.concurrent包中的一种机制,它会为你处理所有的加锁。例如,使用阻塞队列来同步完成一个共同任务的线程
- 如果synchronized关键字适合你的程序,那么请尽量使用它,这样可以减少编写的代码数量,减少出错的几率
- 如果特别需要Lock/Condition结构提供的独有特性时,才使用Lock/Condition
14.5.6 同步阻塞
- 线程可以通过调用同步方法获得锁
- 还可以通过进入一个同步阻塞
1 | //当线程进入如下形式的阻塞 |
14.5.7 监视器概念
- 监视器可以在不需要程序员考虑如何加锁的情况下,就可以保证多线程的安全性
- 监视器的特征:
- 监视器是只包含私有域的类
- 每个监视器类的对象有一个相关的锁
- 使用该锁对所有的方法进行加锁
- 因为所有的域是私有的,这样的安排可以确保一个线程在对对象操作时,没有其他线程能访问该域
- 该锁可以有任意多个相关条件
- 可以简单地调用await accounts[from]>=balance而不使用任何显式的条件变量。然而,研究表明盲目地重新测试条件是低效的。显式的条件变量解决了这一问题。每一个条件变量管理一个独立的线程集
- Java中的每一个对象有一个内部的锁和内部的条件
- 如果一个方法用synchronized关键字声明,那么,它表现的就像是一个监视器方法。通过调用wait/notifyAll/notify来访问条件变量
- 在3个方面Java对象不同于监视器,从而使得线程的安全性下降:
- 域不要求必须是private
- 方法不要求必须是synchronized
- 内部锁对客户是可用的
14.5.8 Volatile域
- 多处理器的计算机能够暂时在寄存器或本地内存缓冲区中保存内存中的值。结果是,运行在不同处理器上的线程可能在同一个内存位置取到不同的值
- 编译器可以改变指令执行的顺序以使吞吐量最大化。这种顺序上的变化不会改变代码语义,但是编译器假定内存的值仅仅在代码中有显式的修改指令时才会改变。然而,内存的值可以被另一个线程改变!
- 如果你使用锁来保护可以被多个线程访问的代码,那么可以不考虑这种问题。编译器被要求通过在必要的时候刷新本地缓存来保持锁的效应,并且不能不正当地重新排序指令
- volatile关键字为实例域的同步访问提供了一种免锁机制
- 如果声明一个域为volatile,那么编译器和虚拟机就知道该域是可能被另一个线程并发更新的
- Volatile变量不能提供原子性
- 不能确保翻转域中的值。不能保证读取、翻转和写入不被中断
14.5.9 final变量
- 除非使用锁或volatile修饰符,否则无法从多个线程安全地读取一个域
- 还可以安全地访问一个共享域,即这个域声明为final
14.5.10 原子性
- 假设对共享变量除了赋值之外并不完成其他操作,那么可以将这些共享变量声明为volatile
- 在Java SE 8中,可以使用一个lambda表达式更新变量
- 如果有大量线程要访问相同的原子值,性能会大幅下降,因为乐观更新需要太多次重试
- Java SE 8提供了LongAdder和LongAccumulator类来解决这个问题。LongAdder包括多个变量(加数),其总和为当前值。可以有多个线程更新不同的加数,线程个数增加时会自动提供新的加数。通常情况下,只有当所有工作都完成之后才需要总和的值,对于这种情况,这种方法会很高效。性能会有显著的提升。
- 如果认为可能存在大量竞争,只需要使用LongAdder而不是AtomicLong。方法名稍有区别。调用increment让计数器自增,或者调用add来增加一个量,或者调用sum来获取总和
14.5.11 死锁
- 有可能会因为每一个线程要等待更多的钱款存入而导致所有线程都被阻塞。这样的状态称为死锁
- 当程序挂起时,键入CTRL+\,将得到一个所有线程的列表。每一个线程有一个栈踪迹,告诉你线程被阻塞的位置
- 导致死锁的另一种途径是让第i个线程负责向第i个账户存钱,而不是从第i个账户取钱。这样一来,有可能将所有的线程都集中到一个账户上,每一个线程都试图从这个账户中取出大于该账户余额的钱
- 还有一种很容易导致死锁的情况:在SynchBankTest程序中,将signalAll方法转换为signal,会发现该程序最终会挂起(将NACCOUNTS设为10可以更快地看到结果)。signalAll通知所有等待增加资金的线程,与此不同的是signal方法仅仅对一个线程解锁。如果该线程不能继续运行,所有的线程可能都被阻塞
14.5.12 线程局部变量
- 有时可能要避免共享变量,使用ThreadLocal辅助类为各个线程提供各自的实例
- 在多个线程中生成随机数,java.util.Random类是线程安全的。但是如果多个线程需要等待一个共享的随机数生成器,这会很低效
- 可以使用ThreadLocal辅助类为各个线程提供一个单独的生成器
- Java SE 7还另外提供了一个便利类,ThreadLocalRandom.current()调用会返回特定于当前线程的Random类实例
14.5.13 锁测试域超时
- 线程在调用lock方法来获得另一个线程所持有的锁的时候,很可能发生阻塞
- tryLock方法试图申请一个锁,在成功获得锁后返回true,否则,立即返回false,而且线程可以立即离开去做其他事情
1 | if (myLock.tryLock()) |
14.5.14 读/写锁
- 如果很多线程从一个数据结构读取数据而很少线程修改其中数据的话,后者是十分有用的
- 在这种情况下,允许对读者线程共享访问是合适的。当然,写者线程依然必须是互斥访问的
1 | //使用读/写锁的必要步骤 |
14.5.15 为什么弃用stop和suspend方法
- 首先来看看stop方法,该方法终止所有未结束的方法,包括run方法。当线程被终止,立即释放被它锁住的所有对象的锁。这会导致对象处于不一致的状态
- 例如,假定TransferThread在从一个账户向另一个账户转账的过程中被终止,钱款已经转出,却没有转入目标账户,现在银行对象就被破坏了。因为锁已经被释放,这种破坏会被其他尚未停止的线程观察到
- 当线程要终止另一个线程时,无法知道什么时候调用stop方法是安全的,什么时候导致对象被破坏。因此,该方法被弃用了。在希望停止线程的时候应该中断线程,被中断的线程会在安全的时候停止
- 因为它会导致对象被一个已停止的线程永久锁定。但是,这一说法是错误的。从技术上讲,被停止的线程通过抛出ThreadDeath异常退出所有它所调用的同步方法。结果是,该线程释放它持有的内部对象锁
- stop不同,suspend不会破坏对象。但是,如果用suspend挂起一个持有一个锁的线程,那么,该锁在恢复之前是不可用的。如果调用suspend方法的线程试图获得同一个锁,那么程序死锁:被挂起的线程等着被恢复,而将其挂起的线程等待获得锁
14.6 阻塞队列
- 对于许多线程问题,可以通过使用一个或多个队列以优雅且安全的方式将其形式化。生产者线程向队列插入元素,消费者线程则取出它们。使用队列,可以安全地从一个线程向另一个线程传递数据
- 当试图向队列添加元素而队列已满,或是想从队列移出元素而队列为空的时候,阻塞队列(blocking queue)导致线程阻塞
- 在协调多个线程之间的合作时,阻塞队列是一个有用的工具。工作者线程可以周期性地将中间结果存储在阻塞队列中。其他的工作者线程移出中间结果并进一步加以修改。队列会自动地平衡负载
- 如果第一个线程集运行得比第二个慢,第二个线程集在等待结果时会阻塞。如果第一个线程集运行得快,它将等待第二个队列集赶上来
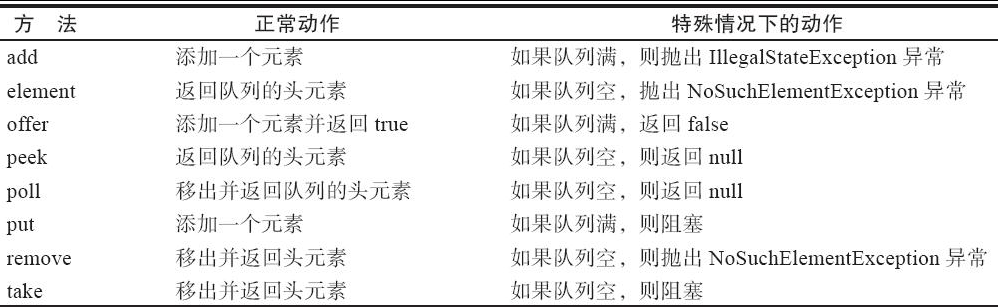
- 如果将队列当作线程管理工具来使用,将要用到put和take方法。当试图向满的队列中添加或从空的队列中移出元素时,add、remove和element操作抛出异常。当然,在一个多线程程序中,队列会在任何时候空或满,因此,一定要使用offer、poll和peek方法作为替代
- poll和peek方法返回空来指示失败。因此,向这些队列中插入null值是非法的
- 还有带有超时的offer方法和poll方法的变体
