引言
哔哩哔哩学习食鱼者的ISP视频笔记
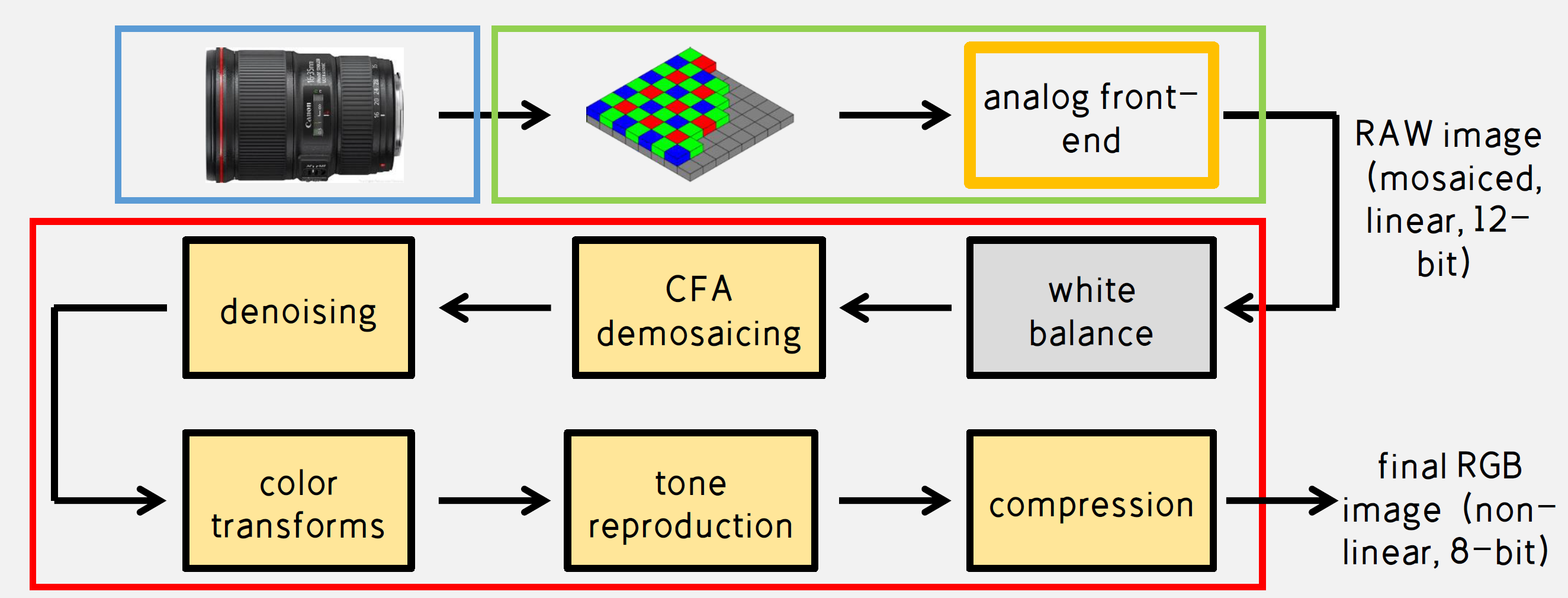
1 ISP Pipeline
- BAYER格式简介
- 色光三原色RGB展示真实世界中的物体
- CMOS SENSOR: 为三维矩阵数据,分别表示R,G,B三个通道的数据
- BAYER数据: 为二维数据, 其中每个元素表示R,G,B中的一个值
- BAYER数据二维矩阵(单通道),每个像素点为一个通道的数据,其中整个矩阵为R,G,B的组合排列
- 根据中间的像素的排布可以分为GRBG, RGGB等

- Pipeline
- lens->sensor->ISP/DSP(主控芯片)
- sensor: bayer filter(bayer滤光片)和sensor(coms,ccd)
- Basic处理流程: bayer raw data -> DPC -> BLC -> Denoise -> LSC -> AWB -> Demosiac -> CCM -> Gamma -> EE -> CSM -> YUV
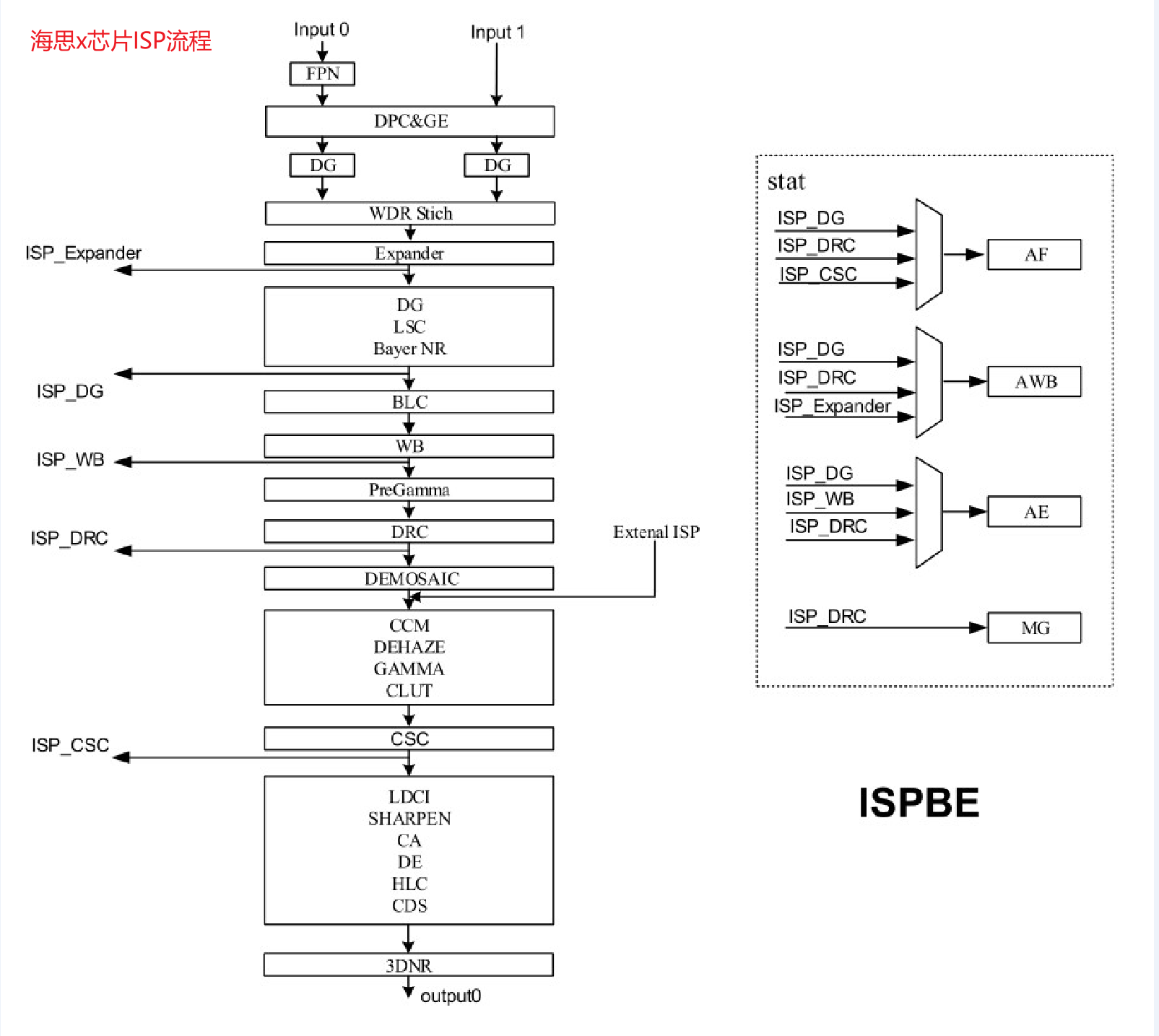
- DPC: defect pixel correction(坏点检测)
- 由sensor工艺造成,在工作时像素点不工作或工作性能较差(表现为图像中的亮点或暗点)
- BLC: Black Level correction
- 由于芯片的暗电流,造成黑色不黑

- Denoise/NR (降噪)
- LSC: Lens Shading Correction
- 在拍摄时,借助灰阶卡片进行矫正

- AWB: Auto White Balance
- 色温
- A光: 2850K
- 色温
- Demosiac(去马赛克)

- CCM(Color Correction Matrix)颜色矫正
- Gamma
- 主要对亮度有影响,进而对颜色有影响

- EE(Edge Enhance): 边缘增强
2 BLC
2.1 BL产生的原因
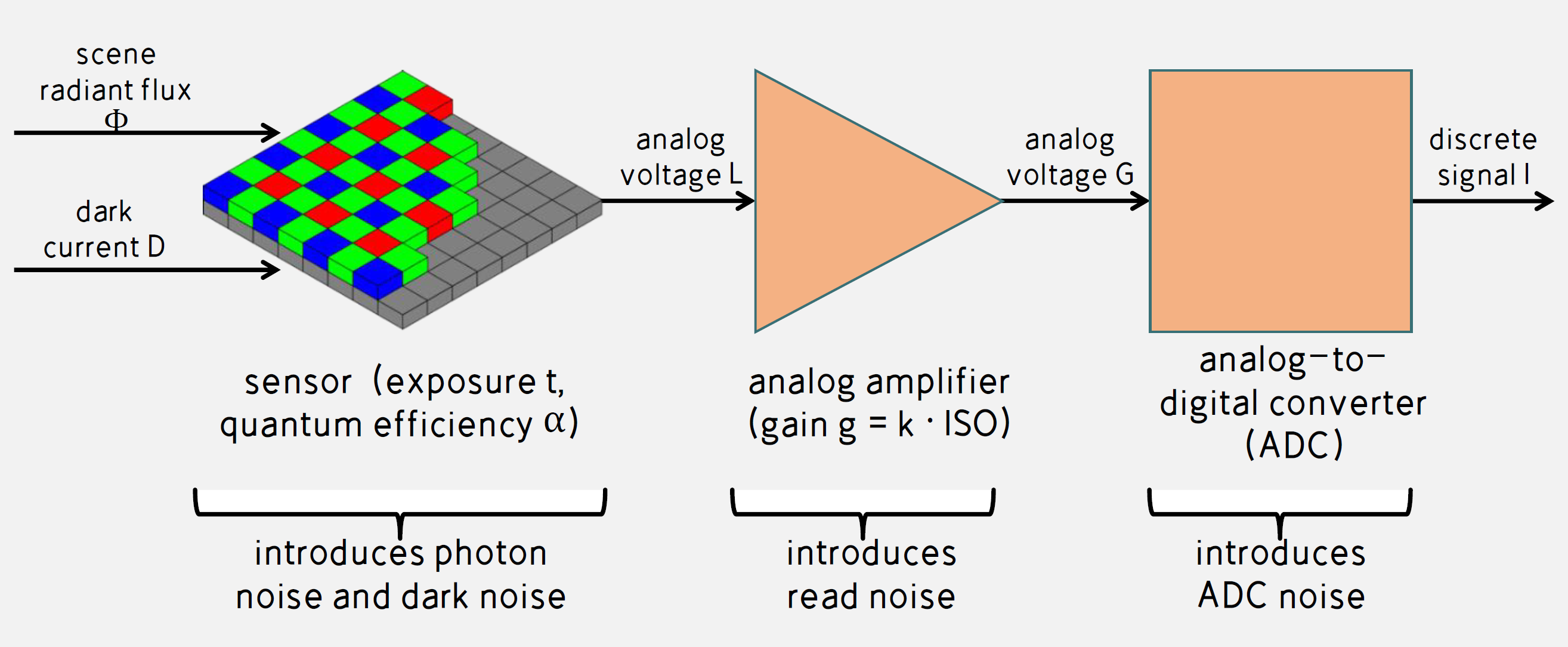
- 暗电流
- 指在没有光照射的状态下,在光敏二极管,光导电元件,光电管等的受光元件中流动的电流,一般由于载流子的扩散或者器件内部缺陷噪声
- 常用的COMS为光电元件,在光照为0时也会有电压输出
- COMS内部为PN结,其符合二极管的伏安特性曲线,工作在反向电压下,在无光照时的微小电流为暗电流
- AD前添加一个固定值
- sensor到ISP会存在一个AD转换过程,而AD芯片具有一个灵敏度,当电压低于该阈值时无法进行AD转转,故人为添加一个常量将低于阈值的部分能被AD转换
- 人眼对暗部细节更加敏感,故增加一个常量牺牲人眼不敏感的亮区保留更大暗部细节
2.2 BL校正
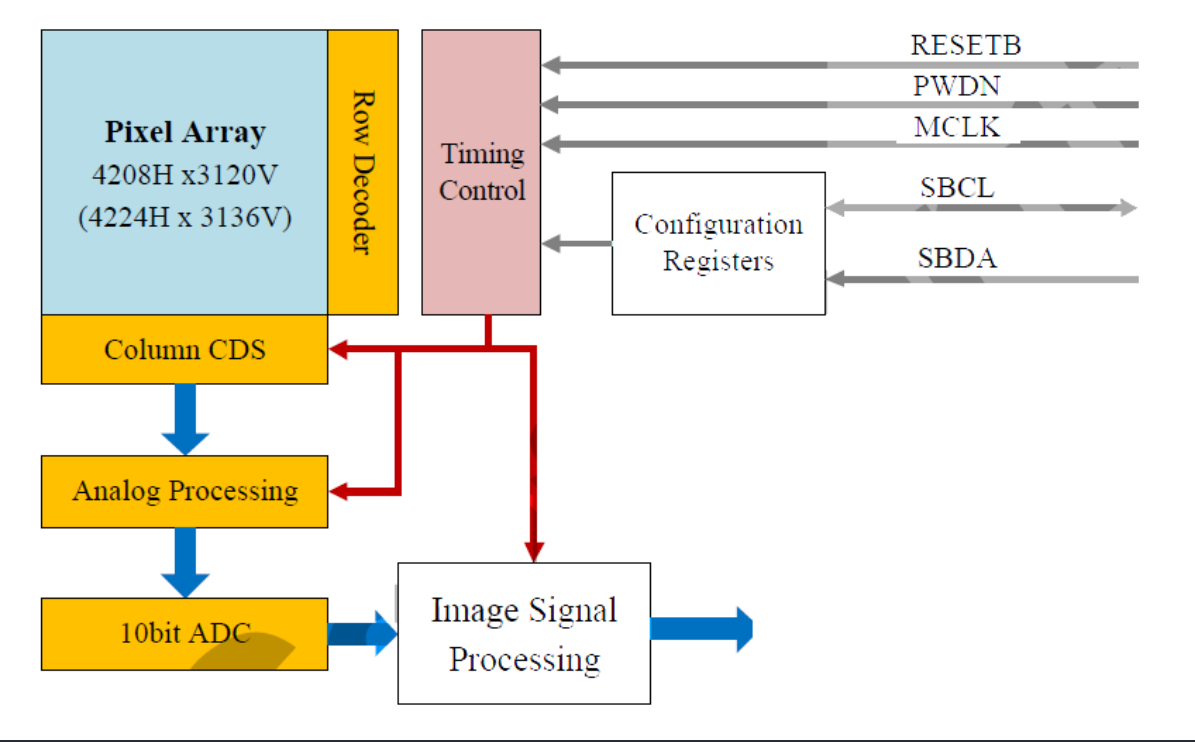
BL校正分为sensor端和isp端两部分,重点介绍isp端的算法
- sensor端算法(下图所示)
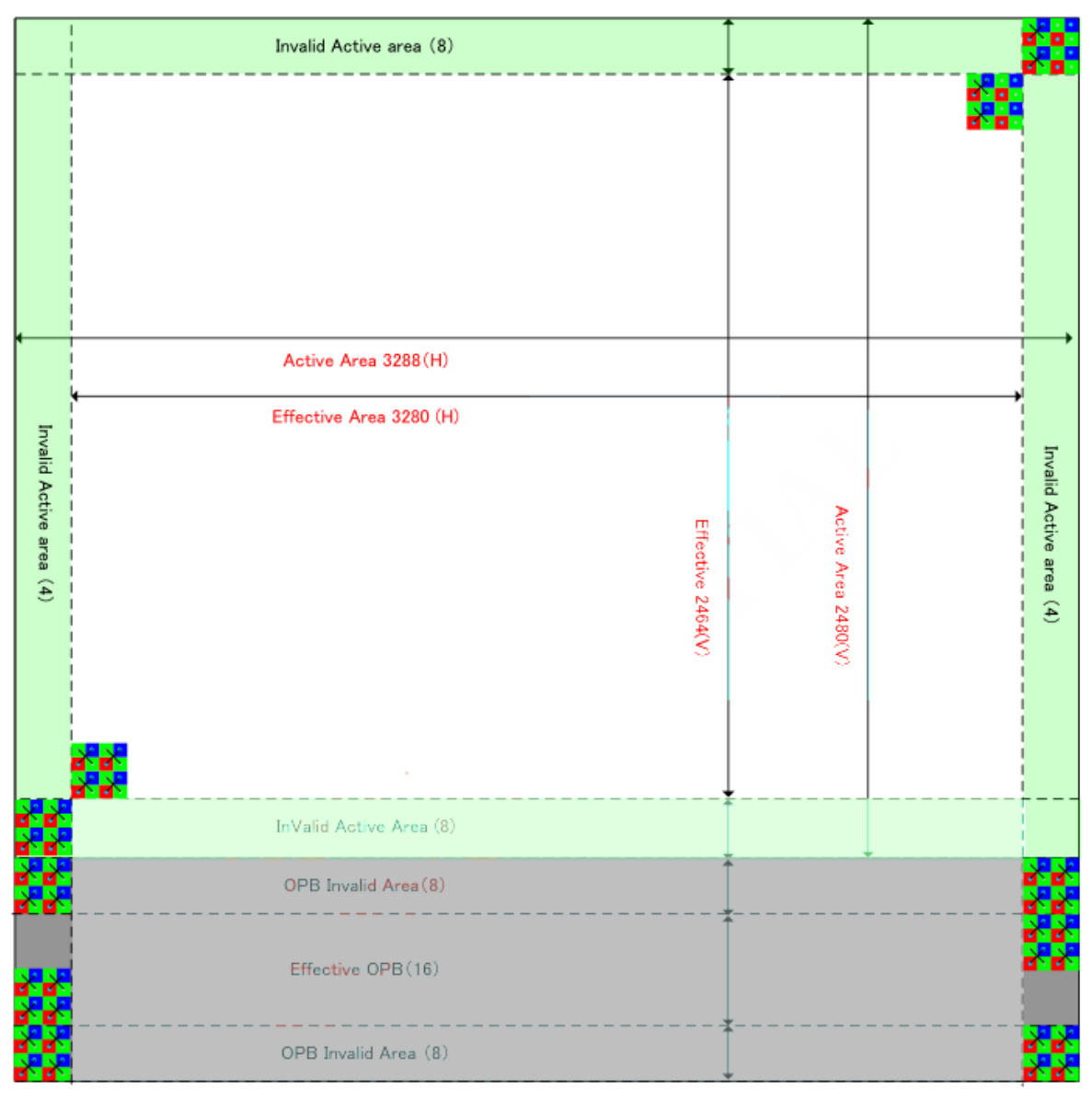
- 有效像素区:3280*2464(最大出图分辨率)
- Effective OPB: 有效OB区
- 有效像素区可以正常曝光,OB区在工艺上不能接受光子(在感光表面涂黑色不感光物质),利用OB区无光照的值完成校正有效像素的值
- 最简单的校正做法: 利用OB区像素值取均匀,利用每个像素的值减均值完成校正
- 比亚迪专利(
CMOS传感器及图像中黑电平的调整方法):分别计算每个颜色通道黑电平的平均值,计算CMOS传感器图像中黑电平的目标值,分为计算每个颜色通道内黑电平平均值和目标值差值的绝对值,当某个颜色通道内黑电平平均值和目标值差值绝对值大于阈值时,对对应颜色通道内的黑电平平均值进行模拟调整,小于阈值时进行数字调整 - 思特威专利(
图像传感器的黑电平校正方法及系统):将OB区分为左,中,右三个区域,对区域内曲线进行拟合,根据曲线进行校正
- isp端: 对黑帧RAW图进行处理(以8位为例)
- 扣除固定值法(简单粗暴): 每个通道扣除一个固定值
- 采集黑帧RAW图,将其分为四个通道
- 计算校正值:对四个通道求平均值(或中位值,或其他)
- 后续图像的每个通道都利用上一步的校正值进行校正
- 对通道进行归一化,将平移后的最大值恢复到255,
- R和B通道不进行归一化, 后续AWB通过gain将其范围提升至0-255
- ISO联动法: 暗电流和gain值和温度等相关,通过联动的方式确定每个条件下的校正值,后续依据参数查表得到校正值进行校正
- 初始化一个ISO值(AG和DG的组合), 然后重复固定值中的做法,采集黑帧,标定各个通道的校正值
- 在初始化ISO的基础上通过等差或等比数列的方式增长iso,重复步骤1求取各个通道的校正值
- 将二维数据做成LUT,后续图像通过ISO值查找或插值的方式获取相应的校正值进行校正
- 曲线拟合法: 实际在像素不同位置黑帧的数据不一样,更准确的方式为每个点求出一个校正值进行校正
- 在黑帧中选择一部分像素点求出校正值,将坐标和校正值存在LUT中,后续其他像素点的校正值可以通过坐标和LUT进行线性插值求校正值以进行精准校正
- 扣除固定值法(简单粗暴): 每个通道扣除一个固定值
- sensor端可以进行模拟处理和数字处理
- isp端只能进行数字处理,其接受的信号是通过AD转换得到的数字信号,可以通过数字处理的方式进行校正,节省硬件资源
3 LSC

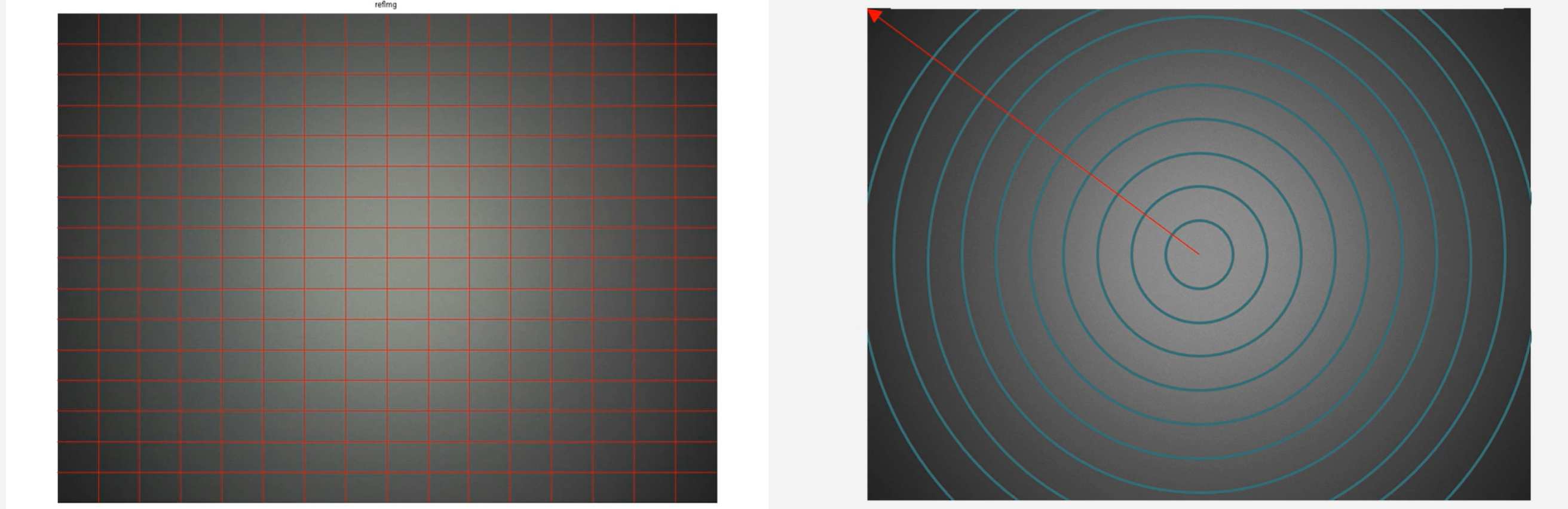
上图为拍摄灰度色卡时的shading的具体现象,左侧为Luma shading,右侧为color shading
3.1 LS现象及原因
- Luma shading的产生原因: 光学渐晕现象
- 镜头中心到边缘的能量衰减导致,通常表现为亮度向边缘衰减变暗,通常衰减符合
- Color shading的产生原因: 色像差(位置色差和倍率色差)
3.2 校正方法
- 在标定时使用D65,D50拍摄15%灰度图像,目标灰度以最大值(或中位值,或均值)
- LSC的本质为能量衰减,为了校正,就使用该点的像素值乘以一个gain值,让其恢复到衰减前的状态
- LSC校正的本质就是找到gain值
- 目前的校正算法可以分为:1. 储存增益法, 2. 多项式拟合法, 3. 自动校正法(不常见)
- 储存增益法
- mesh shading correct(网格法):将图像分为n*n个网格,然后针对网格顶点求出校正的增益,然后把这些顶点的增益储存到内存中,其他点的增益通过插值算法求出
- radial shading correct(半径法):用半径为变量来求出不同半径像素所需要的增益, 然后将半径对应的增益储存在内存中,使用时查表取出增益进行校正
- 通过采样的方式提取半径的增益储存到内存,然后其他半径对应的增益在校正时通过插值算法求出
- 该方法受限较多,使用较少,如镜头中心会发生偏移,导致使用该方法进行校正时不匹配
- 多项式拟合方法:分段式线性补偿或高次函数拟合方法