- java.util.concurrent包提供了阻塞队列的几个变种。默认情况下,LinkedBlockingQueue的容量是没有上边界的,但是,也可以选择指定最大容量。LinkedBlockingDeque是一个双端的版本
- ArrayBlockingQueue在构造时需要指定容量,并且有一个可选的参数来指定是否需要公平性。若设置了公平参数,则那么等待了最长时间的线程会优先得到处理。通常,公平性会降低性能,只有在确实非常需要时才使用它
- PriorityBlockingQueue是一个带优先级的队列,而不是先进先出队列。元素按照它们的优先级顺序被移出。该队列是没有容量上限,但是,如果队列是空的,取元素的操作会阻塞
- DelayQueue包含实现Delayed接口的对象
- getDelay方法返回对象的残留延迟。负值表示延迟已经结束。元素只有在延迟用完的情况下才能从DelayQueue移除。还必须实现compareTo方法。DelayQueue使用该方法对元素进行排序
- Java SE 7增加了一个TransferQueue接口,允许生产者线程等待,直到消费者准备就绪可以接收一个元素
14.7 线程安全的集合
- 如果多线程要并发地修改一个数据结构,例如散列表,那么很容易会破坏这个数据结构
- 可以通过提供锁来保护共享数据结构,但是选择线程安全的实现作为替代可能更容易些
14.7.1 高效的映射、集和队列
- java.util.concurrent包提供了映射、有序集和队列的高效实现:ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet和ConcurrentLinkedQueue
- 这些集合使用复杂的算法,通过允许并发地访问数据结构的不同部分来使竞争极小化
- 与大多数集合不同,size方法不必在常量时间内操作。确定这样的集合当前的大小通常需要遍历
- 有些应用使用庞大的并发散列映射,这些映射太过庞大,以至于无法用size方法得到它的大小,因为这个方法只能返回int。对于一个包含超过20亿条目的映射该如何处理?Java SE 8引入了一个mappingCount方法可以把大小作为long返回
- 集合返回弱一致性(weakly consistent)的迭代器。这意味着迭代器不一定能反映出它们被构造之后的所有的修改,但是,它们不会将同一个值返回两次,也不会抛出Concurrent ModificationException异常
- 与之形成对照的是,集合如果在迭代器构造之后发生改变,java.util包中的迭代器将抛出一个ConcurrentModificationException异常
- 并发的散列映射表,可高效地支持大量的读者和一定数量的写者
- 散列映射将有相同散列码的所有条目放在同一个“桶”中。有些应用使用的散列函数不当,以至于所有条目最后都放在很少的桶中,这会严重降低性能。即使是一般意义上还算合理的散列函数,如String类的散列函数,也可能存在问题
- 在Java SE 8中,并发散列映射将桶组织为树,而不是列表,键类型实现了Comparable,从而可以保证性能为O(log(n))
14.7.2 映射条目的原子更新
- ConcurrentHashMap原来的版本只有为数不多的方法可以实现原子更新
- 可以使用ConcurrentHashMap<String,Long>吗?考虑让计数自增的代码
- 为什么原本线程安全的数据结构会允许非线程安全的操作。不过有两种完全不同的情况。如果多个线程修改一个普通的HashMap,它们会破坏内部结构(一个链表数组)。有些链接可能丢失,或者甚至会构成循环,使得这个数据结构不再可用。对于ConcurrentHashMap绝对不会发生这种情况。在上面的例子中,get和put代码不会破坏数据结构。不过,由于操作序列不是原子的,所以结果不可预知
- 传统的做法是使用replace操作,它会以原子方式用一个新值替换原值,前提是之前没有其他线程把原值替换为其他值。必须一直这么做,直到replace成功
- 或者,可以使用一个ConcurrentHashMap<String,AtomicLong>,或者在Java SE 8中,还可以使用ConcurrentHashMap<String,LongAdder>
- Java SE 8提供了一些可以更方便地完成原子更新的方法。调用compute方法时可以提供一个键和一个计算新值的函数。这个函数接收键和相关联的值(如果没有值,则为null),它会计算新值
- ConcurrentHashMap中不允许有null值。有很多方法都使用null值来指示映射中某个给定的键不存在
- 另外还有computeIfPresent和computeIfAbsent方法,它们分别只在已经有原值的情况下计算新值,或者只有没有原值的情况下计算新值
- 首次增加一个键时通常需要做些特殊的处理。利用merge方法可以非常方便地做到这一点。这个方法有一个参数表示键不存在时使用的初始值。否则,就会调用你提供的函数来结合原值与初始值。(与compute不同,这个函数不处理键
- 如果传入compute或merge的函数返回null,将从映射中删除现有的条目
- 警告:使用compute或merge时,要记住你提供的函数不能做太多工作。这个函数运行时,可能会阻塞对映射的其他更新。当然,这个函数也不能更新映射的其他部分
14.7.3 对并发散列映射的批操作
- Java SE 8为并发散列映射提供了批操作,即使有其他线程在处理映射,这些操作也能安全地执行
- 3中不同的操作
- 搜索为每个键或值提供一个函数,直到函数生成一个非null的结果。然后搜索终止,返回这个函数的结果
- 归约组合所有键或值,这里要使用所提供的一个累加函数
- forEach为所有键或值提供一个函数
- 每个操作都有4个版本
- operationKeys:处理键
- operationValues:处理值
- operation:处理键和值
- operationEntries:处理Map.Entry对象
- 需要指定一个参数化阈值(parallelism threshold)。如果映射包含的元素多于这个阈值,就会并行完成批操作。如果希望批操作在一个线程中运行,可以使用阈值Long.MAX_VALUE。如果希望用尽可能多的线程运行批操作,可以使用阈值1
14.7.4 并发集视图
- 假设你想要的是一个大的线程安全的集而不是映射。并没有一个ConcurrentHashSet类,而且你肯定不想自己创建这样一个类。当然,可以使用ConcurrentHashMap(包含“假”值),不过这会得到一个映射而不是集,而且不能应用Set接口的操作
- 静态newKeySet方法会生成一个Set<K>,这实际上是ConcurrentHashMap<K,Boolean>的一个包装器。(所有映射值都为Boolean.TRUE,不过因为只是要把它用作一个集,所以并不关心具体的值
- 如果原来有一个映射,keySet方法可以生成这个映射的键集。这个集是可变的。如果删除这个集的元素,这个键(以及相应的值)会从映射中删除。不过,不能向键集增加元素,因为没有相应的值可以增加。Java SE 8为ConcurrentHashMap增加了第二个keySet方法,包含一个默认值
14.7.5 写数组的拷贝
- CopyOnWriteArrayList和CopyOnWriteArraySet是线程安全的集合,其中所有的修改线程对底层数组进行复制
- 如果在集合上进行迭代的线程数超过修改线程数,这样的安排是很有用的。当构建一个迭代器的时候,它包含一个对当前数组的引用。如果数组后来被修改了,迭代器仍然引用旧数组,但是,集合的数组已经被替换了。因而,旧的迭代器拥有一致的(可能过时的)视图,访问它无须任何同步开销
14.7.6 并行数组算法
- 在Java SE 8中,Arrays类提供了大量并行化操作。静态Arrays.parallelSort方法可以对一个基本类型值或对象的数组排序
- 对对象排序时,可以提供一个Comparator
- 对于所有方法都可以提供一个范围的边界
- parallelSetAll方法会用由一个函数计算得到的值填充一个数组。这个函数接收元素索引,然后计算相应位置上的值
- parallelPrefix方法,它会用对应一个给定结合操作的前缀的累加结果替换各个数组元素
14.7.7 较早的线程安全集合
- 从Java的初始版本开始,Vector和Hashtable类就提供了线程安全的动态数组和散列表的实现。现在这些类被弃用了,取而代之的是ArrayList和HashMap类。这些类不是线程安全的,而集合库中提供了不同的机制。任何集合类都可以通过使用同步包装器(synchronization wrapper)变成线程安全的
- 确保没有任何线程通过原始的非同步方法访问数据结构。最便利的方法是确保不保存任何指向原始对象的引用,简单地构造一个集合并立即传递给包装器
- 在另一个线程可能进行修改时要对集合进行迭代,仍然需要使用“客户端”锁定
- 如果使用“for each”循环必须使用同样的代码,因为循环使用了迭代器。注意:如果在迭代过程中,别的线程修改集合,迭代器会失效,抛出ConcurrentModificationException异常。同步仍然是需要的,因此并发的修改可以被可靠地检测出来
- 最好使用java.util.concurrent包中定义的集合,不使用同步包装器中的。特别是,假如它们访问的是不同的桶,由于ConcurrentHashMap已经精心地实现了,多线程可以访问它而且不会彼此阻塞。有一个例外是经常被修改的数组列表。在那种情况下,同步的ArrayList可以胜过CopyOnWriteArrayList
14.8 Callable与Future
- Runnable封装一个异步运行的任务,可以把它想象成为一个没有参数和返回值的异步方法。Callable与Runnable类似,但是有返回值
- Callable接口是一个参数化的类型,只有一个方法call
- Future保存异步计算的结果。可以启动一个计算,将Future对象交给某个线程,然后忘掉它。Future对象的所有者在结果计算好之后就可以获得它
14.9 执行器
- 如果程序中创建了大量的生命期很短的线程,应该使用线程池(thread pool)。一个线程池中包含许多准备运行的空闲线程。将Runnable对象交给线程池,就会有一个线程调用run方法。当run方法退出时,线程不会死亡,而是在池中准备为下一个请求提供服务
- 另一个使用线程池的理由是减少并发线程的数目。创建大量线程会大大降低性能甚至使虚拟机崩溃。如果有一个会创建许多线程的算法,应该使用一个线程数“固定的”线程池以限制并发线程的总数
- 执行器(Executor)类有许多静态工厂方法用来构建线程池

14.9.1 线程池
- newCached-ThreadPool方法构建了一个线程池,对于每个任务,如果有空闲线程可用,立即让它执行任务,如果没有可用的空闲线程,则创建一个新线程
- newFixedThreadPool方法构建一个具有固定大小的线程池。如果提交的任务数多于空闲的线程数,那么把得不到服务的任务放置到队列中。当其他任务完成以后再运行它们
- newSingleThreadExecutor是一个退化了的大小为1的线程池:由一个线程执行提交的任务,一个接着一个
- 这3个方法返回实现了ExecutorService接口的ThreadPoolExecutor类的对象
- 在使用连接池时应该做的事
- 调用Executors类中静态的方法newCachedThreadPool或newFixedThreadPool。
- 调用submit提交Runnable或Callable对象。
- 如果想要取消一个任务,或如果提交Callable对象,那就要保存好返回的Future对象。
- 当不再提交任何任务时,调用shutdown
14.9.2 预定执行
- ScheduledExecutorService接口具有为预定执行(Scheduled Execution)或重复执行任务而设计的方法。它是一种允许使用线程池机制的java.util.Timer的泛化
- Executors类的newScheduledThreadPool和newSingleThreadScheduledExecutor方法将返回实现了Scheduled-ExecutorService接口的对象
- 可以预定Runnable或Callable在初始的延迟之后只运行一次。也可以预定一个Runnable对象周期性地运行
14.9.3 控制任务组
- 将一个执行器服务作为线程池使用,以提高执行任务的效率
- 有时,使用执行器有更有实际意义的原因,控制一组相关任务
- invokeAny方法提交所有对象到一个Callable对象的集合中,并返回某个已经完成了的任务的结果。无法知道返回的究竟是哪个任务的结果,也许是最先完成的那个任务的结果。对于搜索问题,如果你愿意接受任何一种解决方案的话,你就可以使用这个方法
- invokeAll方法提交所有对象到一个Callable对象的集合中,并返回一个Future对象的列表,代表所有任务的解决方案
- 缺点是如果第一个任务恰巧花去了很多时间,则可能不得不进行等待。将结果按可获得的顺序保存起来更有实际意义。可以用ExecutorCompletionService来进行排列
- 用常规的方法获得一个执行器。然后,构建一个ExecutorCompletionService,提交任务给完成服务(completion service)。该服务管理Future对象的阻塞队列,其中包含已经提交的任务的执行结果(当这些结果成为可用时)
14.9.4 Fork-Join框架
- Java SE 7中新引入了fork-join框架,专门用来支持后一类应用。假设有一个处理任务,它可以很自然地分解为子任务
- 要采用框架可用的一种方式完成这种递归计算,需要提供一个扩展RecursiveTask<T>的类(如果计算会生成一个类型为T的结果)或者提供一个扩展RecursiveAction的类(如果不生成任何结果)。再覆盖compute方法来生成并调用子任务,然后合并其结果
- 在后台,fork-join框架使用了一种有效的智能方法来平衡可用线程的工作负载,这种方法称为工作密取(work stealing)。每个工作线程都有一个双端队列(deque)来完成任务。一个工作线程将子任务压入其双端队列的队头。(只有一个线程可以访问队头,所以不需要加锁。)一个工作线程空闲时,它会从另一个双端队列的队尾“密取”一个任务。由于大的子任务都在队尾,这种密取很少出现
14.9.5 可完成Future
- 处理非阻塞调用的传统方法是使用事件处理器,程序员为任务完成之后要出现的动作注册一个处理器
- Java SE 8的CompletableFuture类提供了一种候选方法。与事件处理器不同,“可完成future”可以“组合”(composed)
- 利用可完成future,可以指定你希望做什么,以及希望以什么顺序执行这些工作。当然,这不会立即发生,不过重要的是所有代码都放在一处
- 从概念上讲,CompletableFuture是一个简单API,不过有很多不同方法来组合可完成future。下面先来看处理单个future的方法(如表14-3所示)。(对于这里所示的每个方法,还有两个Async形式,不过这里没有给出,其中一种形式使用一个共享ForkJoinPool,另一种形式有一个Executor参数)。在这个表中,我使用了简写记法来表示复杂的函数式接口,这里会把Function<?super T,U>写为T->U。当然这并不是真正的Java类型
14.10 同步器
- 线程之间的共用集结点模式:如果有一个相互合作的线程集满足这些行为模式之一,那么应该直接重用合适的库类而不要试图提供手工的锁与条件的集合
14.10.1 信号量
一个信号量管理许多的许可证(permit)。为了通过信号量,线程通过调用acquire请求许可。其实没有实际的许可对象,信号量仅维护一个计数。许可的数目是固定的,由此限制了通过的线程数量。其他线程可以通过调用release释放许可。而且,许可不是必须由获取它的线程释放。事实上,任何线程都可以释放任意数目的许可,这可能会增加许可数目以至于超出初始数目