- 对图像的target亮度,取图像的中心,以不同的半径为采样点,计算该半径下所有像素的均值与target的比例,该比例为gain值,对不同半径的gain值进行处理即可获取不同位置处的gain值
- 分段式线性补偿:使用分段函数进行解决
- 高此函数拟合:
- 以半径为采样点,然后把这些采样点通过高次拟合的方法拟合为高次曲线,然后把高次曲线的参数储存起来,使用时将半径带入公式求出对应的gain值用于校正
- 可采用拉格朗日插值法进行插值:
- 针对光学中心不是图像中心的问题,可在图像中找出光学中心,然后以光学中心为真实中心完成标定,随后代入公式求出gain值
3.3 插值算法
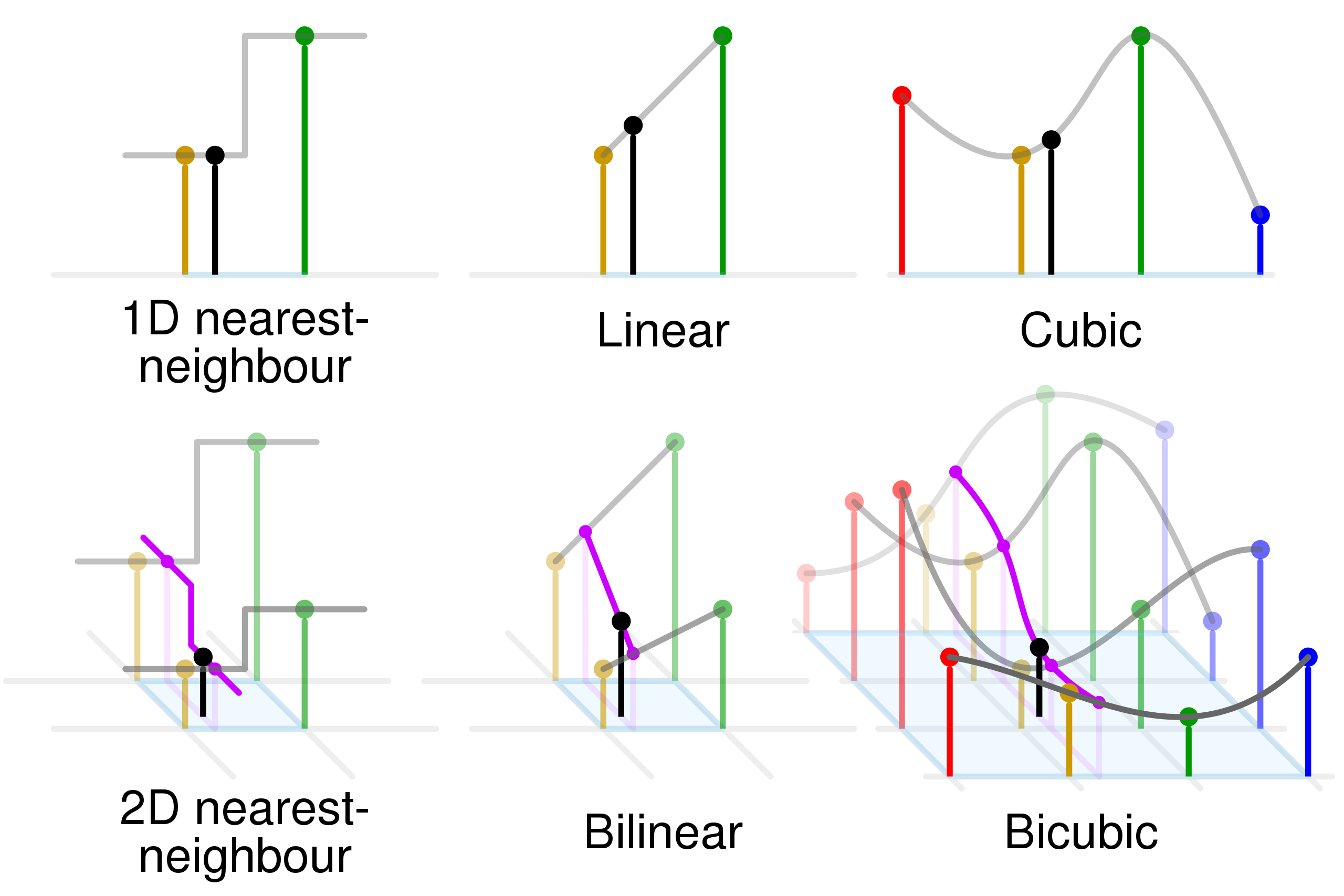
- 邻域插值:
- 在代码中为了减小运算量,判断该点位于4个象限的哪一个象限,随后使用该象限对应的值
- 线性插值:两个点进行插值
- 双线性插值:利用4个点进行3次线性插值可以计算出对应点的值
- 利用同一行的和线性插值出,随后利用插值得到该目标点的值
- 双三次插值算法
- 双三次插值
- 对于一个点,该点的值的确定需要16个点的值进行确定,其插值的曲面表示为 ,其插值问题即确定16个系数的值,其中利用四个角点的值和两个方向方向的8个偏导数以及4个混合偏导数可以确定上述系数
- 其公式为
- 双三次卷积算法
- 双三次样条插值需要对每个网格像元进行上述操作,在两个维度应用卷积核
- 其中a值通常为-0.5或-0.75,当时,一维方向上的方程为
- ISP中双三次插值
- 利用分段拟合曲线,从而求待求点
- 双三次插值
1 | %% -------------------------------- |
4 DPC(Defective Pixel Correction)
- 造成坏点的原因
- 感光元件芯片自身工艺技术瑕疵造成
- 光线采集存在缺陷
- 制造商产品差异
- 坏点分类
- hot pixel: 固定保持较高的像素值,呈现为亮点
- dead pixel: 固定保持较低的像素值,呈现为暗点
- noise pixel:信号强度随光照呈现的变化规律不符合正常的变化规律
- 校正方法
- 静态校正: 由sensor厂商在生产后进行标定,会使用OTP将所有像素位置记录下来,随后在校正时利用LUT颜色查找表通过查表得方式找到坏点进行校正
- 动态校正:在ISP算法中通过特殊算法判断一个点是否为坏点进行校正
4.1 动态算法讲解
- 静态坏点检测的局限性
- 标定方式需要消耗人力物力,且储存标定数据对硬件有要求
- 产品使用时间增加,坏点数目会增加,新增坏点没有进行标定
- 有些坏点表现为正常情况下的光电特性正常,长时间使用或高ISO时才会形成坏点
- 在实际应用时静态坏点检测disable
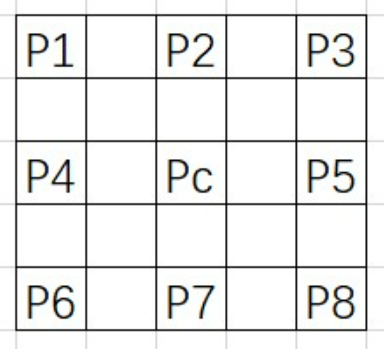
- pinto算法主要思想: 坏点往往是在一个领域中的极亮或极暗点故以5*5的邻域为检测区域
- 如图的5*5邻域内同一颜色通道相对于中心像素都有8个临近像素,校正步骤
- 计算中心像素与周围八个像素值的差
- 判断八个差值是否都为正值或负值
- 如果有的为正有的为负,那么就为正常值,否则进行下一步
- 设置一个阈值,如果8个差值的绝对值都超过阈值,就判断为坏点
- 判断为坏点后就用8个临近像素值得中位数来替换当前的像素值
- 该算法在实际使用中阈值的选择十分重要,当阈值较小时会将本该判断成边缘的信息去除,导致图像变模糊
- 梯度法:该算法针对三个通道都使用这一种窗口进行检测
- 计算四个方向的梯度
- 水平方向三个二阶梯度:
- 数值方向三个二阶梯度:
- 45°三个二阶梯度:
- 135°三个二阶梯度:
- 取出各个方向梯度绝对值的中值,同理求出其他三个方向的中值
- 求出四个中值的最小值作为边缘方向:
- 如果最小梯度方向为水平或者竖直,若过Pc那个梯度的绝对值大于同方向的另外两个梯度绝对值和的4倍,则Pc为坏点
- 如果是45°方向,则计算135°三个梯度绝对值两两之差的绝对值的和, 如果,若此时,则Pc为坏点。否则就为坏点
- 135°方向和45°相反的方向计算和判断即可
- 为减少漏判,当Pc小于15且周围点都大于40以上,则Pc为坏点。如果Pc大于230,且周围的点都下于Pc30以下,则该点为坏点
- 边缘为水平方向,且判断为坏点,如果则Pc更靠近P4,根据同一颜色通道亮度的渐变性可以推导出;否则;
- 如果为竖直方向可以参考水平方向求出
- 边缘为45°,如果则根据同一原则;否则为
- 边缘为135°则按照45°的方式反过来计算即可
- 计算四个方向的梯度
- DPC和demosaic结合法
- 思路:先对bayer图像插值成全彩图像,然后对每个点进行坏点检测,检测时只用同一通道的像素检测,而且每个像素点用的颜色通道即为该点raw图对应的颜色通道
- RGGB图像对于这四个点,第一个点只通过周围4个临近点的像素值中位数插值出的R值来检测R是否为坏点,其余两个同样这么处理,这样就保证和RAW处理时一样,只需要处理M*N个像素点即可。利用pinto算法进行检测,若该点为坏点就对其进行校正并重新对齐进行颜色插值,流程处理完坏点就被校正而直接输出全彩图像
- 在插值时部分算法使用周围8个临近点,但若该8个点中存在噪点,则对插值的影响较大,故一般使用周围4个像素点进行插值
- 行检测法:该算法检测和校正时不使用整帧图像,而是通过几行数据来处理,对硬件buffer要求低,CMOS也是行扫描,一次正好收集一行数据
- 缓存一行数据,在同一行中通过比较同一通道相邻的数据的插值,如果待检测的点同时大于相邻点一个阈值,或者同时小于相邻点一个阈值,那么这个点就是候选坏点
- 有的算法还会利用buffer缓存上一行的数据,然后判断这个坏点在当前行周围有没有候选坏点,并判断上一行对应位置的点是否为候选坏点,如果都不是,那么当前点就是真实坏点,就通过周围点矫正,如果周围有候选坏点,那么就判断为非真是坏点,不用矫正
- 在上一条提到的缓存的上一行数据,有的算法中不是缓存上一行每个像素的信息,而是上一行经过判断后的属性值,比如上一行存储的是每个点是否为候选坏点或者坏点,那么每个点就可以用0或者1来表示,那么上一行每个像素只需要1bit的数据量来存储,这样就能进一步降低对硬件的要求了
5 AWB
5.1 产生原因
- 色温的定义:色温描述的是具有一定表面温度的“黑体”的幅射光的光谱特性
- 颜色恒常性:指照度发生变化的条件下人们对物体表面颜色的知觉趋于稳定的心里倾向
- 白平衡原理:传感器不具有人眼的不同光照色温下的色彩恒常性,白平衡模块就需要将人眼看来白色的物体进行色彩的还原,使其在照片上也呈现为白色
5.2 校正方法
- 颜色空间
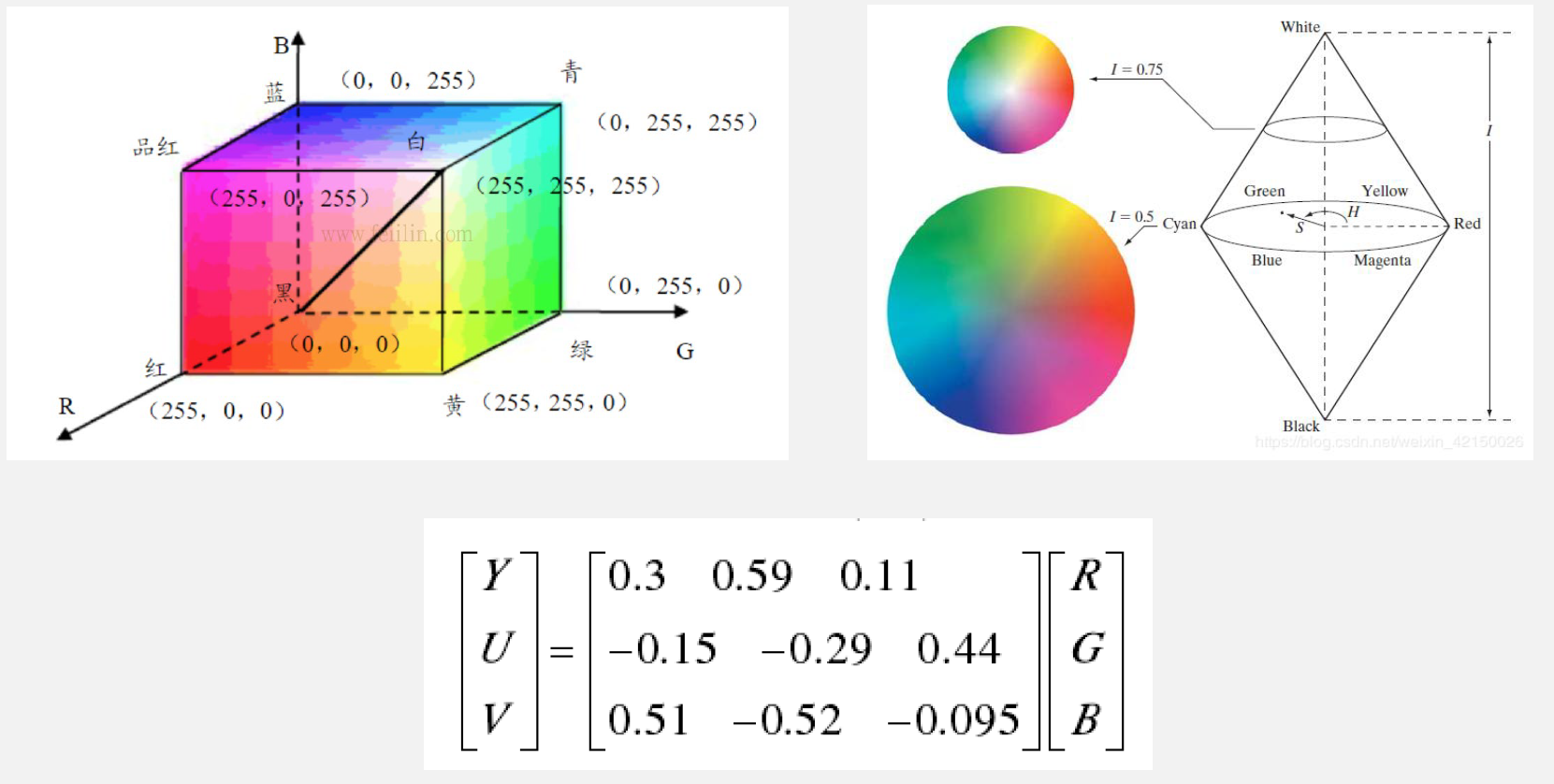
- Gray World Assumption(灰度世界方法)
- 理论:任一幅图像,当他有足够的色彩变化,则它的RGB分量的均值会趋于相等
- 流程:
- 计算各个颜色通道的平均值
- 寻找一个参考值K,一般选取(人眼对绿色较为敏感,不对G通道进行调整)
- 计算
- 进行校正
- 完美反射法
- 假设:图像中最亮的像素相当于物体有光泽或镜面上的点,传达了很多关于场景照明条件的信息。如果景物中有纯白的部分,那么就可以直接从这些像素中提取出光源信息。因为镜面或有光泽的平面本身不吸收光线,所以其反射的颜色即为光源的真实颜色,这是因为镜面或有光泽的平面的反射比函数在很长的一段波长范围内是保持不变的