14.10.2 倒计时门栓
- 一个倒计时门栓(CountDownLatch)让一个线程集等待直到计数变为0。倒计时门栓是一次性的。一旦计数为0,就不能再重用了
- 一个有用的特例是计数值为1的门栓。实现一个只能通过一次的门。线程在门外等候直到另一个线程将计数器值置为0
14.10.3 障栅
- CyclicBarrier类实现了一个集结点(rendezvous)称为障栅(barrier)。考虑大量线程运行在一次计算的不同部分的情形。当所有部分都准备好时,需要把结果组合在一起。当一个线程完成了它的那部分任务后,我们让它运行到障栅处。一旦所有的线程都到达了这个障栅,障栅就撤销,线程就可以继续运行
- 障栅被称为是循环的(cyclic),因为可以在所有等待线程被释放后被重用。在这一点上,有别于CountDownLatch,CountDownLatch只能被使用一次
- Phaser类增加了更大的灵活性,允许改变不同阶段中参与线程的个数
14.10.4 交换器
当两个线程在同一个数据缓冲区的两个实例上工作的时候,就可以使用交换器(Exchanger)。典型的情况是,一个线程向缓冲区填入数据,另一个线程消耗这些数据。当它们都完成以后,相互交换缓冲区
14.10.5 同步队列
- 同步队列是一种将生产者与消费者线程配对的机制。当一个线程调用SynchronousQueue的put方法时,它会阻塞直到另一个线程调用take方法为止,反之亦然。与Exchanger的情况不同,数据仅仅沿一个方向传递,从生产者到消费者
- 即使SynchronousQueue类实现了BlockingQueue接口,概念上讲,它依然不是一个队列。它没有包含任何元素,它的size方法总是返回0
卷二部分
2 输入与输出
2.1 输入/输出
- 在JavaAPI中,可以从其中读入一个字节序列的对象称为输入流
- 可以向其中写入一个字节序列的对象称为输出流
- 抽象类InputStream和OutputStream构成了输入输出类层次结构的基础
- 这些类的读入和写出操作以基于二字节的char值(Unicode码元)为基础
2.1.1 读写字节
- InputStream类
- 抽象方法: abstract int read()
- 读入一个字节,并返回读入的字节或者在遇到输入源结尾时返回-1
- 抽象方法: abstract int read()
- OutputStream类
- 抽象方法:abstract void write(int b)
- 从某个位置输出一个字节
- 抽象方法:abstract void write(int b)
- read和write在执行时江北阻塞,直至字节确实被读入或写出
- available()方法——检查当前可读入的字节数量
- close()方法——完成对输入/输出流的读写时,关闭流释放操作系统资源
2.1.2 完整的流家族
- InputStream和OutputStream流构成层次结构的基础
- 读写单个字节或字节数组
- 子类包含很多有用的输入和输出流
- 抽象类Reader和Writer子类,处理Unicode文本,基本方法为read()与write()方法
- 四个附加接口: Closeable Flushable Readable 和 Appendable
- Closeable Flushable分别拥有close() flush()方法
- Appendable接口有两个用于添加单个字符和字符序列的方法 append(char c) append(CharSequence s)
- InputStream OutputStream Reader Writer 都实现了Closeable接口
- OutputStream和Writer实现了Flushable接口
2.1.3 组合输入/输出流过滤器
- FileInputStream和FileOutputStream可以提供附着在一个磁盘文件上的输入流和输出流,只需向构造器提供文件名或文件的完整路径名
- 只支持在字节级别上的读写
- 某些输入流(FileInputStream)可以从文件和其他外部位置获取字节;而其他的输入流(DataInputStream)可以将字节组装到更有用的数据类型中,对两者进行组合操作
- 输入流在默认情况下是不被缓冲区缓存的
- 每个对read的调用都会请求操作系统再分发一个字节,请求一个数据块,并将其置于缓冲区中会更加高效
- 当多个输入流链接在一起,跟踪个各个中介输入流:使用PushbackInputStream
- 能预先浏览并且还可以读入数字,需要一个既是可回推输入流,又是一个数据输入流的引用
1 | //为了从文件中读入数字 |
2.2 文本输入与输出
- Java内部使用UTF-16编码,字符串编码为16进制,许多应用程序使用UTF-8编码
- OutputStreamWriter类将使用特定的字符编码方式,把Unicode码元的输出流转换为字节流=
- InputStreamReader类将包含字节的输入流转换为可以产生Unicode码元的读入器
1 | // 构建一个输入读入器从控制台读入键盘敲击信息,并转换为Unicode |
2.2.1 如何写出文本输出
- 对于文本输出,使用PrintWriter(存在可以链接到FileWriter的便捷写法)
- 为了输出到打印写出器,需要使用print,println,printf方法
- println方法在行中添加了对目标系统来说恰当的行结束符
- 写出器设置为自动冲刷模式,那么只要println被调用,缓冲区中的所有字符都会被发送到它们的目的地
- 默认情况下,自动冲刷机制是禁用的,你可以通过使用PrintWriter(Writer out,Boolean autoFlush)来启用或禁用自动冲刷机制
1 | // PrintWriter |
2.2.2 如何读入文本输入
- 使用Scanner对象
- 若文件太大,可以处理为Stream<String>对象
1 | String content = new String(Files.readAllBytes(path),charset); |
2.2.4 字符编码方法
- Java针对字符使用的是Unicode标准,每个字符或编码点有21位整数
- 最常见的编码方式是UTF-8标准,将每个Unicode编码点编码为1到4个字节的序列
- UTF-8的好处是传统的包含了英语中用到的所有字符的ASCII字符集中的每个字符都只会占用一个字节
- UTF-16,它会将每个Unicode编码点编码为1个或2个16位值
- 最常见的编码方式是UTF-8标准,将每个Unicode编码点编码为1到4个字节的序列
- StandardCharsets类具有类型为Charset的静态变量,用于表示每种Java虚拟机都必须支持的字符编码方式
1 | StandardCharsets.UTF_8 |
2.3 读写二进制数据
2.3.1 DataInput和DataOutput接口
- DataOutput接口定义了以二进制格式写数组、字符、boolean值和字符串的方法
1 | writeChars |
- DataInput接口定义的方法,读回数据
- DataInputStream类实现了DataInput接口
- 为了方便从文件中读入二进制数据,可以将DataInputStream与某个字节源相组合
1 | readInt |
2.3.2 随机访问文件
- RandomAccessFile类可以在文件中的任何位置查找或写入数据
- 磁盘文件都是随机访问的,但是与网络套接字通信的输入/输出流却不是,可以打开一个随机访问文件,只用于读入或者同时用于读写
- seek方法——将这个文件指针设置到文件中的任意字节位置——参数位一个long整数
- getFilePointer方法——返回文件指针的位置
- length方法——获得文件中的总字节数
- writeFixedString方法——写出从字符串开头开始的指定数量的码元
- readFixedString方法——从输入流中读入字符,直至读入size个码元,或者直至遇到具有0值得字符串