- 算法执行时,检测图像中亮度最高的像素并且将它作为参考白点。基于这种思想的方法都被称为是完美反射法,也称镜面法,算法执行时检测图像中亮度最高的像素并且将它作为参考百点
- 通俗的意思就是整个图像中最亮的点就是白色或者镜面反射出来的,那么最亮的点就是光源的属性,但是该点本身应该是白点,以此为基础就可计算出gain值从而进行校正
- 流程
- 图像相关信息统计:
- RGB通道增益计算:
- 假设:图像中最亮的像素相当于物体有光泽或镜面上的点,传达了很多关于场景照明条件的信息。如果景物中有纯白的部分,那么就可以直接从这些像素中提取出光源信息。因为镜面或有光泽的平面本身不吸收光线,所以其反射的颜色即为光源的真实颜色,这是因为镜面或有光泽的平面的反射比函数在很长的一段波长范围内是保持不变的
- QCGP(将灰度世界和完全反射以正交方式结合),以R通道为例
- 通过上面的方程组就可以解出和 然后对原像素进行校正:
- 模糊逻辑算法
- 下图圆圈表示颜色本身应该在坐标系中所处的位置,箭头分别表示随色温的变化发生的偏移(先验知识获得,后面再通过这个进行校正)
- 将图像按下图两种方式分割成8块,然后通过模糊逻辑的方式计算出每个块的权重(和亮度,色温相关,通过模糊逻辑方式进行确定), 随后可计算出整个图像的加权均值
- 如下图10a,黑点表示八个块的分布,表示整幅图像均值的位置
- 通过调整增益的方式调试 往白点上靠,调整完增益后,每个块儿的均值又会发生变化,然后又重新计算出每个块的权重,再通过权重计算出整个图像的均值 ,如图10b, 已经靠近原点了(设定的范围内)则认为完成白平衡,否则继续调整增益重复上述步骤进行校正
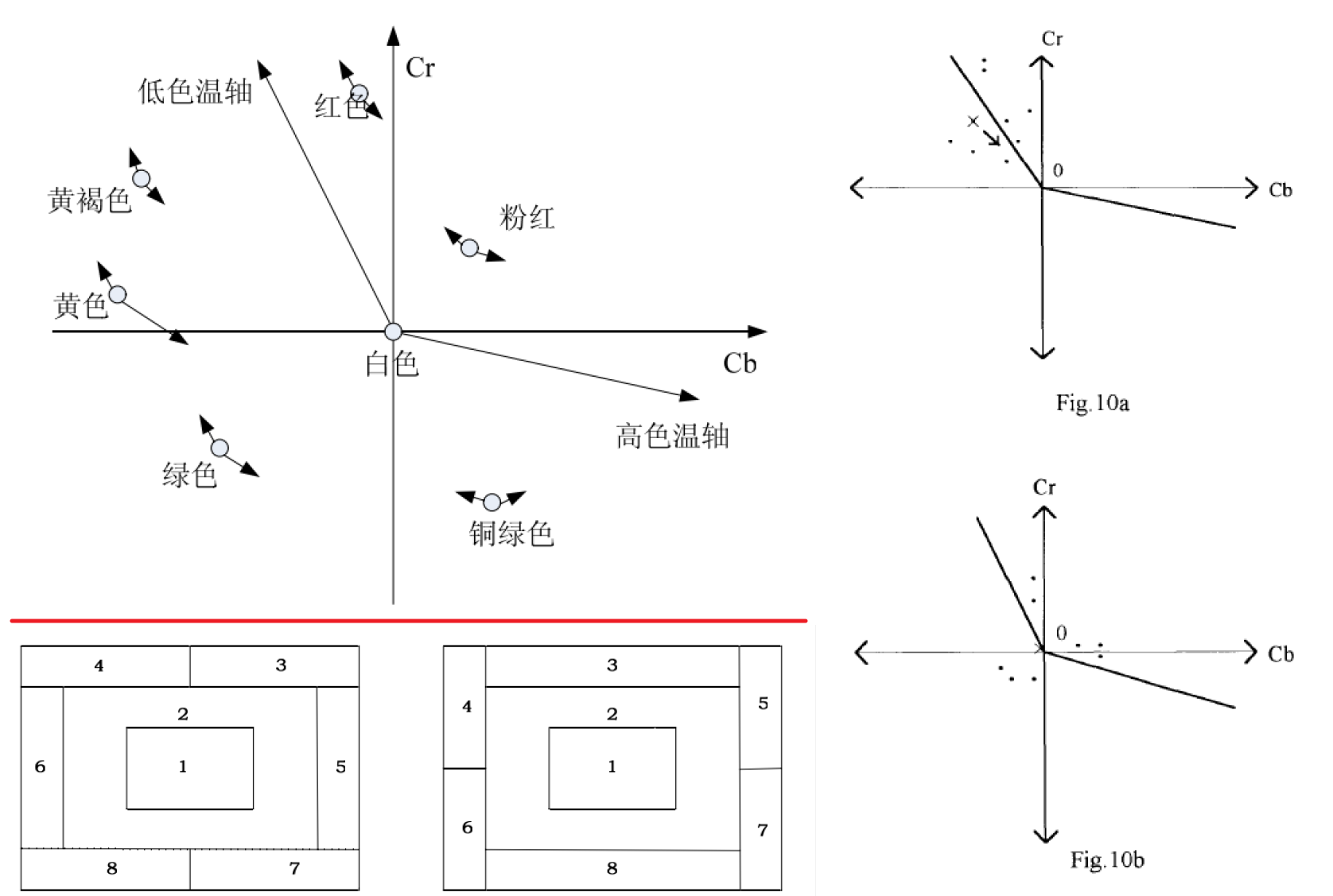
- 基于白点的算法
- 流程
- 将RGB颜色空间转换到YUV空间
- 通过限制YUV的区域判断是否为白点,满足条件的点为白点参与后续计算
- 找到白点集合后,可以对白点集合运用GW算法或其他算法计算GAIN值从而进行校正
- 流程
- 基于色温的方法
-
- 通过在不同色温的环境下拍摄灰卡可以得到两个曲线,一个是gain值的关系曲线,另一个是R/G与色温T的关系,如果获取了一张图像知道了拍摄的色温,就可以通过第二张图获取R/G的值,然后根据图1就可计算出B/G从而获得R和B的gain值
-
- 通过一定的技术手段获取色温即可
- 一种方法就是通过加一个色温传感器获取环境色温
- 另一种就是通过计算求出T(下图论文)
- 定义Tmin=2000K,Tmax=15000K;
- -Tmin是否大于10,如果小如或等于10,那么久可以直接返回T,此时T可以去min,man或者二者的均值,如果满足大于10的条件,则T=(Tmin+Tmax)/2;
- 通过图中公式(实验拟合总结),通过T就可以计算出一个R’G’B’
- 对于原始图像可以求出各个通道的均值RGB,如果B’/R’>B/R那么Tmax=T,否则Tmin=T;重复上述步骤即可迭代求出色温T
-

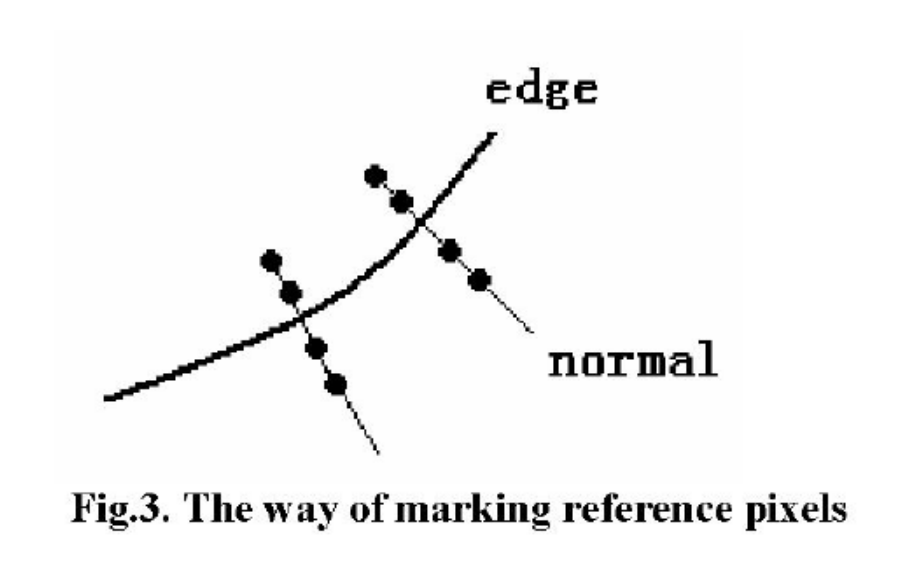
- 基于边缘的方法
- 流程
- 先通过一定的手段,比如梯度的方式求出图像中的边缘,然后在边缘各侧各取两个点参与计算
- 通过上述得到的参考点集合,就可以运行灰度世界或者其他的算法求出gain值
- 优点:
- 减少的大色块的干扰,因为一般认为边缘就是色块变化的的分界线,那么提取边缘两侧的样本点就可以满足颜色充分的条件,那么就可以运用灰度世界法求出gain
- 且有大色块的时候计算的也是也只是选取边缘的几个点,就可以避免大色块分量太大造成白平衡异常的问题。
- 流程
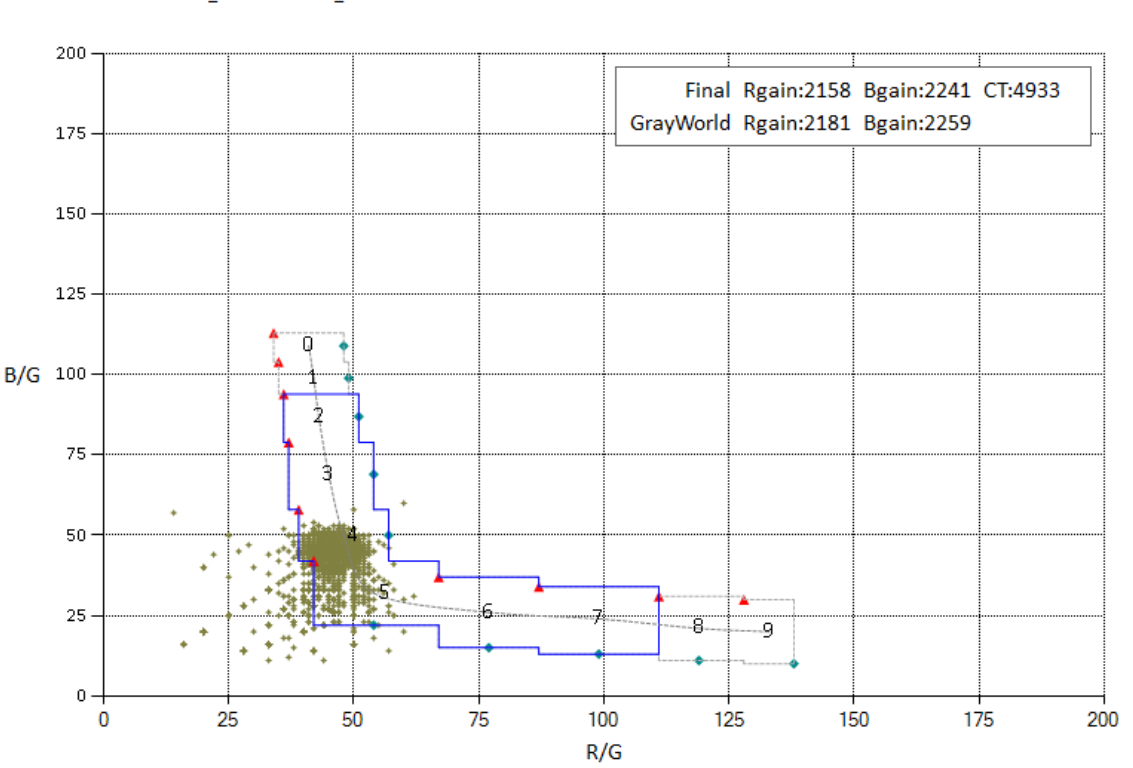
- 多种方法融合(色温和白点融合)
- 蓝色的框就代表一种色温(实验经验所得),比如9代表2000K,8代表2500K
- 绿色的点就是通过白点算法筛选出来的白点候选点
- 然后调试的时候就是在不同色温下拍摄灰卡,挪动蓝色选框,使其包围绿点,然后右上角就是估计色温,调试时使估计色温和真实色温相差最小。随后标定若干组色温确定该方案的一个色温曲线
- 后续在pipeline中通过白点检测算法筛选出白点,然后根据白点的分布,可以找到大多数白点分布的色温,该色温就是当前的色温,通过色温再按照前面提到的算法就可以计算出一个gain值,再和灰度世界算法进行一个混合就可以得到最终ISP中使用的gain值
6 Gamma
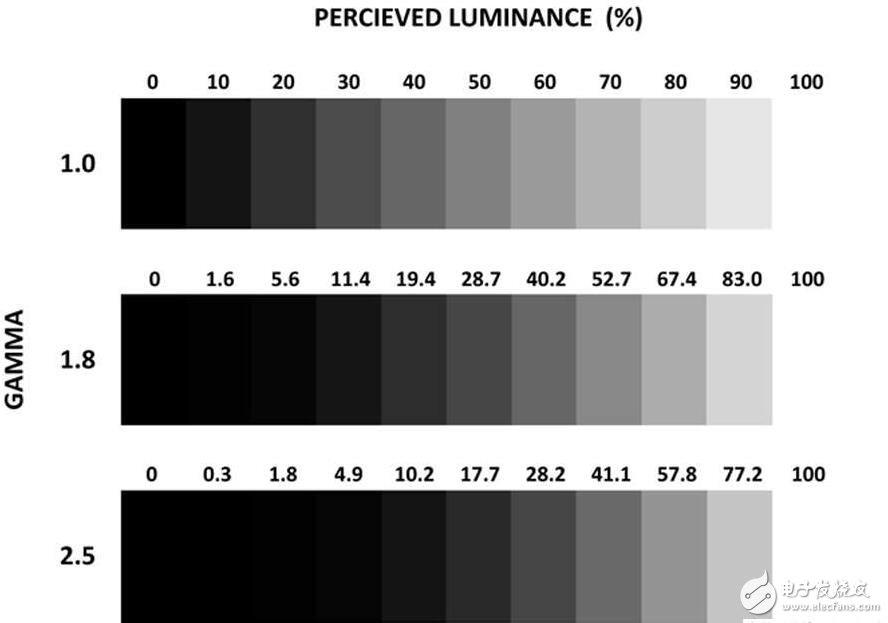
- Gamma主要影响对比度和动态范围,合适的对比度和动态范围不造成画面朦胧的感觉
6.1 产生原因
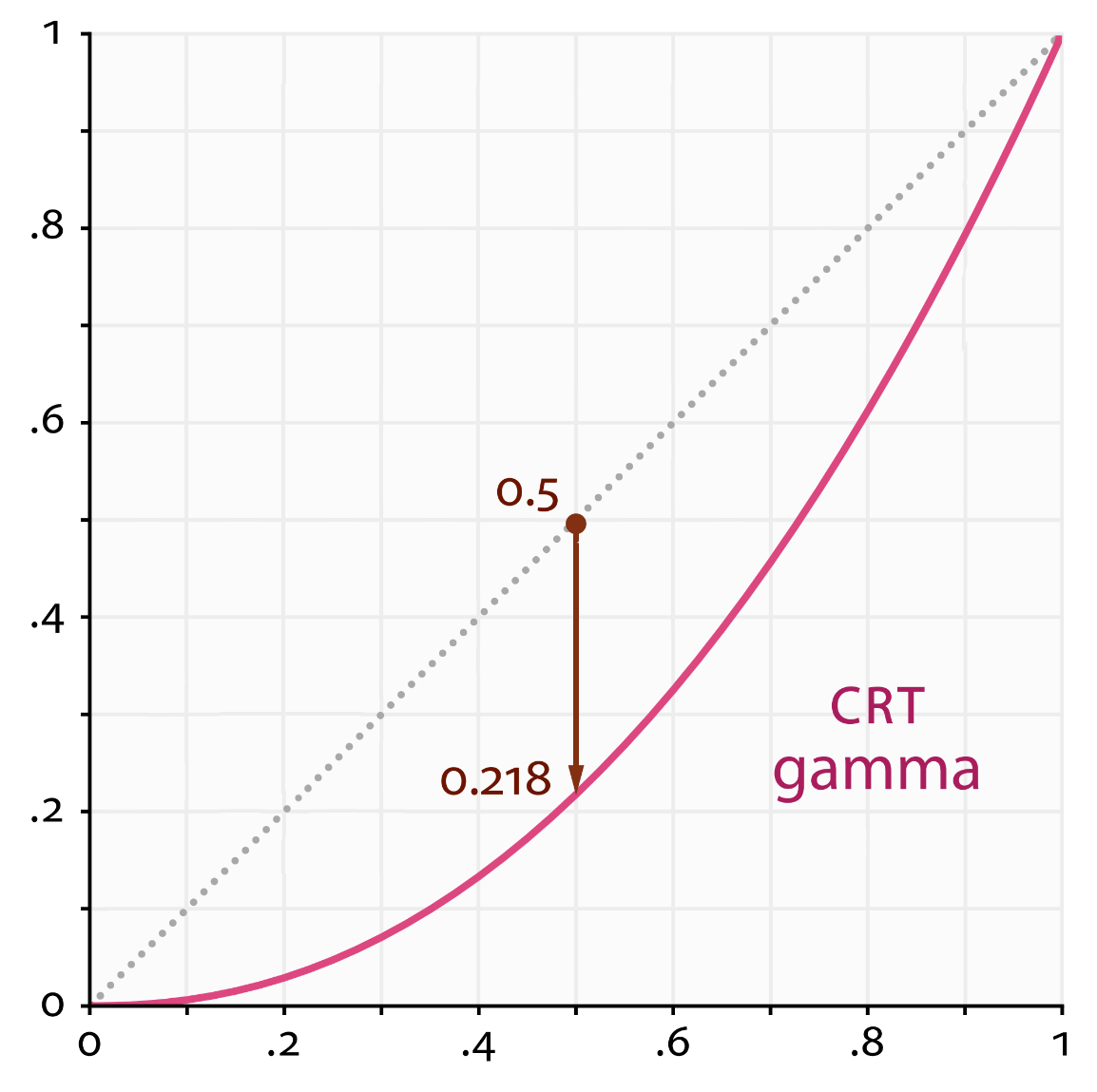
- CRT显示器属性导致
- 屏幕亮度和电子枪的电压为非线性关系,其符合对数关系, 为反gamma曲线:
- 因为显示时会把亮度压低,所以为了还原成原本的线性特征,需要在显示之前进行矫正,使其恢复为线性,此为gamma校正。现在液晶显示不满足该特性,但为了兼容以前的视频格式,也会认为在显示的时候添加反伽马矫正
- 人眼视觉属性
- 人眼的亮度响应曲线不是线性的,而是非线性属性
- 为了更好符合人眼的特性,就需要对暗区进行加强以提高画面的动态范围和暗区细节,更好的响应人眼对暗部更敏感的特性
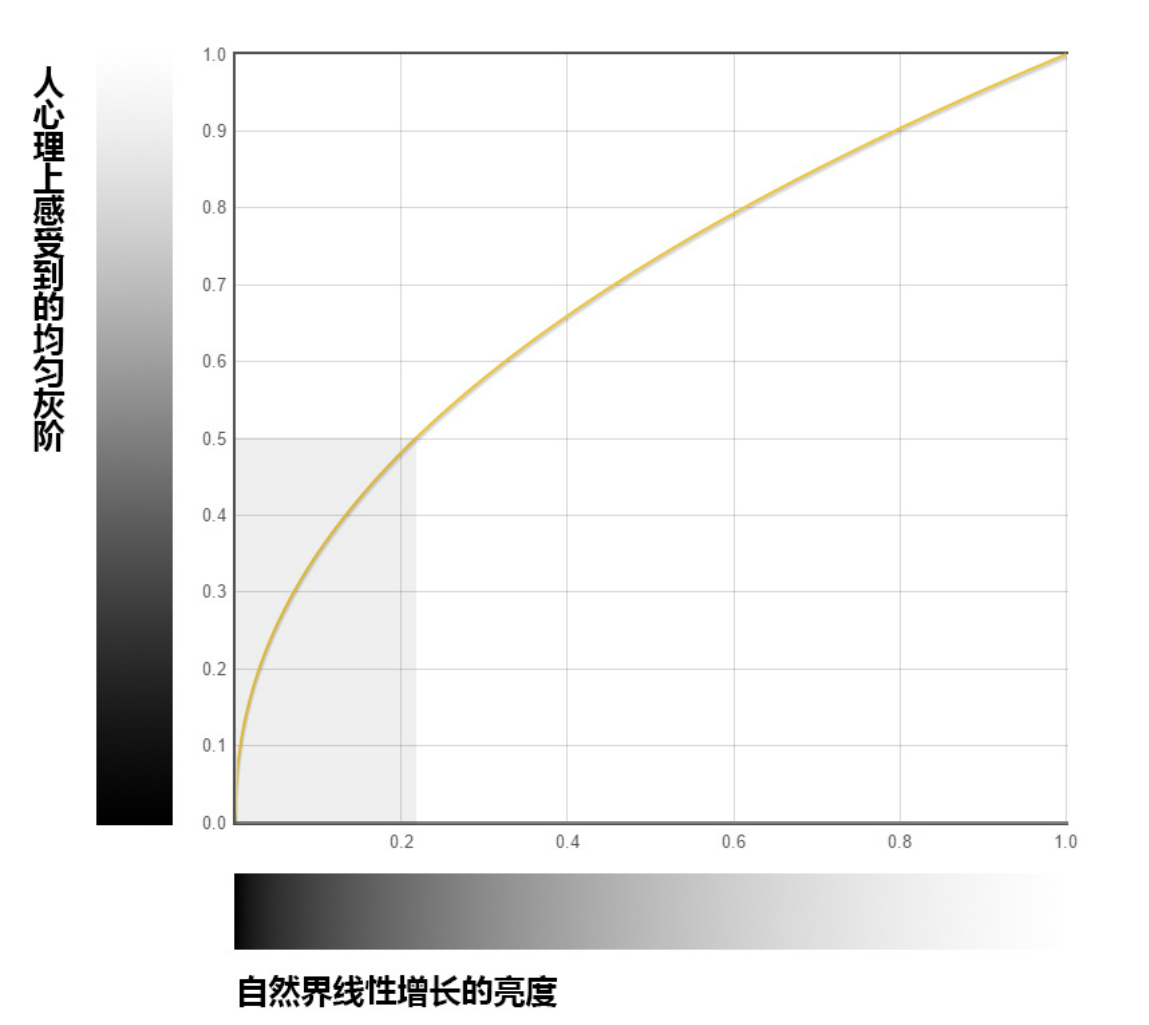
6.2 校正方法
- LUT法(查表法):目前的常用方法
- 方法:提前把每个像素值经gamma矫正后对应的值求出来,然后把这些数据直接存储到一个数中,到矫正的时候根据输入的值就能直接通过数组下标就能找到对应的矫正后的值
- 优点:快,几乎不消耗硬件资源,几乎不用做任何计算的处理
- 缺点:需要大量的内存来存储这么这个表
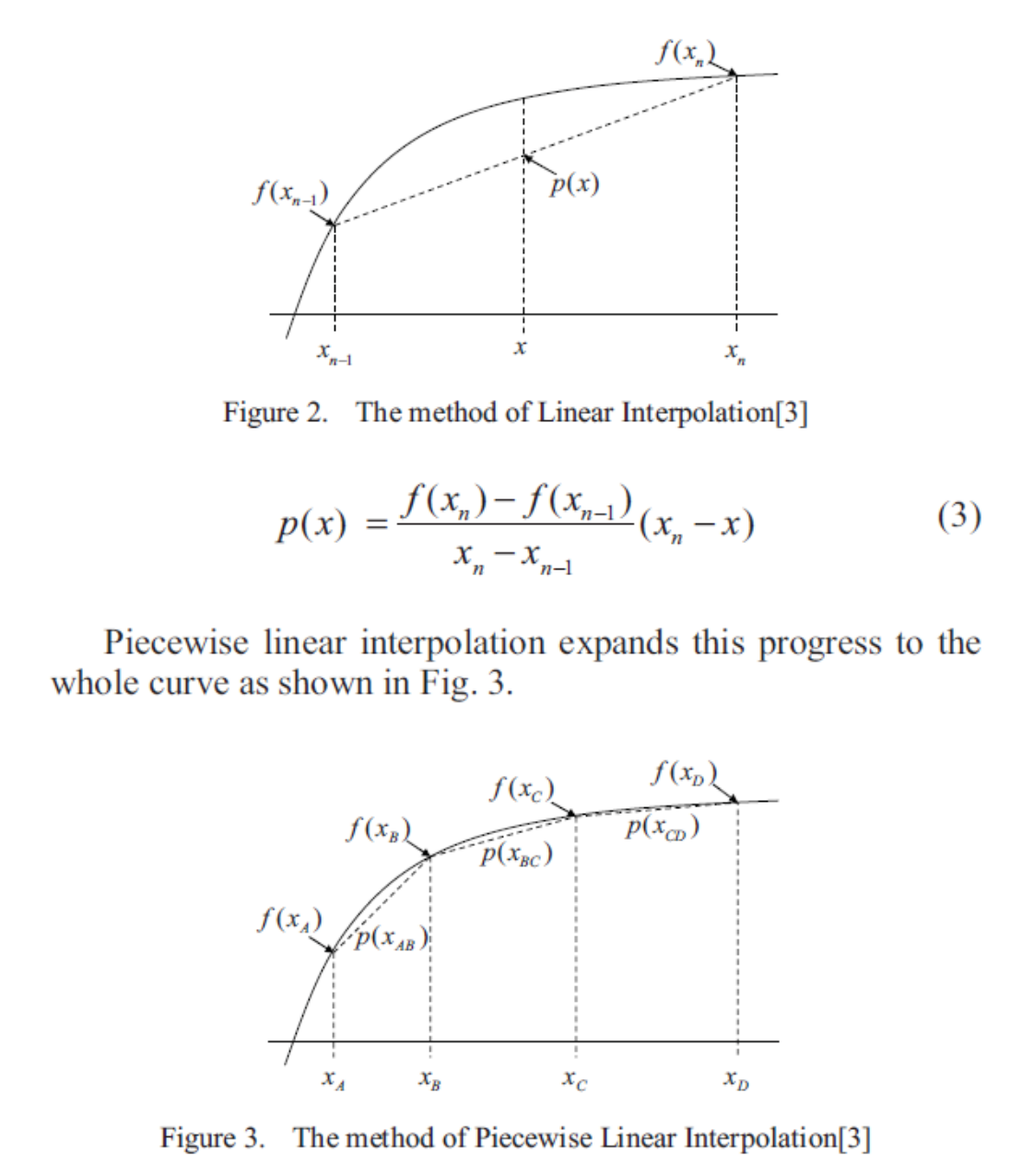
- 线性插值法
- 在gamma曲线上提取一些采样点,然后把采样点的输入输出存储起来,校正时依据真实值和插值得到校正值(具有一定的误差,线性方程不能完全拟合gamma曲线)
- 小结
- 更加认同gamma原因是受人眼特性而来的,因为如果是为了矫正CRT的反伽马特性,那么gamma矫正曲线应该是比较规范的一条曲线,这样才能保证正法结合后恢复成线性。而在实际中对颜色要求不高的情况下,不同的gamma曲线能将画面效果调到最好,调gamma主要还是为了人眼看着舒服合适,说到底还是为了人眼看东西的特性
- 从曲线中也可以看出输出的大小比输入大。一般都是这样,输出会提高位数来保留更多信息量,减少非线性变换带来的信息损失。因为线性的时候肯定是每个输入对应一个输出,但是经过gamma变换后,就会出现对多个输入对应的一个输出的现象,这种输入的这些信息量就会损失,而如果提高输出的位数,用更多的数来表示,就能保证对每个输入都有一个输出与之对应从而保证信息不损失
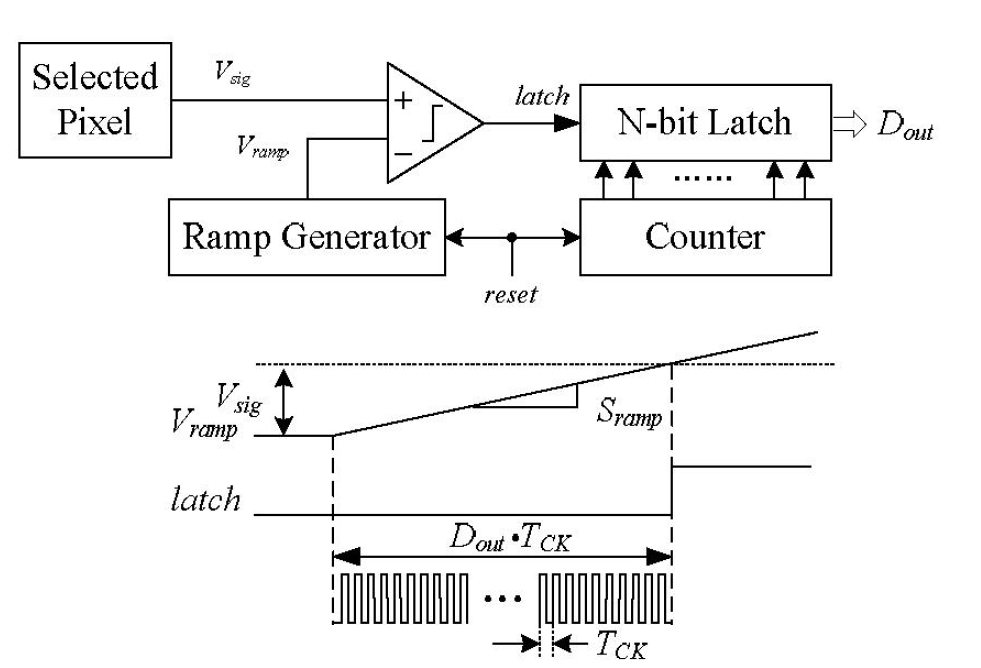
- 模拟gamma法
- 这种方法的大概思路就是AD转换的时候经过一定的处理使其呈现非线性的特性
- 如上图定义Vramp和Vsig,当电压达到Vramp时产生一个斜坡信号,同时始终信号开始工作并计数,然后当电压到达Vsig时latch信号发生一个跳变使得始终信号停止基数,然后这个电压值就会和这种始终信号有一个非线性特性,人后根据这个特性进行gamma矫正
- 该方法不涉及ISP算法
7 HVS(Human Visual System)
- 人眼的分辨率很高,在CV中高分辨率高像素就意味着更高的硬件要求,但目前深度学习网络本身就对硬件要求较高,在此基础上分辨率无疑是负担,因此CV数据集分辨率一般不大
- ISP算法是为了camera更好吻合HVS特性,若为了给CV系统作为输入,就需要适应CVS的特性
- 频率角度看,人眼具有低通特性
- 由于瞳孔具有一定的几何尺寸和一定的光学像差,视觉细胞有一定的大小,故人眼的分辨率不可能是无穷大,HVS对高频不敏感
- 测试镜头解析度ISO12233测试卡:当MTF很高时镜头解析不过来,TV线会模糊,人眼一样当频率很高时人眼无法分辨。基于这一点,在图像压缩技术中有应用,jpg压缩技术会牺牲部分高频信息
- 人眼有边缘增强特性
- 人眼的边缘增强特性:常用灰阶测试卡的一部分,这些块的边缘为突变的,但在这些块放在一起,人眼看起来边缘会有一个加强,呈现一条条的竖线
- 相应曲线表示,真实的亮度变化如黑色实线,但人眼看到的变化如虚线所示,会有增强的效果
- ISP会有一个overshoot和undershoot的调节,为了增强黑色边缘从提高清晰度,但过大会超过人眼特性范围带来负面效果
- 下图左侧为专业文字拍照设备拍摄的文字,拍文字时提高边缘和对比会使文字效果更清晰,故会在字体周围加一圈白边,提高黑色反差提高清晰度;使用手机拍摄文字,手机多是拍人像就不需要重的白边,故图像为平滑过渡

- 人眼对空间分辨率大于色度分辨率
- 人眼对亮度的变化比颜色的变化更敏感,与人眼锥状细胞和杆状细胞的工作方式有关
- 例:在黑暗环境下(不是全黑环境)人眼看周围物体几乎是灰色,但是明亮环境却能看到鲜艳的颜色,但是在按环境下并不影响人眼对事物的判断
- 基于这样一特性有的ISP主控就设置了动态饱和度,就是随着环境亮度的变化,整个画面的饱和度(saturation)也是动态变化从而更好适应人眼特性
- 人眼能够同时分辨的亮度范围,远远小于人眼对亮度的适应范围
- 人眼能分辨的最黑和最亮的数量级很大,但是当一个环境亮度确定的时候,人眼能分辨的最黑最亮的数量级没有前面说的那个数量级大
- 为方便理解真实的分辨率不是这个范围:简单理解就是假如人眼能分辨的亮度范围是0-255,那么当环境亮度为128的时候,人眼能分辨的亮度范围就是50-200,低于50的就都是最黑的了,大于200的就都是最亮的,环境亮度确定了之后范围会变窄
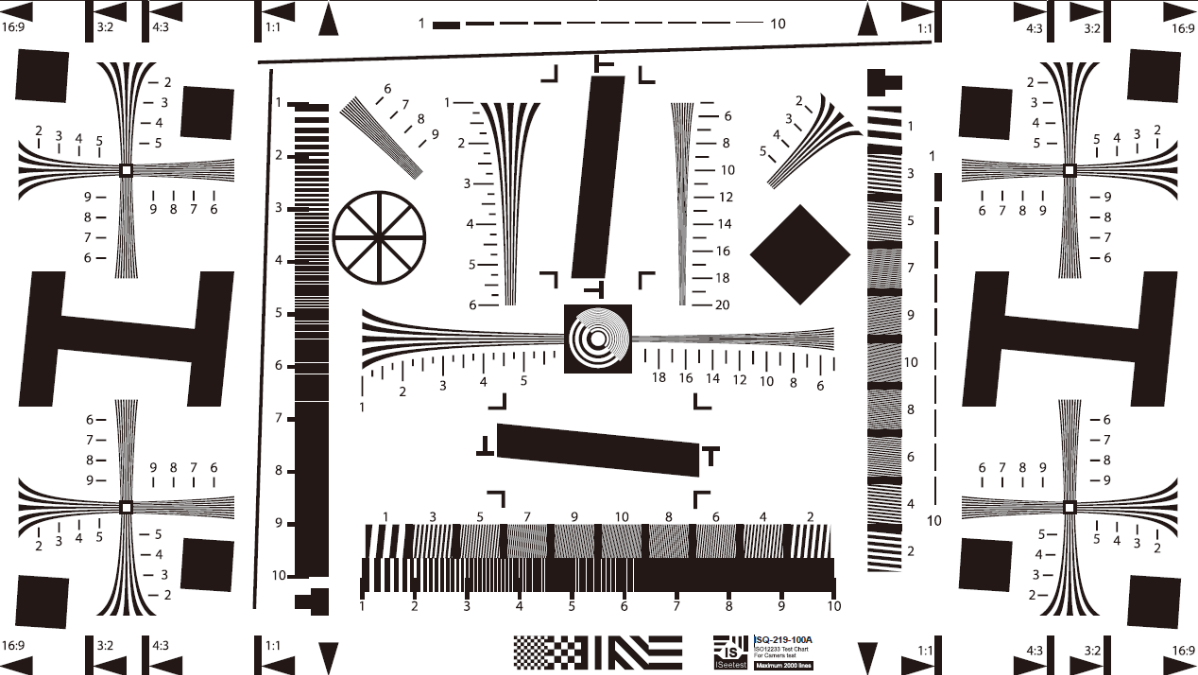
- 人眼对亮度的响应呈现对数特性(gamma特性):对暗区感应能力较强
- 人眼辨别亮度差别的能力,与环境亮度和本身亮度有关
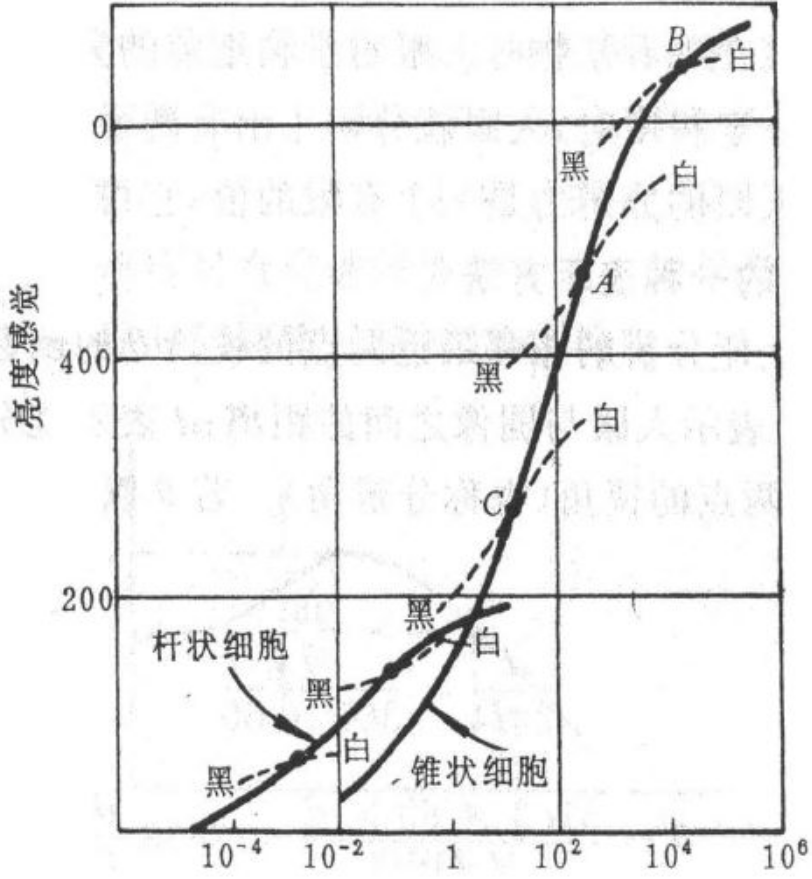
- 左图为人眼对亮度的灵敏度特性(韦伯比):有个实验就是在一个均匀亮度的屏幕上有个圆圈,然后逐渐增加圆圈的亮度值,当圆圈亮度变化很小的时候人眼感受不到变化,当变化达到一定量时人眼就能明显感受到中见的圆圈出现。最后通过实验人们发现这个变化量和背景亮度I有一定关系
- 人眼对这个变化符合右图曲线:当背景亮度小的时候,就需要更大的变化才能使得人眼感受到圆圈的变化,当背景亮度大的时候只需要很小的变化人眼就能感受到,这个就是人眼亮度的灵敏度
- 亮度响应特性和亮度灵敏度的区别
- gamma曲线的特性和亮度灵敏度(韦伯比)的特性为两个不同的概念
- 下图上面灰阶卡是gamma特性的变化,下面在每个灰阶中加了一个变化的灰块,人眼看起来最右侧中间块好像变化更大,但实际上中间灰色块和所处的大的灰阶的亮度差值一样,但由于上面灵敏度的原因故会导致人眼看上去右侧差别更大

8 NR
8.1 产生原因
- 噪声原因
- 图像获取过程中:由于受传感器材料属性、工作环境、电子元器件和电路结构的影响,会引入各种噪声,如电阻引起的热噪声,场效应管的沟道热噪声,光子噪声,暗电流噪声和光响应非均匀性噪声
- 信号传输过程中:由于传输介质和记录设备等的不完善,数字图像在其传输记录过程中往往会受到多种噪声的污染,另外在图像处理的某些环节当输入的噪声并不如预想时也会在结果图像中引入噪声
8.2 校正方法
1 | graph LR |
8.2.1 均值滤波方法
- 均值滤波
- 为线性滤波,主要采用邻域平均法
- 假设图像在一个很小的邻域范围内像素的变化不会太大,那可以在一个很小的邻域范围内求一个平均值来取代当前的像素值从而达到降噪的效果
- 典型的应用就是在图像中取一个3X3的邻域,然后每个像素给权重1,最后求和取平均。然后让这个邻域遍历整个图像
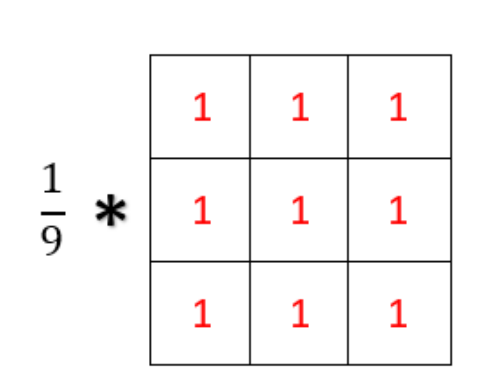
- 高斯滤波
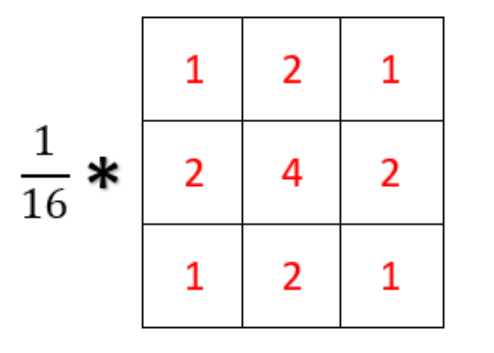
- 加权平均方法, 某个点的值和本身的像素值关系最大,故对应本身点的权重更大
- 高斯滤波的具体思路
- 使用与中心像素的距离,通过高斯函数来计算该点的权重
- 将所有点的权重求出来后对权重进行归一化处理
- 利用加权平均的方式计算滤波后的像素值
- 邻域窗口遍历图像,重复上述操作
- 卷积核如下图所示
-
双边滤波
- 高斯滤波相对于均值滤波性能有所提升,但依然边缘损失严重,为保留边缘信息,故对边缘做进一步处理,在高斯分布上增加一个权重与像素值的差别相联系,此方法为双边滤波算法
- 公式中可以看出双边滤波有两个高斯权重叠加而来:为高斯滤波中使用的距离权重,为像素值的高斯分布权重
- 去噪时需要相似的区域有更大的贡献,不相同的给小的权重,对于边缘而言,两侧像素值差距较大,也会导致离边缘另一侧不同的会分配一个小权重,同侧差异小的会有一个很大的权重,这样不会由于取平均时将边缘两侧的大差异变小导致边缘变弱,达到保留边缘的目的
- 如下图:对白点位置进行滤波时,同侧像素差别较小会有一个大权重,而另一侧差别很大权重也就很小,两者结合后相当于高斯滤波取一侧,然后利用这个核进行滤波操作
- 相当于只对同侧的像素进行高斯滤波,而另一侧保留原来的值,有较好的保边效果
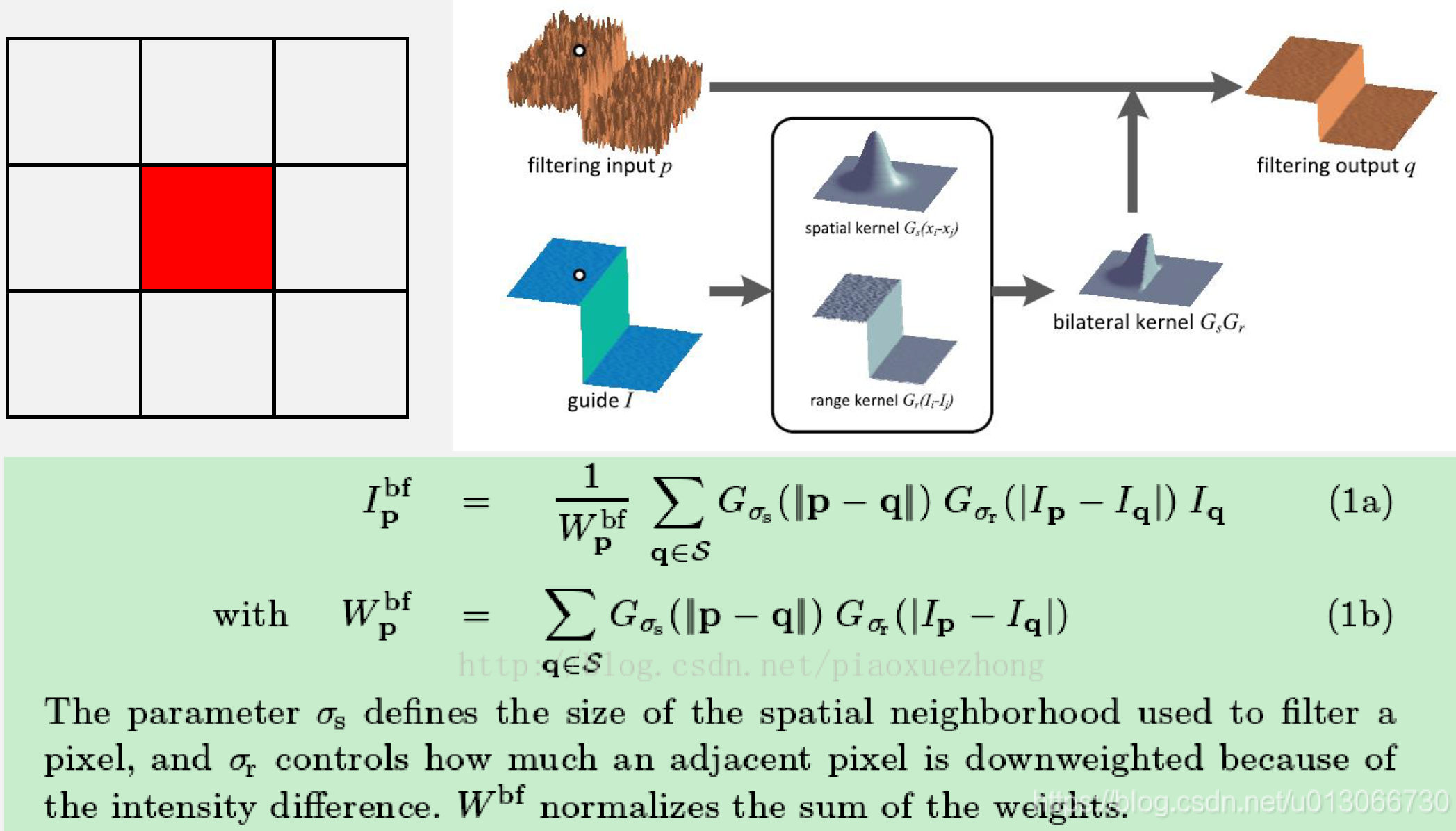
- 相当于只对同侧的像素进行高斯滤波,而另一侧保留原来的值,有较好的保边效果
-
NLM(non-local mean)
- 双边滤波只在图像的局部进行滤波,而有时候需要考虑图像整体的信息进行滤波
- 如文中实例:对于p点而言,q1和q2点所在的邻域和p所在的邻域更相似,那么就给q1和q2较大的权重,而q3邻域和p邻域差别较大,就赋予一个较小的权重。具体权重的赋予方式其实也是高斯的一种方式,只不过e的对数是通过邻域的欧拉距离来计算(相当于求了几邻域中对应位置像素差的平方和作为分配权重的依据)