- 为了提高效率,使用StringBuilder类来读入字符串
1 | RandomAccessFile in = new RandomAccessFile("employee.dat","r"); |
2.3.3 ZIP文档
- ZIP文档都存在一个头,包含压缩文件的信息
- 使用ZipInputStream来读入ZIP文档
- getNextEntry方法——返回一个描述这些ZipEntry类型得对象
- getInputStream方法——传递ZipEntry获得该项的输入流
- closeEntry方法——读入下一项
- 使用ZipOutputStream写出到ZIP文件
- 对于希望放入到ZIP文件中的每一项,都应该创建一个ZipEntry对象,并将文件名传递给ZipEntry的构造器,它将设置其他诸如文件日期和解压缩方法等参数
- putNextEntry方法——开始写出新文件,并将文件数据发送到ZIP输出流中
- closeEntry方法——完成操作调用
1 | ZipInputStream zin = new ZipInputStream(new FileInputStream(zipname)); |
2.4 对象输入/输出流与序列化
- 对象序列化可以实现将任何对象写出到输出流中,并在之后将其读回
2.4.1 保存和加载序列化对象
- 为了保存对象数据,首先需要打开一个ObjectOutputStream对象
- 为了保存对象,可以直接使用ObjecyOutputStream的writeObject方法
- 为了将对象读回,首先需要获得一个ObjectInputStream对象
- 用readObject方法将这些对象被写出时的顺序获得他们
- 在对象输出流中存储或从对象输入流中回复的所有类必须实现Serialzable接口
- 每个对象都时用一个序列号保存(对象序列化的原因)
- 对遇到的每一个对象引用都关联一个序列号
- 对于每个对象,当第一次遇到时,保存其对象数据到输出流中
- 如果某个对象之前已经被保存过,那么只写出”与之前保存过的序列号x的对象相同“
- 对于对象输入流中的对象,在第一次遇到其序列号时,构建它,并使用流中数据来初始化它,然后记录这个顺序号和新对象之间的关联
- 当遇到“与之前保存过的序列号为x的对象相同”标记时,获取与这个顺序号相关联的对象引用
1 | Employee harry = new Employee("Harry", 50000, 1989, 10, 1); |
2.4.2 理解对象序列化的文件格式
- 对象流输出中包含所有对象的类型和数据域
- 每个对象都被赋予一个序列号
- 相同对象的重复出现将被存储为对这个对象的序列号的引用
2.5 操作文件
- Path接口和Files类
- Path和Files类封装了在用户机器上处理文件系统所需的所有功能
2.5.1 Path
- Path表示是一个目录名序列,其后还可以跟着一个文件名
- Paths.get方法——接受一个或多个字符串,并将它们用默认文件系统的路径分隔符连接起来,这个连接起来的结果就是一个Path对象
- p.resolve(q)——按照规则返回一个路径,如果q是绝对路径,则结果就是q;否则,根据文件系统的规则,将“p后面跟着q”作为结果
- resolveSibling()——通过解析指定路径的父路径产生器兄弟路径
- p.relativize®——调用将产生路径q,而对q进行解析的结果正是r
- normalize()——将移除所有冗余的.和…部件(或者文件系统认为冗余的所有部件)
- toAbsolutePath()——将产生给定路径的绝对路径,该绝对路径从根部件开始
2.5.2 读写文件
- Files类使操作普通文件更快捷
1 | // 读取文件的所有内容 |
2.5.3 创建文件和目录
1 | // 创建新目录 |
2.5.4 复制,移动和删除文件
1 | // 复制文件 |
2.5.5 获取文件信息
- 所有的文件系统都会报告一个基本属性集,它们被封装在BasicFileAttributes接口中,这些属性与上述信息有部分重叠。基本文件属性包括:
- 创建文件、最后一次访问以及最后一次修改文件的时间,这些时间都表示成java.nio.file.attribute.FileTime
- 文件是常规文件、目录还是符号链接,抑或这三者都不是
- 文件尺寸
- 文件主键,这是某种类的对象,具体所属类与文件系统相关,有可能是文件的唯一标识符,也可能不是
1 | // 静态方法将返回一个boolean值,表示检查路径的某个属性的结果 |
2.5.6 访问目录中的项
- 静态的Files.list方法会返回一个可以读取目录中各个项的Stream<Path>对象
- 目录是被惰性读取的,这使得处理具有大量项的目录可以变得更高效
- 读取目录涉及需要关闭的系统资源,所以应该使用try块
- 为了处理目录中的所有子目录,需要使用File.walk方法
- 可以通过调用File.walk(pathToRoot, depth)来限制想要访问的树的深度
- 两种walk方法都具有FileVisitOption…的可变长参数,但是你只能提供一种选项:FOLLOW_LINKS,即跟踪符号链接
- 如果要过滤walk返回的路径,并且你的过滤标准涉及与目录存储相关的文件属性,那么应该使用find方法来替代walk方法
- 可以用某个谓词函数来调用这个方法,该函数接受一个路径和一个BasicFileAttributes对象(效率高:因为路径总是会被读入,所以这些属性很容易获取)
- 无法很容易地使用Files.walk方法来删除目录树,因为你需要在删除父目录之前必须先删除子目录
2.5.7 使用目录流
- 对遍历过程进行更加细粒度的控制,应该使用File.newDirectoryStream对象,它会产生一个DirectoryStream
- 注意,它不是java.util.stream.Stream的子接口,而是专门用于目录遍历的接口
- 是Iterable的子接口,因此你可以在增强的for循环中使用目录流
- 如果想要访问某个目录的所有子孙成员,可以转而调用walkFileTree方法,并向其传递一个FileVisitor类型的对象
- 便捷类SimpleFileVisitor实现了FileVisitor接口,但是其除visitFileFailed方法之外的所有方法并不做任何处理而是直接继续访问,而visitFileFailed方法会抛出由失败导致的异常,并进而终止访问
2.5.8 ZIP文件系统
1 | // 如果zipname是某个ZIP文件的名字,建立一个文件系统,包含ZIP文档中的所有文件 |
Java8实战
Lambda表达式
Lambda表达式的三个部分:参数列表,箭头,Lambda主体
- 在函数式接口中使用Lambda接口
- 函数式接口就是只定义了一个抽象方法的接口,在该接口中可以拥有默认方法(即在类没有对方法进行实现时,其主体为方法提供默认实现的方法)
- Lambda表达式允许直接以内联的形式为函数式接口的抽象方法提供实现,并把整个表达式作为函数式接口的实例
- @ FunctionalInterface 为函数式接口的标注, 抽象方法的签名称为函数描述符
- 常用的函数式接口:
- Predicate<T> boolean test(T t)
- Consumer<T> void accept(T t)
- Function<T,R> R apply(T t)
- Supplier<T>
- 引用类型(Byte,Integer,Object,List),与原始类型(int,double,byte,char)类型,但是泛型只能绑定到引用类型
- Java中具有将原始类型转换为引用类型的机制(装箱),同时存在拆箱的机制
- 装箱后的值本质上就是把原始类型包裹起来,并保存在堆
- 若Lambda的主体是一个语句表达式, 它就和一个返回void的函数描述符兼容(当然需要参数列表也兼容)
使用局部变量
- Lambda表达式允许使用自由变量(不是参数,而是在外层作用域定义的变量),被称为捕获Lambda
- 局部变量必须显式声明为final(Lambda表达式只能捕获派给它们的局部变量一次)