- 当邻域相似时方差小,权重大,而差异大时方差大,权重小。理论上每一个点进行去噪时会利用整个图像的信息来计算,但是为了降低运算量,一般不会用整个图像的信息来计算,而是在整个图像中先选择一个大的范围,然后用这个范围内的点的信息进行降噪处理
- 算法流程:
- 遍历整幅图像
- 针对每一个点定义一个滑动窗口,降噪的时候利用该窗口中的所有点的信息计算
- 定义一个邻域范围,用来计算像素块的差异
- 遍历滑动窗口中的点,求每个点的邻域范围和当前点的邻域范围的像素差值的平方和,并利用该值计算一个权重
- 遍历完滑动窗口中的所有点后,滑动窗口中的每个点都有一个权重,对权重进行归一化处理
- 得到归一化处理后的权重通过加权平均的方式计算出当前点的新的像素值;
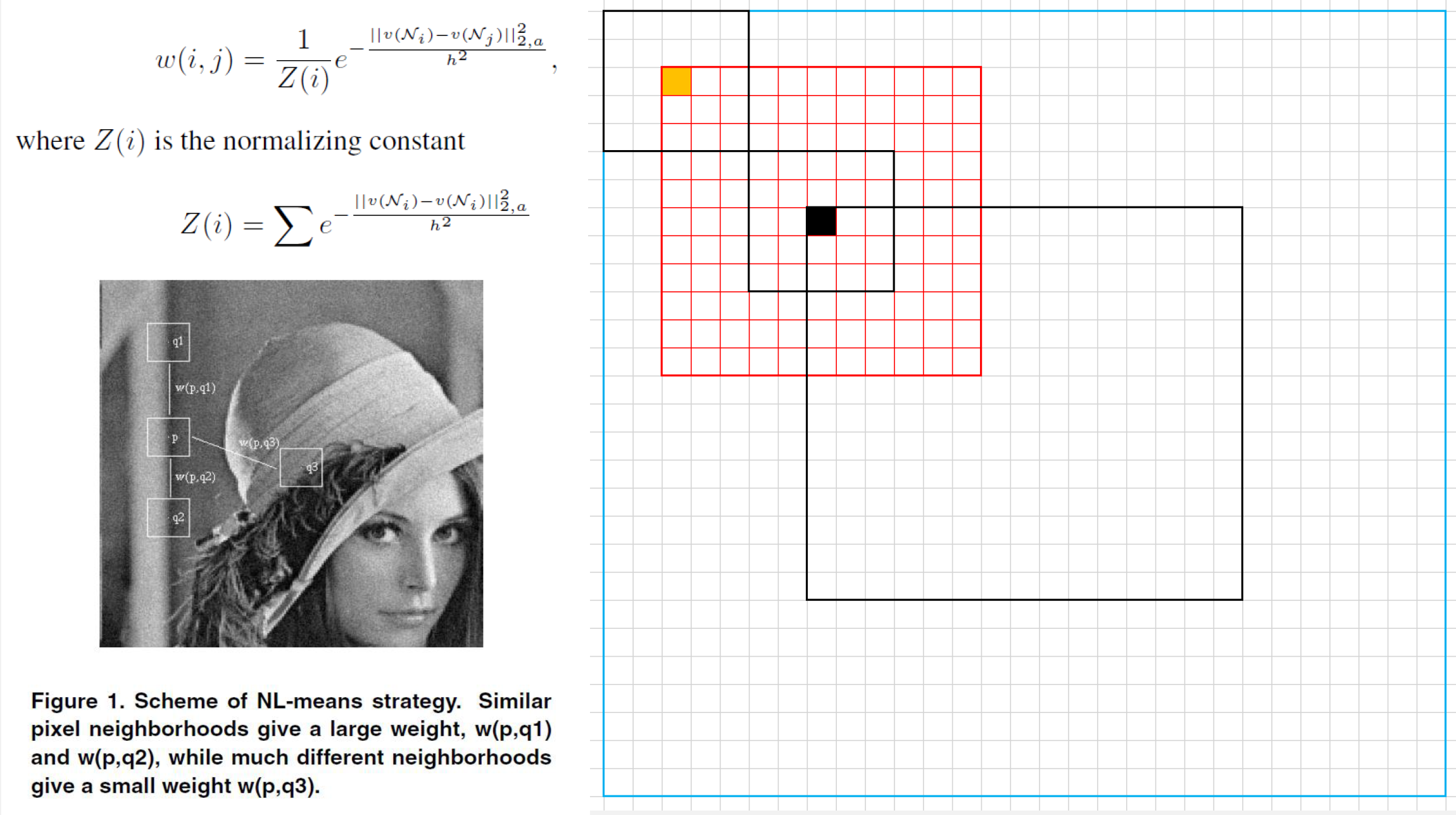
- 简化为图形就是如图的方式
- 最中间的黑色框的范围就是实际图像大小,外面蓝色范围是扩充的图像(为了处理边缘领域不够的问题)
- 计算黑色点的时候,就是定义一个红色框,然后黄色点在黄色框中遍历,每次都计算出两个小黑色框对应位置像素的差值的平方从而求出一个权重,当红色框遍历完了之后对权重进行归一化,然后加权平均就能求出黑色点的值
- 接着黑色点在图像中遍历,同时红色框随着黑点移动,然后黄色点又在红色框中移动,以此循环即可完成整幅图像的去噪操作
8.2.2 中值滤波方法
-
均值滤波对高斯噪声的效果很好,但对椒盐噪声的效果一般
- 均值滤波为线性方法,平均整个窗口内的像素值,不能很好的保护图像细节,去噪的同时破坏了图像的细节部分
-
中值滤波作为一种顺序滤波器,对椒盐噪声的效果很好,且保边能力很强
- 中值滤波为非线性滤波
-
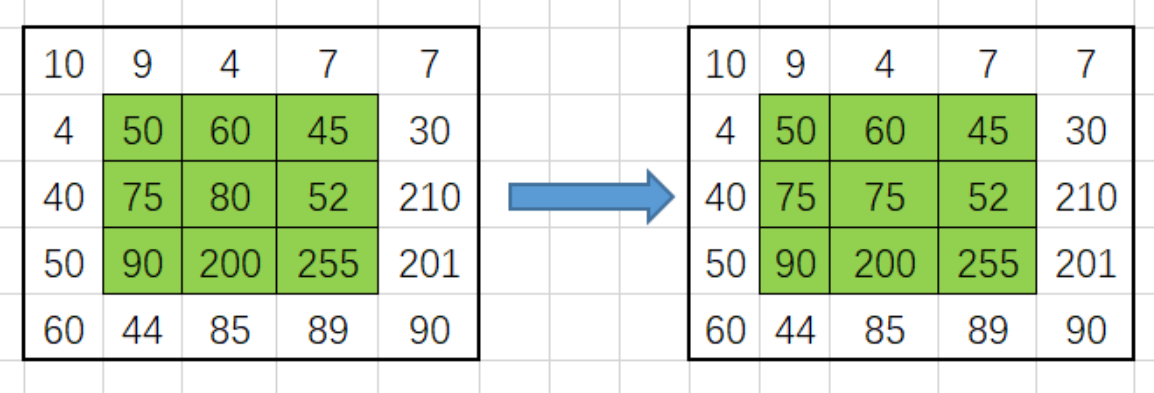
中值滤波:通过求小窗口中的中位值来取代当前位置的方式来滤波
- 如图:绿色窗口就是当前的滤波窗口,在3X3的邻域窗口中进行滤波,中值滤波:
- 对这个邻域中的像素值进行排序:[45, 50, 52, 60, 75, 80, 90, 200, 255]
- 从排序后的数据中找出中位值:75
- 用中位值取代当前位置的像素值得到右侧的滤波后的数据
- 如图:绿色窗口就是当前的滤波窗口,在3X3的邻域窗口中进行滤波,中值滤波:
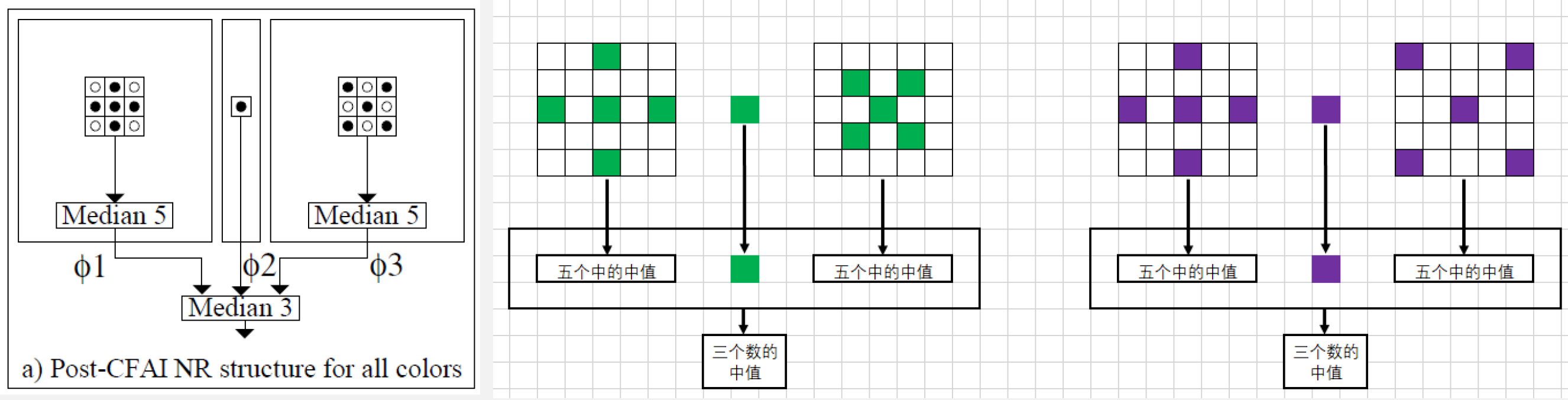
- 多级中值滤波:将多个中值滤波进行多级级联实现更好的滤波效果
- 下图是一种多级级联的方式,先在窗口中定义一个’+'和’X’形的窗口,然后分别求出这两个窗口的中位值,然后结合当前窗口的中心点就有3个候选值,再从这三个值中求出一个中位值作为滤波后的结果
- 可直接应用到RAW图中做BNR,需要修改的就是窗口设置为5X5,在做滤波时需要区分G和RB通道(RAW图中的RGB分布是不均匀的,G占50%,R和B各占25%)
- 左侧就是针对G通道的滤波器,右侧是R和B通道的滤波器,都是定义了一个’+'和’X’形的窗口,不同的只是取的点的位置不同
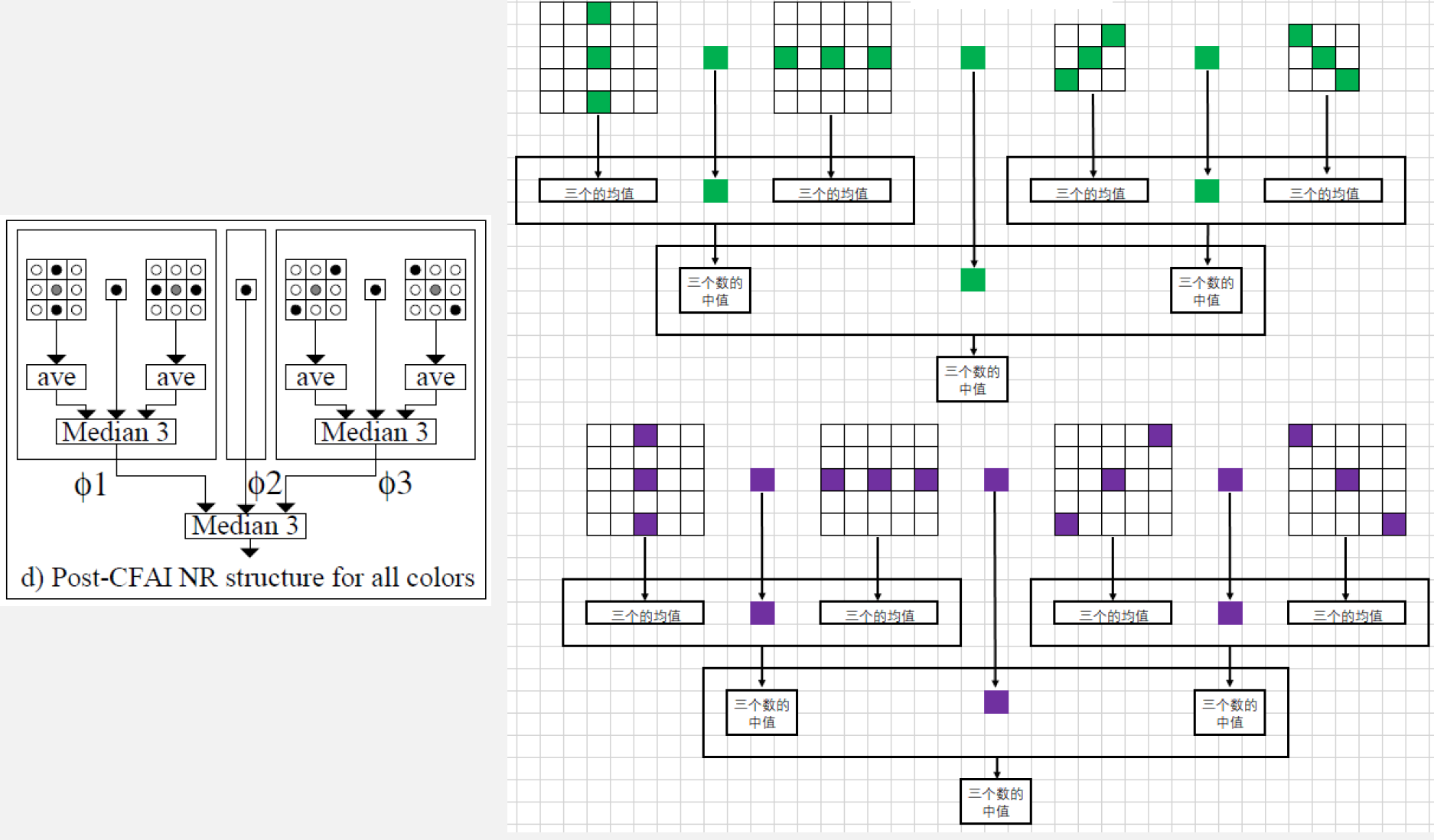
- 多级中值混合滤波:将中值滤波和多级滤波结合起来,相互弥补实现更好的滤波效果
- 算法流程
- 求出竖直方向相邻三个点的均值和水平方向相邻三个点的均值,再结合当前点,用这三个点再求一个中位值;
- 求出45°和135°方向上的均值,然后结合当前点求出一个中位值;
- 两个中位值结合当前点组成新的数组,最后求一个中位值作为当前点的值完成滤波。
- 应用在RAW图上,只需要对滤波器稍作改善即可
- 算法流程
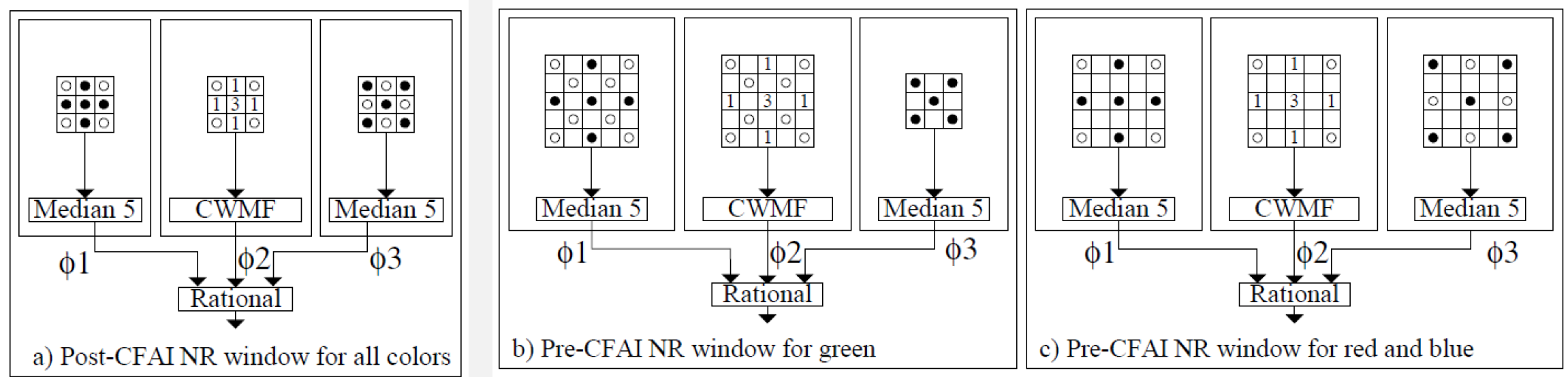
- 多级中值有理混合滤波
- WMF加权中值滤波:在原始数据的基础上给每个点分别赋予一个权重,在加权后的数据中取出中位值作为滤波后的值
- 算法流程
- 求出’+'形和’X’形的窗口的中位值
- 对’+'形窗口再利用CWMF求出一个值,CWMF是WMF的一种特殊情况,就是只对中心点进行加权
- 对以上求出的三个参数用一下公式计算出一个新的值作为滤波后的值
- 算法流程
- 该算法稍加改动就可用于raw格式图像
- WMF加权中值滤波:在原始数据的基础上给每个点分别赋予一个权重,在加权后的数据中取出中位值作为滤波后的值
9 BNR(Bayer Noise Reduce)
9.1 BNR的意义
- RAW图上的噪声模型通常用高斯-泊松模型进行描述,但是在PIPELINE中每经过一个处理模块,噪声都会发相应的变化,在经过一系列的线性和非线性变化后噪声模型会变得更加复杂,很难通过模型去降低噪声
- 下图是前面介绍LSC时标定得到的补偿Gain值,可以发现四周的gain值会比中间的大很多,这样就会导致原本均匀分布的噪声在不同的gain值作用下变得不均匀,这种不均匀和镜头相关,噪声模型就会变得复杂
- 去马赛克算法对噪声模型的影响:不同的去去马赛克算法对噪声模型的改变程度和方式都会有所差异,经过去马赛克后噪声模型无法确定
- 除此之外pipeline中还会经过Gamma,CCM,AWB等一系列线性和非线性的变换,会使得噪声模型更加复杂,后面再去除噪声会变得更加困难
- 所以一种很理想的方式就是直接在RAW上就对噪声进行抑制,让噪声在一个合理的范围内
9.2 方法
9.2.1 PCA简介
- PCA简介
- 对数据找到主要的分布方向,对分散的数据经过旋转变换或其他变换找到其主要分布形式,对其进行投影以最大程度的表示数据的方法
- 若,则实现了降维的操作
- 可以使用SVD奇异值分解 参考矩阵理论知识
- 对数据找到主要的分布方向,对分散的数据经过旋转变换或其他变换找到其主要分布形式,对其进行投影以最大程度的表示数据的方法
- 算法原理
- PCA降噪
- 主要依据:噪声是均匀分布的,而图像的有用信息主要分布在主成的特征上,故经过PCA降维后图像的主要信息得到了保留,而噪声随着减少的维度损失,再经过反PCA变换后SNR就可以得到提升
- 该算法的主要思路
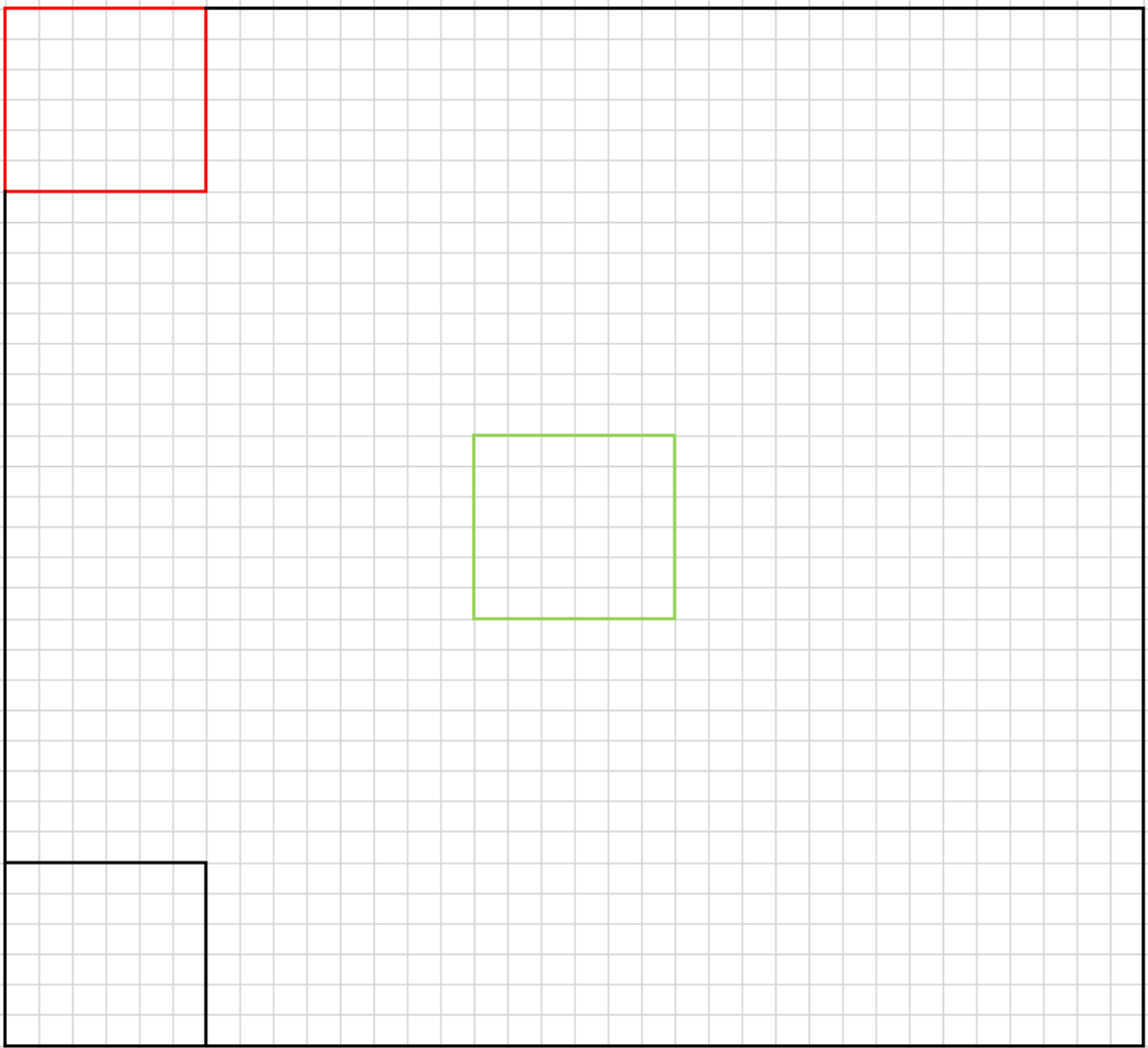
- 首先在整副图中选择一个区域,即图中最大的黑框(training block)
- PCA需要有特征需要选择特征框(variable block),即图中小框,如图将特征框的尺寸定义为6*6
- 假设小框的排列为Gr,R,B,Gb,那么就可以得到一个的一个列向量,那么在training block中有多少个小框,那么就有多少个这样的列向量
- 假设有255个小框,那么就可以组成一个36*255的矩阵,其中36代表有36个特征,255代表有255个数据
- 为了进一步提高算法的效果,在这255个数据中找出相似区域做PCA,因为不相似区域的贡献度太高在后续的去马赛克算法中会使得图像容易出现伪彩
- 找相似的方式,作者使用的方式是通过求每个列向量与中心向量(图中绿色框)的曼哈顿距离来排序,然后选择距离相近的N个数据作为最终的PCA数据
- 经过处理后数据就变为36*N维
- 再对这个二维数据进行主成分分析,找出前m维个特征进行降维(m是对36个特征进行处理)
- 再对降维后的数据进行反PCA变换就可以起到降噪的功效
- 论文中还有一些提升效果的操作
- 在做PCA之前会进行去中心化,保证数据的中心与原点重合