- 第一,实例变量和局部变量背后的实现有一个关键不同。实例变量都存储在堆中,而局部变量则保存在栈上。如果Lambda可以直接访问局部变量,而且Lambda是在一个线程中使用的,则使用Lambda的线程,可能会在分配该变量的线程将这个变量收回之后,去访问该变量。因此,Java在访问自由局部变量时,实际上是在访问它的副本,而不是访问原始变量。如果局部变量仅仅赋值一次那就没有什么区别了——因此就有了这个限制。
- 第二,这一限制不鼓励你使用改变外部变量的典型命令式编程模式(我们会在以后的各章中解释,这种模式会阻碍很容易做到的并行处理)。
- Java8的Lambda和匿名类对值封闭,而不是对变量封闭(原因在局部变量保存在栈上,并且隐式表示他们仅限于其所在线程)
方法引用(Lambda的快捷写法)
- 方法引用的三类
- 指向静态方法的方法引用
- 指向任意类型实例方法的方法引用
- 指向现有对象的实例方法的方法引用
- 构造函数引用
- 可以利用名称和关键字new来创建引用
- 复合Lambda表达式
- 比较器复合: 1.逆序 2.比较器链
- 谓词复合: negate、and和or
- 函数复合: andThen 方法会返回一个函数,它先对输入应用一个给定函数,再对输出应用另一个函数;compose方法把给定的函数用作compose的参数里面给的那个函数,然后再把函数本身用于结果
流简介
- 流允许以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)
- 优势:
- 声明性:说明想要完成什么而不是说明如何实现一个操作
- 可复合
- 可并行
流: 从支持数据处理操作的源生成元素序列
- 元素序列——集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值,流的目的在于表达计算,集合为数据
- 源——流会使用一个提供数据的源,从有序集合生成流,从有序集合生成流时会保留原有的顺序
- 数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,
- filter:接受Lambda,从流中排除某些元素
- map:接受Lambda,将元素转换成其他形式或提取信息
- limit:截断流,使元素不超过其他给定数量
- collect:将流转换成其他元素(toList()将流转换为列表)
- 流操作可以顺序执行,也可以并行执行
流与集合
- 集合是内存中的数据结构,包含数据结构中的所有值——集合中的每个元素都得先算出才能添加到集合中
- 流是在概念上固定得数据结构,元素是按需计算,流是延迟创建的集合(只有在消费者要求的时候才会计算值)
- 集合和流的关键区别之一:遍历数据的方式,集合利用迭代器来访问for-each循环中的内部成员
- 流只能遍历一次
- ==外部迭代和内部迭代
- 使用Collection接口需要用户去做迭代,被称为外部迭代,(for-each循环,Iterator迭代器—外部迭代)
- Streams库使用内部迭代——流将迭代做了,将得到的流值存在某个地方
流的使用
- 一个数据源:如集合,来执行一个查询
- 一个中间操作链:形成一条流的流水线
- filter——操作类型Predicate<T>——函数描述符T->boolean
- map——操作类型Function<T,R>——函数描述符T->R
- limit
- sorted——操作类型Comparator<T>——函数描述符(T, T)->R
- distinct
- 一个终端操作:执行流水线,并能生成结果
- forEach——消费流中的每个元素并对其应用Lambda。这一操作返回void
- count——返回流中元素的个数。这一操作返回long
- collection——把流归约成一个集合
使用流
筛选和切片
- 用谓词筛选:filter方法,接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流
- 筛选各异的元素:distinct方法,返回一个元素各异(根据流所产生元素的hashCode和equals方法实现)的流
- 截短流:limit(n)方法,该方法会返回一个不超过给定长度的流
- 跳过元素:skip(n)方法,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流
映射
- 对流中每一个元素应用函数:map方法,接受一个函数作为参数。函数应用到每个元素上将其映射成新的元素
- 流的扁平化:获得单词列表总各不相同的字符
- 使用map()与distinct()方法返回的为Stream<String[]>类型,而需要的为Stream<String>类型
- 使用map与Arrays .stream()(该方法可以接受一个数组并产生一个流)
- words.stream().map(w->w.split(“”)).map(Arrays::stream).distinct().collect(Collectors.toList()) 返回Stream<String>的列表
- 使用flatMap解决:
- words.stream().map(w->w.split(“”)).flatmap(Arrays::stream).distinct().collect(Collectors.toList()) 返回List<String>
- flatmap方法把流中的每一个值都转换成另一个值,然后把所有的流连接起来成为一个流,创建扁平流
查找和匹配
- 检查谓词是否至少匹配一个元素
- anyMatch方法——流中是否有一个元素能匹配给定谓词
- 检查谓词是否匹配所有元素
- allMatch方法——流中是否都能匹配给定谓词
- noneMatch方法——流中没有任何元素与给定谓词匹配
- findAny方法——将返回当前流中的任意元素
- Optional<T>类使一个容器类,代表一个值存在或不存在
- isPresent方法——将在Optional包含值得时候返回true
- ifPresent(Consumer<T> block)方法——在值存在时执行给定的代码块
- T get()方法——在值存在时返回值
- T orElse(T other)方法——会在值存在时返回值,否则返回一个默认值
- 查找第一个元素——findFirst方法
归约
- 归约操作(折叠) :将流中的元素组合起来,使用reduce操作来表达复杂的查询
- 元素求和:
- 使用reduce方法
- reduce方法接受两个参数,一个参数为初始值,另一个参数为BinaryOperator<T>为Lambda表达式
- Integer中具有sum方法可以使用进行求和
- 不接受初始值,返回Optional对象
- reduce方法接受两个参数,一个参数为初始值,另一个参数为BinaryOperator<T>为Lambda表达式
- 使用reduce方法
- 最大值和最小值
- 使用归约可以计算最大值和最小值
- Integer中的max方法可以计算最大值,min方法计算最小值
- 可以使用并行处理,将strean()换成parallelStream()即可实现
- 使用归约可以计算最大值和最小值
- 流操作:
- 无状态和有状态:
- 无状态操作:没有内部状态,假设用户提供的Lambda或方法引用没有内部可变状态
- 如map或filter等操作会从输入流中获得每一个元素,并且在输出流中得到0或者1个结果
- 有状态操作
- 无状态操作:没有内部状态,假设用户提供的Lambda或方法引用没有内部可变状态
- 无状态和有状态:
数值流
- 原始类型流特化,专门支持数值流的方法
- 原始类型流特化
- 三个原始类型特化流接口:IntStream , DoubleStream , LongStream 分别将流中的元素特化为int , long 和long类型
- 避免了暗含的装箱操作成本
- 映射到数值流:maoToInt mapToDouble mapToLong
- 转换回对象流:boxed()方法——可以将原始流转换为一般流(每个元素会自动装箱成为一个引用类型)
- 默认值OptionalInt:存在Optional原始类型特化版本 OptionalInt OptionalDouble OptionalLong
- 可以使用orElse方法,在不存在时设置一个默认值
- 三个原始类型特化流接口:IntStream , DoubleStream , LongStream 分别将流中的元素特化为int , long 和long类型
- 数值范围
- range()方法不包含结束值,rangeClosed()方法包含结束值
构建流
- 由值创建流:可以使用静态Steam.of方法显式创建一个流,使用Steam.empty()方法创建一个空流
- 由数组创建流:可以使用静态Arrays.steam方法从数组创建一个流
- 由文件创建流:
- java.nio.file.Files中的很多静态方法都支持返回一个流
- Files.lines返回一个由指定文件中各行构成的字符串流
- 由函数生成流
- 无限流:不像从固定集合创建的流那样有固定大小的流
- Stream.iterate和Stream.generate方法可以生成无限流
- generate接受一个Supplier<T>类型的Lambda提供新的值
- 使用iterate的方法则是纯粹不变的:它没有修改现有状态,但在每次迭代时会创建新的元组。而generate方法会使Supplier实例的状态产生变化
用流收集数据
归约和汇总
- 查找流中的最大值和最小值
- 两个收集器:Collectors.maxBy和Collectors.minBy来计算流中的最大值或最小值 接收器接收一个Comparator参数来比较流中的元素
- 汇总
- 汇总的工厂方法:Collectors.summingInt 接受一个把对象映射为求和所需int的函数,并返回一个收集器,该收集器在传递给普通的collect方法后执行汇总操作
- Collectors.summingLong Collectors.summingDouble ——求和 averagingLong averagingDouble 计算平均值
- summarizingInt summarizingLong summarizingLong方法 返回的收集器——可以得到元素个数,总和,平均值,最大值和最小值——返回IntSummaryStatistics类,LongSummaryStatistics类,DoubleSummaryStatistics类
- 汇总的工厂方法:Collectors.summingInt 接受一个把对象映射为求和所需int的函数,并返回一个收集器,该收集器在传递给普通的collect方法后执行汇总操作
- 连接字符串
- joining工厂方法——对流中每一个对象引用toString方法得到的所有字符串连接成一个字符串
- 重载版本可以设置元素之间的分界符
- 若类具有toString方法,则无需重新提取字符串
- joining在内部使用了StringBuilder来把生成的字符串逐个追加起来
- joining工厂方法——对流中每一个对象引用toString方法得到的所有字符串连接成一个字符串
- 广义的归约汇总
- Collectors.reducing方法使所有特殊情况的一般化
- 三个参数
- 第一个参数使归约操作的起始值,也是流中没有元素的返回值
- 第二个参数
- 第三个参数使BinaryOperator,将两个项目累积成一个同类型的值
- 单参数形式
- 三个参数形式的特殊情况
分组
- Collectors.groupingBy工厂方法可以实现分类操作,其参数为一个分类函数,分组的结果保存在一个Map中
- 多级分类:
- 双参数版本的Collectors.groupingBy可以实现多级分类
- 其传入参数除了普通的分类函数之外,还可以接受Collectors类型的第二个参数,利用内层groupingBy传递给外层groupingBy,其类型为二级标准
- 双参数版本的Collectors.groupingBy可以实现多级分类
- 按子组收集数据:
- Collectors.groupingBy的第二个参数可以使任意类型,如可以传递counting收集器作为参数统计数量
- 单参数的groupingBy(f)实际上使groupingBy(f,toList())的简便写法
- 将收集器的结果转换为另一种类型: Collectors.collectingAndThen工厂方法第一个参数为要转换的收集器,第二个参数为转换函数
- Collectors.mapping——该方法接受两个参数,一个函数对流中的元素进行转换,另一个将变换的结果收集起来
分区
- 分组的特殊情况:由一个谓词作为分类函数,称为分区函数,分区函数返回一个布尔值,得到的Map的键为Boolean类型
- 分区函数 partitioningBy——其传递的函数为分区函数
- 分区的好处:保留了分区函数返回true或False的两套流元素列表
- partitioningBy——重载版本,第一个参数为分区函数,第二个参数为收集器
- partitioningBy收集器也允许结合其他收集器使用,可以实现多级分区
收集器接口
- Collector接口:T是流中要收集的项目的泛型,A是累加器的类型(累加器是在收集过程中用于累计部分结果的对象),R是收集操作得到的对象的类型
- 建立新的结果容器:supplier方法
- 将元素添加到结果容器:accumulator方法
- 对结果容器应用最终转换:finisher方法
- 合并两个结果容器:combiner方法
- characteristics方法——返回一个不可变的Characteristics集合,它定义了收集器的行为——尤其是关于流是否可以并行归约,以及可以使用哪些优化的提示,为三个项目的枚举
- UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响
- CONCURRENT——accumulator函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为UNORDERED,那它仅在用于无序数据源时才可以并行归约
- IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。这也意味着,将累加器A不加检查地转换为结果R是安全的
- 调用自定义实现Collector接口的类时,需要使用new方法进行实例化(toList是工厂方法,故不需要new进行实例化)
- 可直接在重载的collect()方法中接受三个函数supplier,accumlator和combiner函数,实现上述操作
- 第二个collect方法不能传递任何Characteristics,所以它永远都是一个IDENTITY_FINISH和CONCURRENT但并非UNORDERED的收集器
1 | public interface Collector<T,A R>{ |
并行数据处理与性能
并行流
- parallelStream 方法 ——将集合转换为并行流
- 并行流将内容分成多个数据块,并用不同的线程分别处理每个数据块的流
- 将顺序流转换为并行流
- 对顺序流调用parallel方法转换为并行流——函数的归约过程并行运行
- 对并行流调用sequential方法转换为顺序流
- iterate产生的是装箱的对象,必须拆箱成数字才能求和
- 高效使用并行流
- 留意装箱
- 留意数据结构是否易于分解
- ArrayList IntStream等 可分解性极佳 > HashSet TreeSet 分解性较好 > LinkedList 原生Stream
分支合并框架(Fork/Join框架)
- 以递归方式将可并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果,把子任务分配给- ForkJoinPool(线程池)中的工作线程
1 | // R是并行化任务产生的结果类型 |
- 使用分支/合并框架的最佳做法