- 如主成分的变换矩阵是通过模型求的没有噪声特性的图像的变换矩阵,在对图像进行PCA变换的时候就可以降低噪声对图像主成分的干扰
- PCA之前会通过小波得到噪声模型的方差,用来分析噪声
- PCA降噪
- 小波降噪
- 小波变换:
- 小波降噪,对图像的按频率进行分层
- 降噪的理论依据
- 图像的能量主要集中在低频子带上,而噪声信号的能量主要分布在各个高频子带上
- 原始图像信息的小波系数绝对值较大,噪声信息小波系数的绝对值较小
- 降噪的理论依据
9.2.2 PSEUDO FOUR-CHANNEL IMAGE DENOISING FOR NOISY CFA RAWDATA
- PSEUDO FOUR-CHANNEL IMAGE DENOISING FOR NOISY CFA RAWDATA
- 需要的内存较大,还没验证在实际PIPELINE上的效果
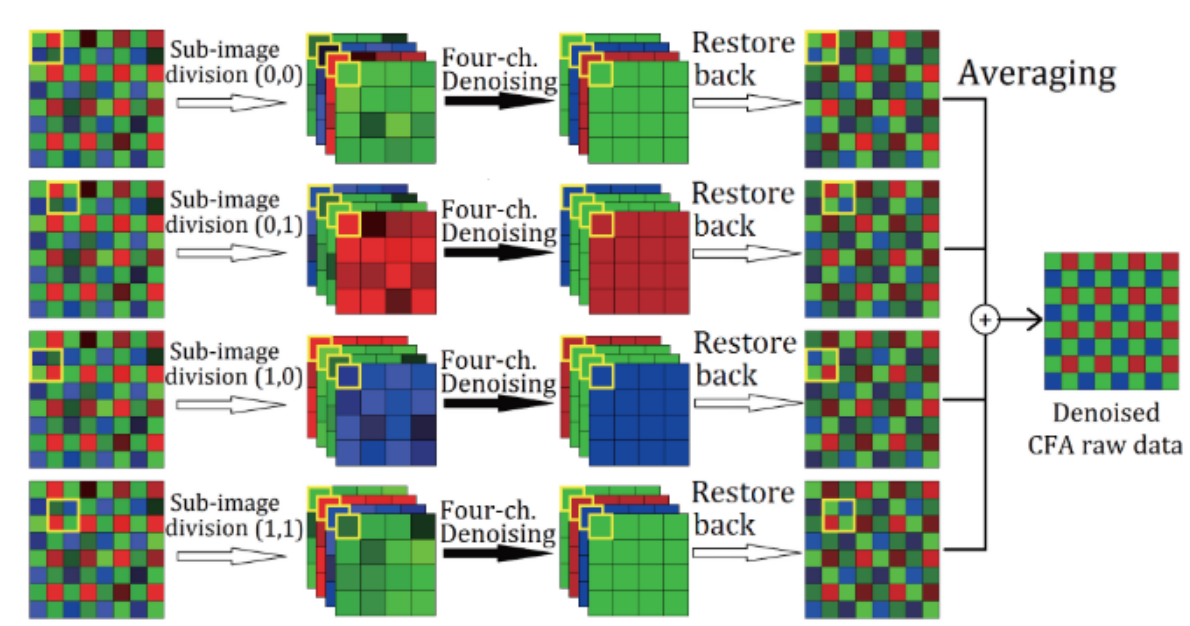
- 主要思路:将一个选择不同的起始点得四种不同的数据,然后对这四种数据进行PCA降噪,然后再次展开成四张RAW图,然后对四张RAW进行平均得到最终的raw图
9.2.3 Noise Reduction for CFA Image Sensors Exploiting HVS Behaviour
- 噪声模型:在sensor端较多的引入噪声
- 光子噪声(光子散粒噪声),暗噪声: 符合泊松分布
- 读噪声,ADC噪声:符合高斯分布
- 之前使用AWGN,加性高斯白噪声作为噪声模型,此时具有泊松分布的噪声,其模型不适用;
- 另外还有1/f噪声和复位噪声,在硬件上可使用CDS技术进行消除
-
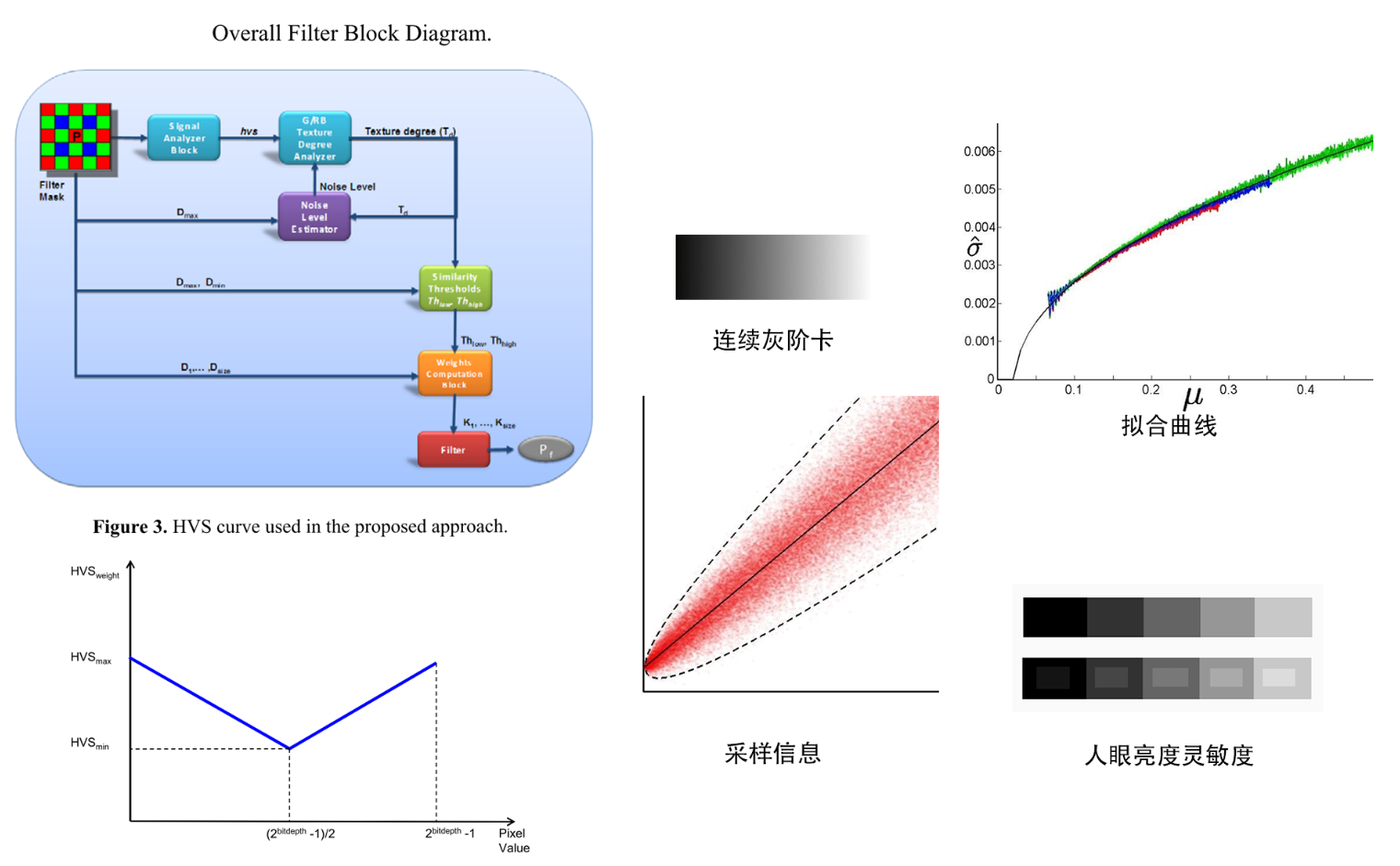
算法原理:结合HVS进行bayer域的降噪
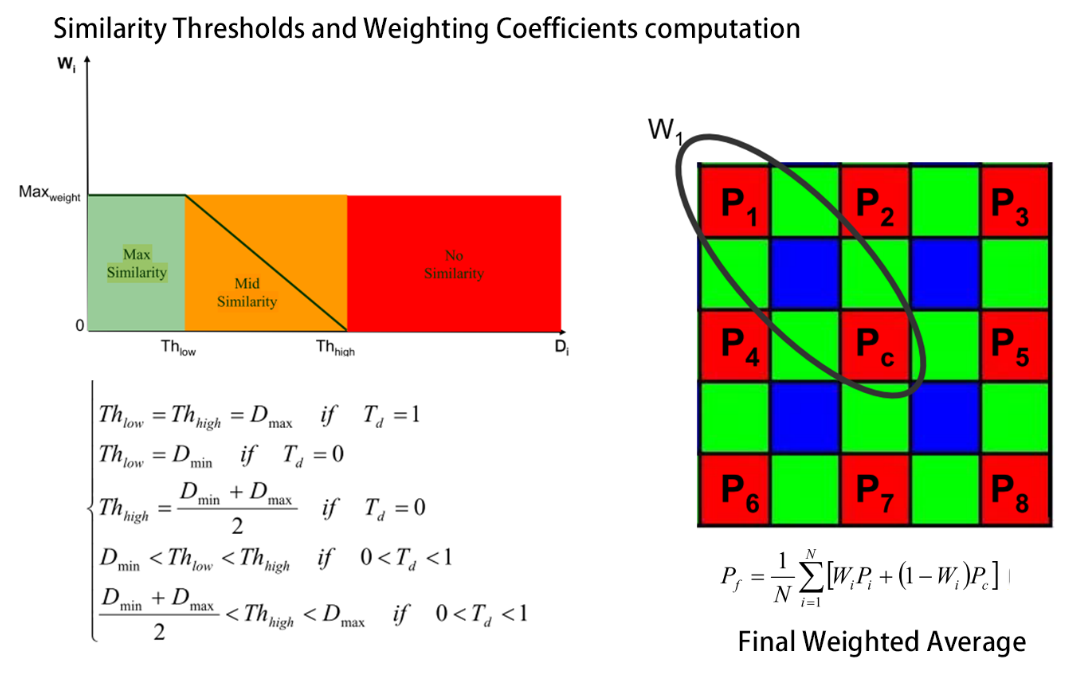
- 主要是通过几个模块进行降噪,通过像素值的差来作为判断依据,包括Signal Analyzer Block,Texture Degree Analyzer, Noise Level Estimator, Similarity Thresholds and Weighting Coefficients computation
-
Signal Analyzer Block --> HVS wieght
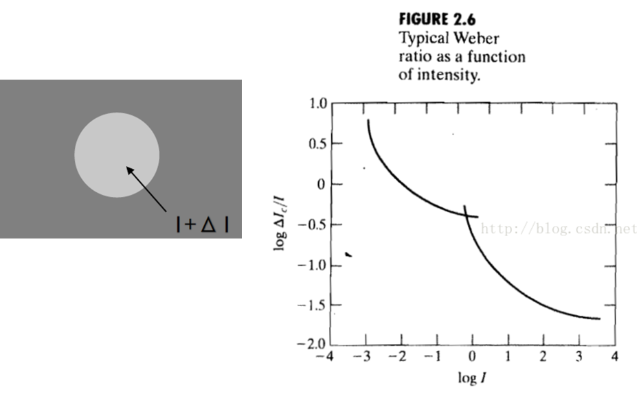
- 噪声在RAW上的分布符合高斯泊松分布,故噪声随着亮度增加会变大(一般说的是越暗噪声越大,但因为人眼看到的噪声大小是通过SNR指标来体现的)
- 结论通常可以通过拍摄以上的连续灰阶卡来证明,拍摄N张以上的灰阶卡,然后从水平方向采样,将所有的采样信息通过绘制可以得到下面的分布
- 中间的黑色线就是均值,红色点就是实际像素值的分布,可以看出随着亮度变大,像素分布的方差越大说明噪声变大
- 根据变化趋势可以拟合曲线可以看出:随着均值变大方差变大,故亮度越大降噪力度需要加大
- 根据人眼亮度灵敏度:越暗的区域人眼对于亮度变化的灵敏度越不敏感,故对于暗部区域可以提高降噪力度
- 由于以上两个特性的,最终将降噪力度和亮度变化的关系定义为Fig3中的曲线:中间亮度值对应的降噪力度为最小,然后两侧呈显现增长
- 噪声在RAW上的分布符合高斯泊松分布,故噪声随着亮度增加会变大(一般说的是越暗噪声越大,但因为人眼看到的噪声大小是通过SNR指标来体现的)
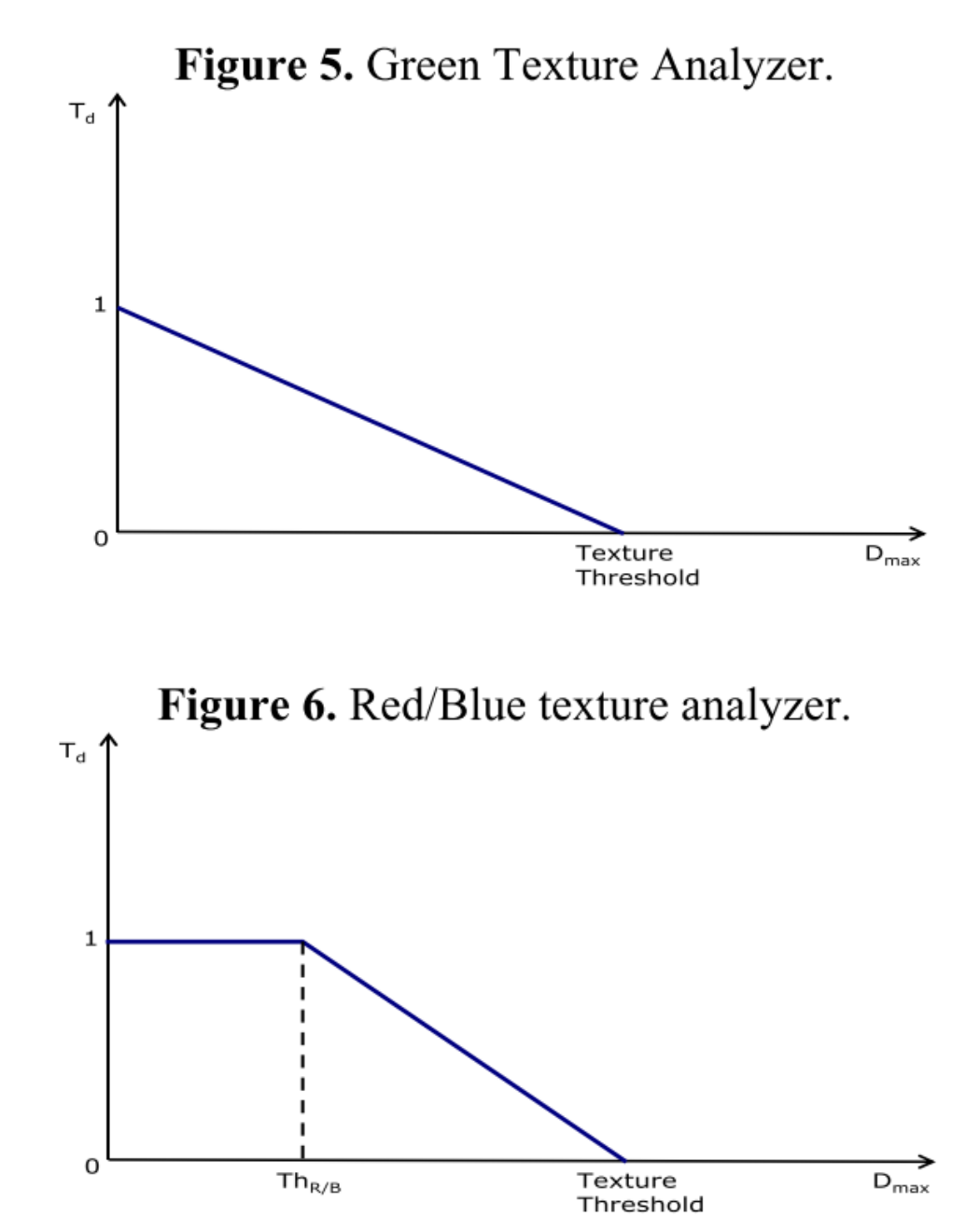
- Texture Degree Analyzer
- 该模块的主要功能:通过上一个模块计算的HVS权重和下一个模块计算的noise level来判断平坦去和纹理区从而实现不同力度的降噪
- 首先通过 公式计算出一个TextureThreshold,用于判断给定的降噪力度
- 因为NL(noise level)是下一个模块计算出来的,所以这里利用上一个像素点计算出来的noise level来预估当前的noise level,然后本次计算的noise level来预估下次,故是一个循环迭代过程
- 最开始的像素没有前一个像素的noise level的时候会设置一个初始值,初始值的是调试时需要根据效果选择的了
- 随后根据邻域内像素点和中心像素值的差异()来判断是否为平坦区, green red blue
- G通道和RB通道分开处理
- 因为人眼对G分量更为敏感,RB通道可以更多的维持在平坦区(即图中Td=1),后面会加大平坦区的降噪力度
- 因为人眼不敏感,故RB通道牺牲更多的细节是在允许范围内的
- Noise Level Estimator:用来评估噪声水平
- 如果被判断为平坦区(Td=1)将noise level设置为Dmax
- 如果被判断为纹理去(Td=0)将noise level保持为上一个像素的noise level;
- 若果介于平坦区和纹理去之间通过插值的方式计算出noise level,
- 式中的代表当前像素点的nosie level,代表上一个像素的noise level,所以对于开始的像素没有上一个同通道的像素可以设置一个初始值
- Similarity Thresholds and Weighting Coefficients computation:主要计算各个点的权重值
- 如图为红色通道的权求解方式:利用周围像素与中心像素的差值来作为权重的最终判定依据
- 首先通过计算的像素值差异求出一个Thlow和THhigh,
- 随后通过比较每个点的像素差异和这两个阈值的差异来给定权重
- 低于最低阈值,说明像素差异很小,在滤波时的贡献应该大,需要给一个大的权重
- 相反差异太大就不应该对滤波提供大的贡献,所以需要将权重设置小
- 所以通过如上的一个分段线性的方式来给每个像素点分配权重。
- Final Weighted Average
- 最后通过上述公式完成滤波和归一化即可得到最终降噪后的像素值
10 Demosaicking
10.1 CMOS成像基础

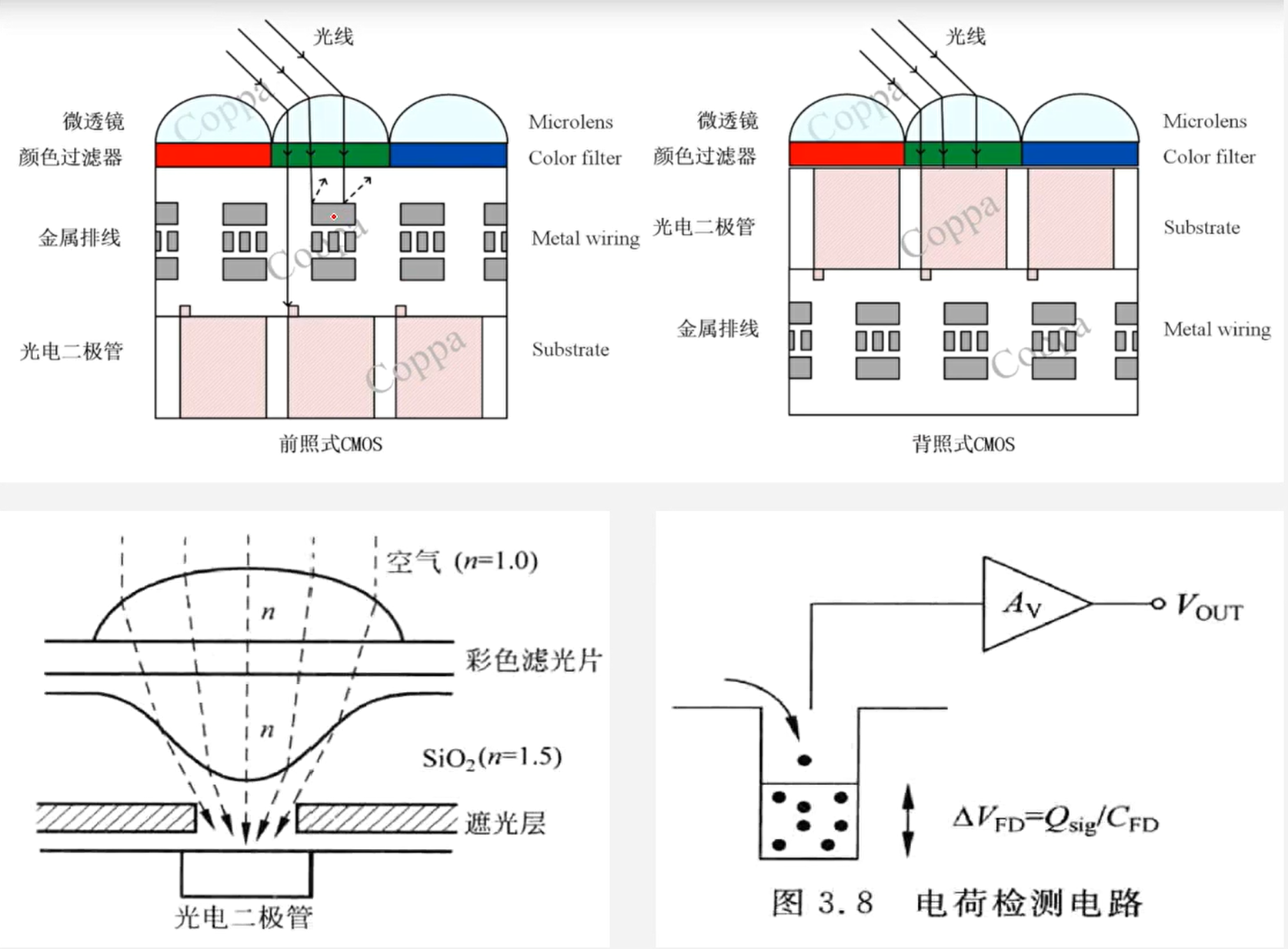
- CMOS结构分为前照式CMOS和背照式CMOS:工艺不同,金属排线的位置不同
- 前照式CMOS,会挡住一部分光线,导致感光能力下降
- 背照式CMOS,工艺更加复杂
- 相机系统用的感光器件只是一个光电转换器件,感光器件只对亮度分量敏感,无法感知颜色,故需要通过滤光片将光线分解成RGB三个分量用感光器件接受
- 3CCD:最直接的方式就是用三个滤光片分别过滤出RGB三个通道的分量,然后用三个感光器件去分别接受三个通道的强度,然后再将这三个通道的值叠加到一起就能复现出正常的颜色(工艺复杂且成本较高)
- 柯达公司发明廉价且高效的方案只需要在一个CCD阵列上制造三种不同的滤光膜,构成一个滤光膜阵列(CFA)
- ==在感光器件上面通过交替的滤光透镜过滤出三中颜色分量形成RGB三色交替的图像,后期通过算法通过周边的颜色恢复出确实的颜色,最终形成RGB的颜色
- 这种后期的处理方式就是本文讨论的重点,一般称作去马赛克算法(demosaicking)
- 去马赛克也称为CFA重构,无限还原回RGB真彩空间
10.2 算法精讲
10.2.1 简单的线性插值

- 如图是Bayer格式的raw图,RGB三种颜色交替覆盖,且绿色分量是RB分量的两倍
- 由于这种特殊的分布方式,所以可以通过简单的线性插值插值出同一通道缺失的分量,
- 简单的线性插值的效果一般,存在画面整体清晰度变差,高频存在伪彩,边缘存在伪像
10.2.2 色差法和色比法
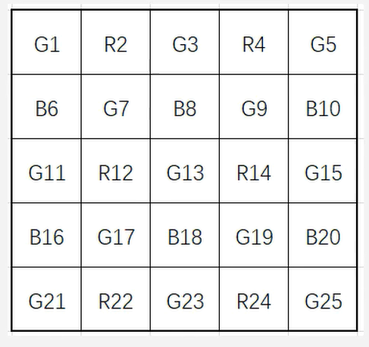
- 色比法和色差法基于两个假设实现插值
- 色比法假设:在一个邻域范围内不同颜色通道的值的比值是固定的,简单来说就说相邻像素的R/G的值和B/G的值是一样的(设计算法时就可利用这一点)
- 一般情况下都会先插值出G的缺失值,然后通过与G的比值恒定插值出其他的缺失值
- 如上展示的RAW图,可以通过G9,G13, G15,G19做简单的线性插值恢复G14,然后通过R14/G14 = R13/G13的假设恢复出R13;同理可以恢复出其他缺失的颜色
- 色差法和色比法类似,色差法假设在一个邻域内不同通道的色差值是恒定的
- 只是将色比法的比值转换为差值即可
- 色比法假设:在一个邻域范围内不同颜色通道的值的比值是固定的,简单来说就说相邻像素的R/G的值和B/G的值是一样的(设计算法时就可利用这一点)
- 效果一般,存在画面整体清晰度变差,高频存在伪彩,边缘存在伪像
10.2.3 基于方向加权的方法
- 由于上述简单的插值算法存在诸多缺陷,其主要原因就是没有针对边缘做处理
- 更好的算法就对边缘做了识别,针对边缘做特殊的处理,然后同时利用色差或色比的方法融合到一起得到更好的效果
- 由于绿色在RAW图中占50%,对图像更重要,故一般先将G通道先差值出来
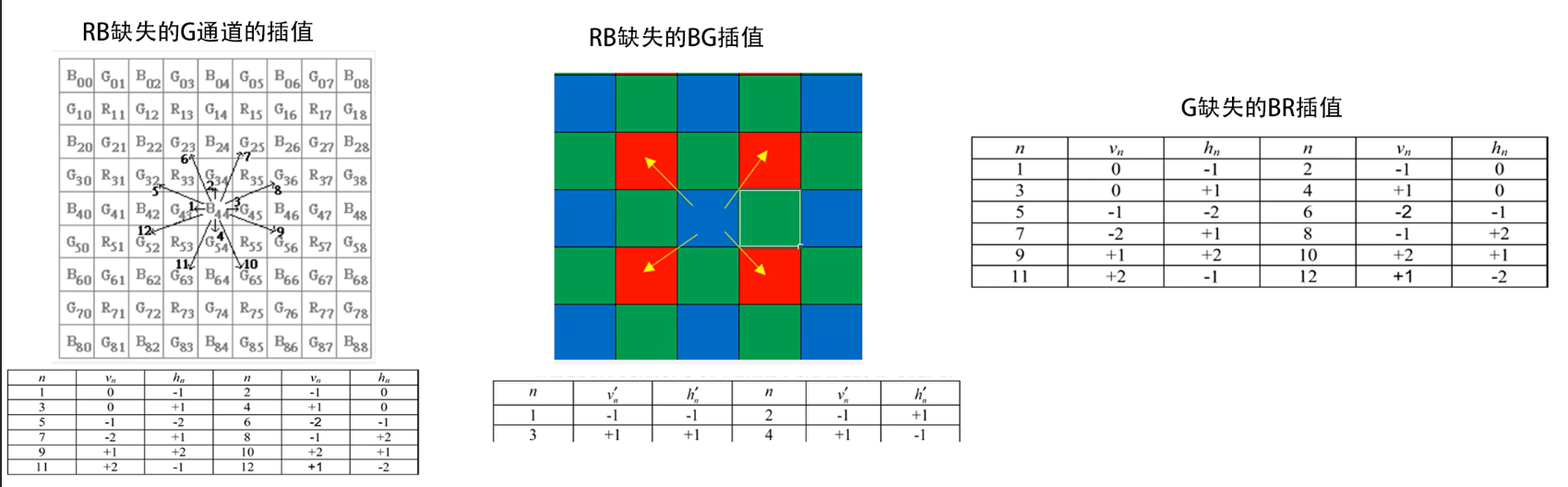
- RB缺失的G通道的插值(以B上G的插值为例)
- 对于点,使用表中的n方向对应的代入计算
- 依次计算12个方向的类梯度值,得到计算结果
- 为权重,可在1,2,3,4方向上取,5,6,7,8,9,10,11,12方向上
- 计算权重
-
- 为色差,使用左右的B或上下的B的均值计算
- RB缺失的BG插值
- 对于点,使用表中的n方向对应的代入计算
- 计算权重
-
- G缺失的BR插值
- ,
10.2.4 基于边缘检测的方法
- 计算水平和竖直梯度: 水平梯度,同理计算竖直梯度
- 计算缺失的G
- 计算权重:,
-
- 计算缺失的RB
- G缺失的RB
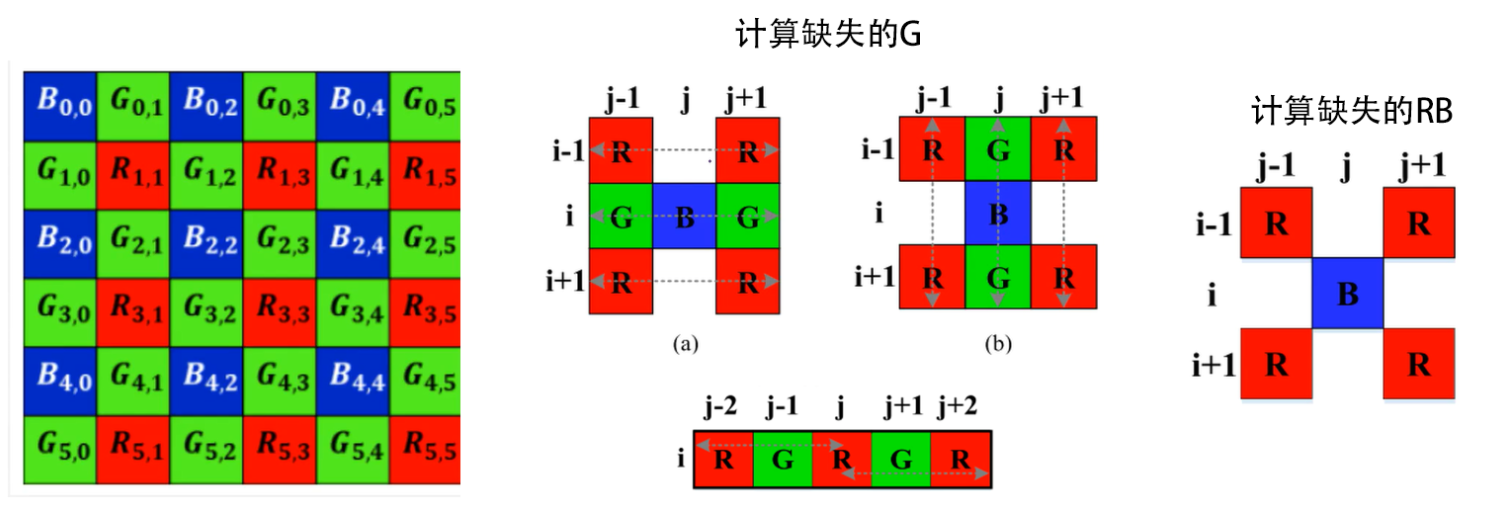
10.2.5 基于学习的方法
- 马赛克与降噪结合的方法
- 该算法默认的raw输入为3通道,这个图可以通过1通道的raw生成,就是只保留该点原本的颜色值,其他两个通道为0即可
- 大体模型就是输入的RAW先通过降采样生成4通道的长宽均缩小一半的数据
- 降采样有两种方式,一种是直接将图像拆分为R,B,Gr,和Gb四个通道,然后再进网络
- 另一种方式就是如图中的方式,通过一个2X2,步长为2的卷积核进行一个卷积运算输出一个4通道
- 在经过降采样后再经过14次3X3的卷积并用ReLu作为激活函数,同时整个过程维持64通道
- 在15层通过3X3卷积输出一个12通道的数据,接着通过一个上采样卷积生成一个3通道的数据
- 然后将这个3通道的数据和原始的raw数据做一个叠加生成一个6通道的数据
- 紧接着再经过一个3X3卷积生成64通道数据,最后再通过一个3X3的卷积生成最终的图像
- 大体模型就是输入的RAW先通过降采样生成4通道的长宽均缩小一半的数据
- 基于这个模型通过大量的数据来学习最终生成模型
- 该算法默认的raw输入为3通道,这个图可以通过1通道的raw生成,就是只保留该点原本的颜色值,其他两个通道为0即可
- 其他方法:Bayesian估计方法, 残差网络模型
11 CCM(color correction matrix)
- 颜色学基础:人眼的视锥细胞和视杆细胞、颜色匹配实验、CIE_RGB出现负数的原因、CIE_XYZ
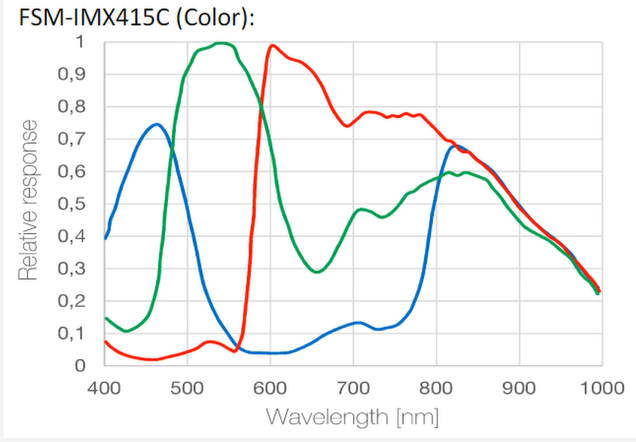
- sensor和人眼对颜色的感知存在差别,且不同sensor之间的颜色感知也存在差别,因此需要将设备的颜色感知统一标准
- 理解为人眼对物体感受的颜色是目标,需要将sensor感光数据经过某种变换达到目标
- 假设人眼能感受到的颜色种类有m种,那自然界的颜色就可以表示为一个3Xm的矩阵,同理sensor对自然界的感光也可以得到一个3Xm的矩阵
- 需要做的就是将右侧sensor感光的数据转换到左侧人眼感光的数据上来

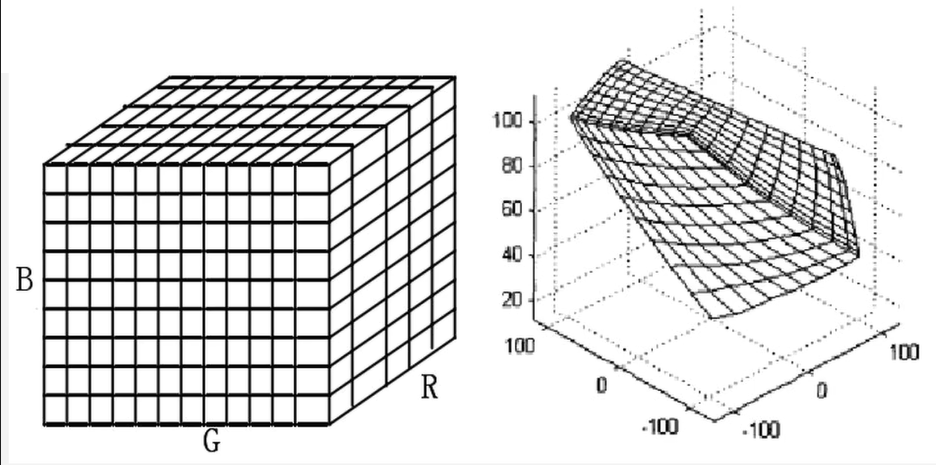
- 3D-LUT法
- 3D查表法,若值在表中,则直接给出,否则插值得到
- 多项式拟合
- 此处的3X3的矩阵是需要的颜色校正矩阵,即CCM
- 在进行CCM之前已经进行AWB,使得,故需要限制条件,实际过程中使用最优化的方法,拉格朗日乘数法进行求解,通常不会通过简单的矩阵求解,而是通过带限制条件的优化方程的方式来求解,目的是保证白平衡不被破坏
- CCM同时也有3X4,4X3矩阵,为加上一个offset参数
- 实际使用中不多:
- 根多项式方法:
- 多项式:
- 常规做法:
- 使用color char(为24色标准色卡)
- 通常在LAB颜色空间,在LAB颜色空间具有参数,可以更精确的表示人眼的距离关系
- CIE_RGB到CIE_XYZ解决了负数的问题,而CIE_XYZ中距离不能表示颜色的差异,因此引入了CIE_LAB颜色空间,L表示亮度,AB表示色相,根据A或B的值可以表示颜色的差异,
- 在2000年提出标准,该标准更符合人眼的特性
- 神经网络
- 神经网络的方式,因为其实输入就是一个矩阵,输出也是一个矩阵,那么中间通过网络连接,然后通过数据训练也能得到一个转换的网络参数
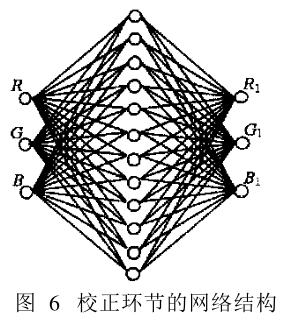
- 总结概念
- sensor RGB: sensor的感光相关
- CIE_RGB
- RAW图 --> 去马赛克 --> rgb图(为sensor RGB, 为线性RGB) --CCM_1–> XYZ --CCM_2–> LAB --CCM_3–> target LAB --CCM_4> target XYZ --CCM_5–> sRGB(线性sRGB)
- 其中CCM_4和CCM_5的转换矩阵已知
- 线性sRGB --gamma校正–> sRGB非线性
- 调试时,与gamma相关,gamma常规值为2.2或0.45,在调试时会预先设置一条Gamma曲线,经反变换之后得到sRGB,随后根据sensor RGB就可以得到CCM矩阵
- CCM调试之前先调Gamma,在pipline中Gamma位于CCM之后
12 CSC
12.1 CSC简介
- CSC-coloer space convert,也称CSM(color space matrix)
- 通过一些线性变化,将原本图像的颜色空间转换到其他的颜色空间(常见的有RGB2YUV,RGB2SV等),下图是MATLAB文档中对CSC的定义