- 对一个任务调用join方法会阻塞调用方,直到该任务做出结果**(有必要在两个子任务的计算都开始之后再调用它。否则,你得到的版本会比原始的顺序算法更慢更复杂,因为每个子任务都必须等待另一个子任务完成才能启动)**;
- 不应该在RecursiveTask内部使用ForkJoinPool的invoke方法。相反,你应该始终直接调用compute或fork方法,只有顺序代码才应该用invoke来启动并行计算;
- 对子任务调用fork方法可以把它排进ForkJoinPool。同时对左边和右边的子任务调用它似乎很自然,但这样做的效率要比直接对其中一个调用compute低。这样做你可以为其中一个子任务重用同一线程,从而避免在线程池中多分配一个任务造成的开销;
- 和并行流一样,你不应理所当然地认为在多核处理器上使用分支/合并框架就比顺序计算快。我们已经说过,一个任务可以分解成多个独立的子任务,才能让性能在并行化时有所提升
Spliterator
- Java8中引入的一个新接口,为可分迭代器,用于遍历数据源中的元素,但其为了并行执行、
- tryAdvance方法的行为类似于普通的Iterator,按顺序一个一个使用Spliterator中的元素,并且如果还有其他元素要遍历就返回true
- trySplit是专为Spliterator接口设计的,可以把一些元素划出去分给第二个Spliterator(由该方法返回),两个并行处理
- Spliterator还可通过estimateSize方法估计还剩下多少元素要遍历,因为即使不那么确切,能快速算出来是一个值也有助于让拆分均匀一点
- Spliterator接口声明的最后一个抽象方法是characteristics,它将返回一个int,代表Spliterator本身特性集的编码
- 拆分过程:递归过程拆分直至调用trySplit方法返回null,受Spliterator本身特性影响,该特性通过characteristics方法声明
1 | public interface Spliterator<T>{ |
默认方法
- Java8允许在接口内声明静态方法,同时引入了默认方法,通过默认方法可以指定接口方法的默认实现
- Java的类只能继承单一的类,但一个类可以实现多接口
- 可以使用代理有效地规避代码复用的复杂性,即创建一个方法通过该类的成员变量直接调用该类的方法
- 为什么有的时候我们发现有些类被刻意地声明为final类型:
- 声明为final的类不能被其他的类继承,避免发生这样的反模式,防止核心代码的功能被污染
- 为什么有的时候我们发现有些类被刻意地声明为final类型:
- 解决默认方法签名相同时产生的冲突问题(一个类使用相同的函数签名从多个地方(比如另一个类或接口)继承了方法):
- 类中的方法优先级最高。类或父类中声明的方法的优先级高于任何声明为默认方法的优先级
- 如果无法依据第一条进行判断,那么子接口的优先级更高:函数签名相同时,优先选择拥有最具体实现的默认方法的接口,即如果B继承了A,那么B就比A更加具体
- 最后,如果还是无法判断,继承了多个接口的类必须通过显式覆盖和调用期望的方法,显式地选择使用哪一个默认方法的实现
用Optional取代null
- 避免遇到NullPointerException异常
- Optional<T>
- 变量存在时,Optional类只是对类简单封装;
- 变量不存在时,缺失的值会被建模成一个“空”的Optional对象,由方法Optional.empty()返回
- 创建Optional对象
- 声明一个空的Optional:Optional.empty()静态方法——返回Optional类的特定单一实例
- 依据一个非空值创建Optional:Optional.of()静态方法——依据非空值创建一个Optional对象
- 可接受null的Optional:Optional.ofNullable()静态方法——创建一个允许null值得Optional对象
- 函数方法
- map方法——使用map从Optional对象中提取和转换值;map操作会将提供的函数引用于流的每个元素,可以把Optional对象堪称一种特殊的集合数据(如果Optional包含一个值,那函数就将该值作为参数传递给map,对该值进行转换。如果Optional为空,就什么也不做)
- flatMap方法——将两层的Optional对象转换为单一Optional对象,使用flatMap链接Optional对象
- get()——最简单但不安全,若变量存在返回封装的变量值,否则抛出NoSuchElementException异常
- orElse(T other)——允许在Optional对象不包含值时提供一个默认值
- orElseGet(Supplier< ? extends T> other)——Supplier方法只有在Optional对象不含值时才执行调用
- orElseThrow(Supplier<? extends X> exceptionSupplier)——遭遇Optional对象为空时都会抛出一个可定制的异常
- ifPresent(Consumer<? super T>)——在变量值存在时执行一个作为参数传入的方法,否则就不进行任何操作
- isPresent()——如果Optional对象包含值,该方法就返回true
- filter()——方法接受一个谓词作为参数;如果Optional对象的值存在,并且它符合谓词的条件,filter方法就返回其值;否则它就返回一个空的Optional对象
新的日期和时间API
- LocalDate
- LocalDate.of()——创建一个LocalDate实例
- LocalDate.now()——从系统时钟中获取当前日期
- get()——传递TemporalField参数获取某个字段的值(ChronoField枚举实现了TemporalField接口)
- parse()静态方法——格式化一个日期或者时间对象
- LocalTime
- LocalTime.of()——创建LocalTIme实例
- getHour getMinute getSecond
- parse()静态方法——格式化一个日期或者时间对象
- LocalDateTime
- 是LocalDate和LocalTime的合体,同时表示了日期和时间,但不带有时区信息
- of方法
- atTime()方法——传递日期对象或者时间对象创建
- toLocalDate或toLocalTime方法——提取LocalDate或LocalTime组件
- Instant类
- 计算机角度的建模时间,表示一个持续时间段上某个点的单一大整型数
- ofEpochSecond()——传递一个代表秒数的值创建该类的实例
- 重载版本,接受第二个以纳秒为单位的参数值,对传入作为秒数的参数进行调整
- now()——获取当前时刻的时间戳
- Duration类和Period
- Duration类静态方法between——传递两个LocalTimes对象,LocalDateTimes对象,Instant对象,获得两个对象之间的时间长短(秒和纳秒)
- Period类静态方法between——得到LocalDate之间的时长
- 使用TemporalAdjuster:with()——传递一个提供定制化选择的TemporalAdjuster对象,更加灵活的处理日期
- 打印输出及解析日期-时间对象:
- DateTimeFormatter类:创建格式器最简单的方法是通过静态方法和常量,BASIC_ISO_DATE和ISO_LOCAL_DATE- 为DateTimeFormatter类的预定义实例
- parse()静态方法——使用同样的格式器解析字符串并重建该日期对象
- ofPattern()方法——创建某了Local的格式器
- DateTimeFormatterBuilder类提供更加复杂的格式器
- DateTimeFormatter类:创建格式器最简单的方法是通过静态方法和常量,BASIC_ISO_DATE和ISO_LOCAL_DATE- 为DateTimeFormatter类的预定义实例