- 但是通常在ISP的Pipeline中用到的CSC转换只有RGB2YUV,部分主控在CCM之后会有RGB2HSV的转换,以便进一步通过色度和饱和度两个层面对颜色做进一步的处理
- ISP要实现RGB2YUV转换需要转换公式,各个转换公式的的标准不同,通常采用BT的标准,也就是国际电信联盟指定的标准
- 如下图分别罗列了BT601,BT709和BT2020三个标准,具体在选用的时候根据需要选择一个就行了

12.2 YUV的作用
1 | graph LR |
- 为什么pipeline中需要这么一个转换将RGB转为YUV:
- YUV是早期欧洲定义的一种信号格式,主要是为了解决黑白电视和彩色电视过渡时期的信号兼容问题,黑白电视只需要亮度值,不需要彩色信号,而彩色电视既需要亮度信号也需要色彩信号,所以如果直接使用RGB就会带来兼容问题,而采用YUV信号,黑白电视不处理彩色信号即可;
- 可以将Y和UV分开处理,即将亮度信号和色度信号分开处理,更符合HVS,HVS中人眼对亮度信号更明高,对色度信号相对不明感,在去噪等一些处理时就可以针对不同层面的信号做不同强度的处理,从而最大程度的保护图像效果
- 为后续的数据压缩做准备,因为通常现在用的多的MJPG和网络传输用的H264和H265等信号都是基于YUV信号的基础上做进一步的数据压缩得来的
12.3 YUV简介
- YUV中Y表示亮度信号,UV表示色度信号也就是色差信息
- 通常查资料会出现YCrCb信号:YCrCb是数字信号时代定义的一种色差信号,是通过YUV加上一定程度的offset得到的,使得色差数据都大于0
- ==大多数情况下已不对二者进行区分,现在提到的YUV其实都是指的YCrCb格式,只是习惯原因通常还是会直接说是YUV=
- YUV格式有很多种类,如下图是微软WindowsAPI文档中对YUV的一些宏定义
- 图中的数据格式是YUV格式,而它们各自的区别主要就是采样比和信号的排列循序

- 如图是三种最常见的采样比例,黑色实心点为Y分量,空心的圆圈为UV分量
- YUV444:完全采样,即每一个Y信号对应的UV信号都采样,没有损失任何信号
- YUV422:两个Y信号公用一个UV分量,及4个有分量对应2个U和2个V分量,色度信号损失一部分从而减小数据量
- YUV420:四个Y分量公用一个UV分量,在422的基础上进一步降低数据量
- 其实从定义看YUV420可能叫411更好理解,但是为啥又叫420呢?
- 因为还有一种基本没见过(也可能是作者见识短)的格式叫YUV411,他和420一样也是4个Y对应一个UV,不同的是411只在水平方向对UV降采样
12.3.1 信号排列分类
- 从微软文档中可以看到有一个YUY2的格式,其实这种格式又叫YUYV格式是一种422的采样格式,然后还有一种YVYU的格式也是422采样,两者又有什么不同呢
- 其实就是信号排列不同,比如在内存中YUYV格式存储为
Y1U1Y2V1Y3U2Y4V2而YVYU则存储为Y1V1Y2U1Y3V2Y3U2这种方式都是Y和UV交替存储,还有一种常见的存储方式就是先将所有的Y分量存储好,然后再去存储UV分量,当时后续的UV分量的排列又会有不同的变化
- 其实就是信号排列不同,比如在内存中YUYV格式存储为
13 3A算法——AE(auto exposure)
13.1 预实验公式+LUT法
- 算法说明
- 根据以下公式,∑为ISP芯片内的统计值,可以通过读取寄存器地址直接获取,L为当前物体的亮度,G为gain值,S为曝光时间
- 变换以下公式:,L是当前物体的亮度,当环境不发生变化时
L是一个定值 - 初始化时先给定一组GS,K为常数,然后通过寄存器读出∑的值就可以计算出L,然后通过前期试验找出不同L对应的最佳GS参数组合,然后通过LUT找到这种参数组合,重新赋值给GS即可完成曝光
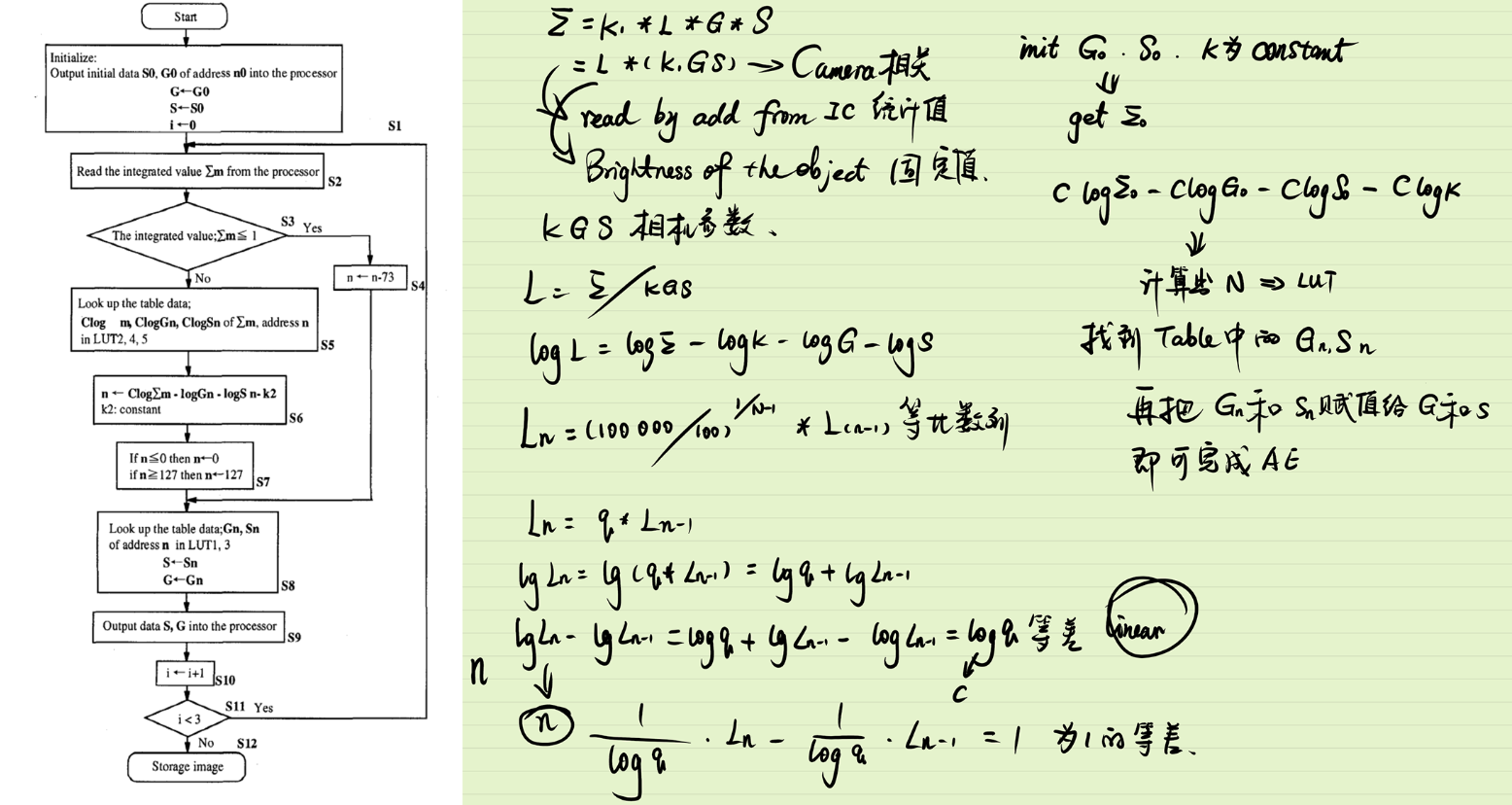
- 同时该论文中设定L的取值范围是100Lx—100000Lx之间,这么大的范围如果一个一个测试费时且内存过大,故将这个范围分成一个等比数列
- $L n=(100000 / 100)^{I /(N-1)} \times L_{(n-1)} $,N为设计的地址的个数,根据这个数目将这个范围分成一个等比数列
- 然后为了进一步简化运算,将公式(1)取对数,因为Ln是等比数列,那么 就是等差数列,那么 就是一个等差为1的等差数列,就正好设计为LUT的地址,这样用一个数组就可以解决(q为等比数列的公比)
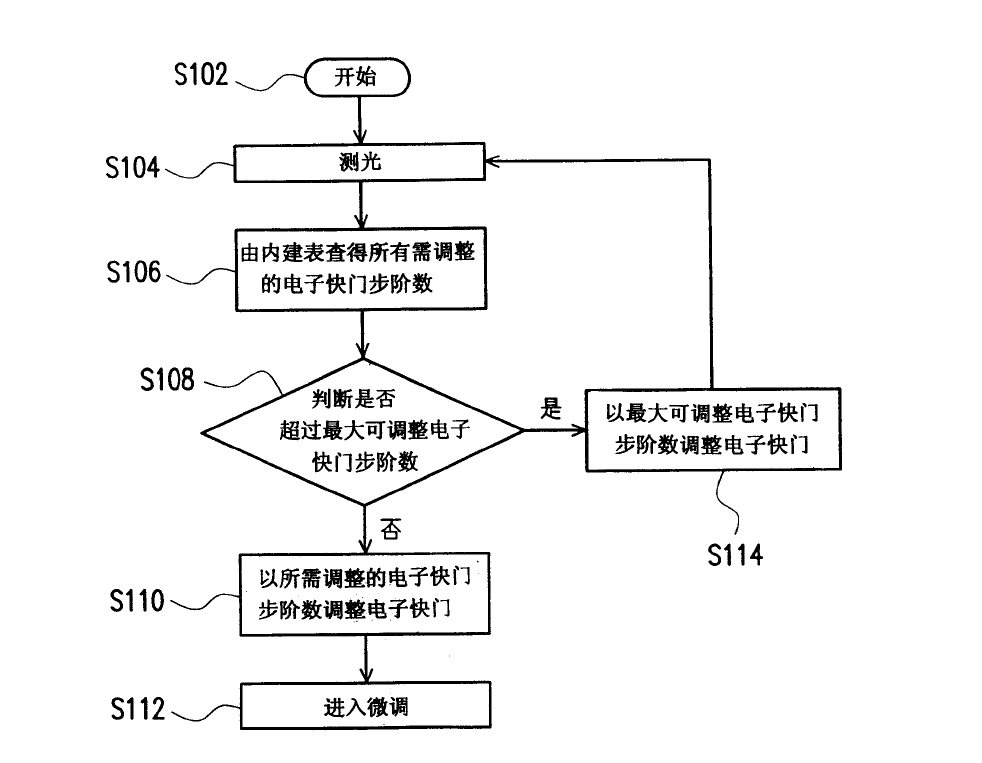
13.2 公式+LUT+微调法
- 流程:通过初始化参数获取图像,用测光得到图像的平均亮度,根据LUT找到对应调整步伐,判断该步伐是否超过最大步伐,如果超过则使用最大步伐调整,调整后平均亮度理论上应该接近目标亮度,所以调整后就可以通过微调进一步优化
- 该算法的重点:如何建立内建表,
- 公式按照理解也是通过大量实验得到的,下面对公式做解释:
- : 所需要调整的步阶数
- : 调整曝光时间的最小单位,这个值对于同一设备是常亮
- : 所需要的的目标亮度
- : 画面的平均亮度
- 具体做法:八位数据两说亮度值就是0-255,0不能最分母,且一般也不会拍摄亮度为0的画面,所以内建表就设计为1-255,然后根据设置的target的值计算出每一个平均亮度对应的,当相机计算出平均亮度就立马能找到对应的步伐进行调整,从而完成曝光任务
- 公式按照理解也是通过大量实验得到的,下面对公式做解释:
- 但是该方法的弊端就在于目标亮度不同就会得建立不同的内建表,如果需要更新目标亮度就得更新整张表,如果建立多张表的话对于内存大小又有要求
13.3 公式快速带入法
- 该方法最重要的就是求出公式,一般求公式的方式也是通过实验获取一些输入,然后通过机器学或者其他方式拟合出一条曲线,最后根据曲线方程计算出相应的参数
- 该论文中主要通过 建立
- Y: 表示成像器获取的图像亮度
- M:表示成像器所能获取的最高图像亮度值
- K: 表示曝光时间为1个单位时间,即最小步长是成像器获取的图像亮度
- G: 表示电子增益
- x: 表示曝光时间
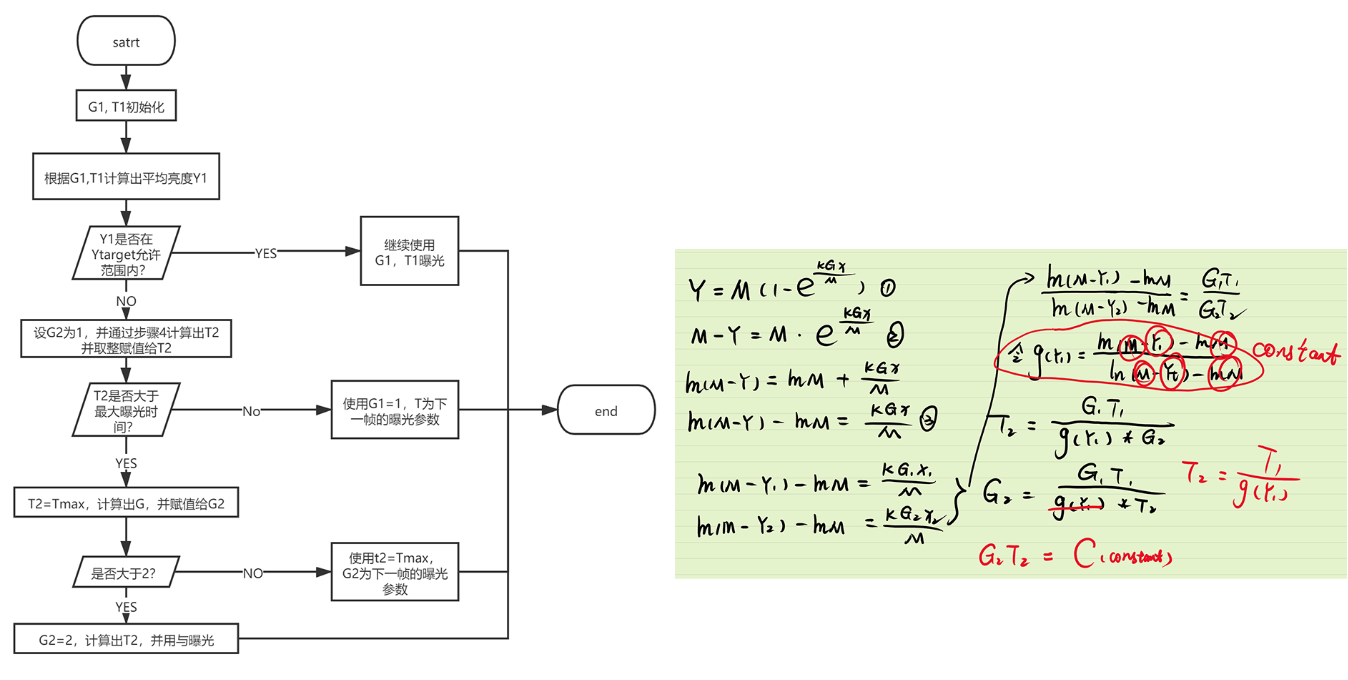
- 算法的具体操作步骤如下
- 通过初始化参数G1, T1即可获取该参数下的图像亮度Y1;就有
- 那么对于目标亮度就有对应的参数G2和T2,同理瞒住公式:
- 对上面两公式化简可得:
- 进一步归纳公式:
- 公式左侧, , , , 均为已知,那么新的曝光参数的乘积就是一个已知量
- 论文中给出的方式就是先确定一个 值,然后根据公式求出 的值,然后对求出来的值取整,得到最终的
- 根据最终的 的值再反过来求出 的值;,而且
- 理论上只需一帧就可以调整到合适曝光参数
- 对于第6步中先确定的 的值来说,因为增加gain对增加信息量没有作用,而且通过gain值增加亮度还会导致噪声变大,所以这篇论文中给出gain的取值范围为1-2,所以对于第六步其实可以默认 为1,然后求出一个T,然后判断T是否超过最大曝光时间,如果没有就继续上面的步骤,如果超过了既可以用最大曝光时间算出一个gain,然后判断这个gain时候超过2,如果没有就确定了一组参数,如果超过就取gain为2接着计算T也能得到一组新的参数。